
{kind=link}

Picture generated with Segmind SSD-1B Mannequin
While you’re analyzing information with pandas, you’ll use pandas features for filtering and remodeling the columns, becoming a member of information from a number of dataframes, and the like.
However it may usually be useful to generate plots—to visualise the info within the dataframe—relatively than simply wanting on the numbers.
Pandas has a number of plotting features you should use for fast and simple information visualization. And we’ll go over them on this tutorial.
🔗 Hyperlink to Google Colab pocket book (if you happen to’d prefer to code alongside).
Let’s create a pattern dataframe for evaluation. We’ll create a dataframe referred to as df_employees containing worker data.
We’ll use Faker and the NumPy’s random module to populate the dataframe with 200 data.
Word: If you do not have Faker put in in your growth atmosphere, you possibly can set up it utilizing pip: pip set up Faker.
Run the next snippet to create and populate df_employees with data:
import pandas as pd
from faker import Faker
import numpy as np
# Instantiate Faker object
pretend = Faker()
Faker.seed(27)
# Create a DataFrame for workers
num_employees = 200
departments = ['Engineering', 'Finance', 'HR', 'Marketing', 'Sales', 'IT']
years_with_company = np.random.randint(1, 10, dimension=num_employees)
wage = 40000 + 2000 * years_with_company * np.random.randn()
employee_data = {
'EmployeeID': np.arange(1, num_employees + 1),
'FirstName': [fake.first_name() for _ in range(num_employees)],
'LastName': [fake.last_name() for _ in range(num_employees)],
'Age': np.random.randint(22, 60, dimension=num_employees),
'Division': [fake.random_element(departments) for _ in range(num_employees)],
'Wage': np.spherical(wage),
'YearsWithCompany': years_with_company
}
df_employees = pd.DataFrame(employee_data)
# Show the top of the DataFrame
df_employees.head(10)
We’ve set the seed for reproducibility. So each time you run this code, you’ll get the identical data.
Listed below are the primary view data of the dataframe:
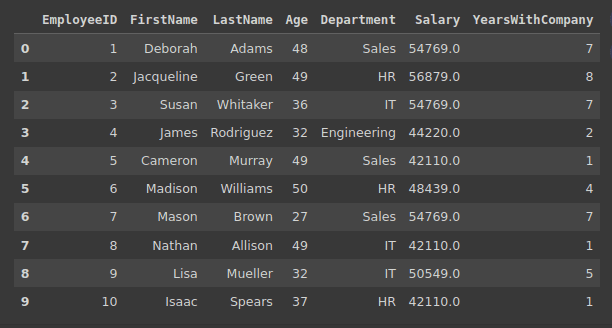
Output of df_employees.head(10)
Scatter plots are typically used to know the connection between any two variables within the dataset.
For the df_employees dataframe, let’s create a scatter plot to visualise the connection between the age of the worker and the wage. This may assist us perceive if there’s any correlation between the ages of the staff and their salaries.
To create a scatter plot, we are able to use plot.scatter() like so:
# Scatter Plot: Age vs Wage
df_employees.plot.scatter(x='Age', y='Wage', title="Scatter Plot: Age vs Wage", xlabel="Age", ylabel="Wage", grid=True)
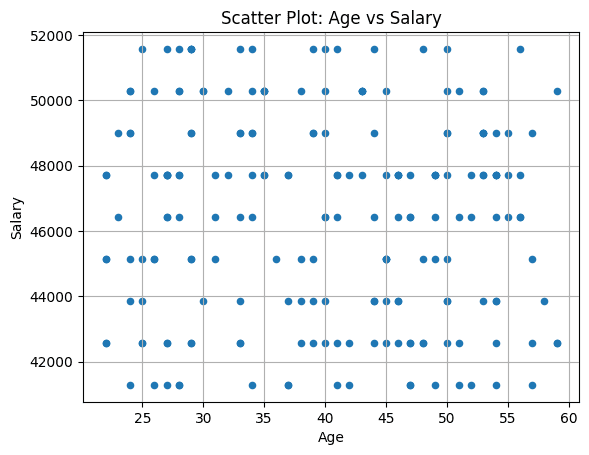
For this instance dataframe, we don’t see any correlation between the age of the staff and the salaries.
A line plot is appropriate for figuring out tendencies and patterns over a steady variable which is often time or the same scale.
When creating the df_employees dataframe, we had outlined a linear relationship between the variety of years an worker has labored with the corporate and their wage. So let’s take a look at the road plot exhibiting how the common salaries range with the variety of years.
We discover the common wage grouped by the years with firm, after which create a line plot with plot.line():
# Line Plot: Common Wage Pattern Over Years of Expertise
average_salary_by_experience = df_employees.groupby('YearsWithCompany')['Salary'].imply()
df_employees['AverageSalaryByExperience'] = df_employees['YearsWithCompany'].map(average_salary_by_experience)
df_employees.plot.line(x='YearsWithCompany', y='AverageSalaryByExperience', marker="o", linestyle="-", title="Common Wage Pattern Over Years of Expertise", xlabel="Years With Firm", ylabel="Common Wage", legend=False, grid=True)
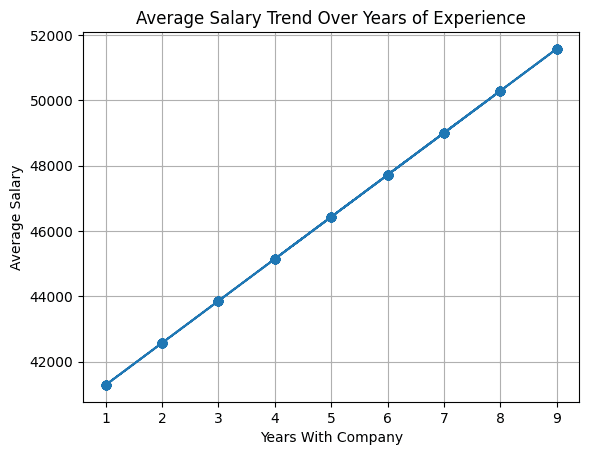
As a result of we select to populate the wage area utilizing a linear relationship to the variety of years an worker has labored on the firm, we see that the road plot displays that.
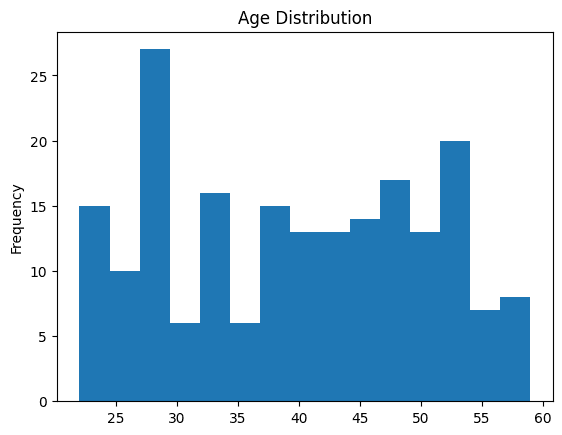
You need to use histograms to visualise the distribution of steady variables—by dividing the values into intervals or bins—and displaying the variety of information factors in every bin.
Let’s perceive the distribution of ages of the staff utilizing a histogram utilizing plot.hist() as proven:
# Histogram: Distribution of Ages
df_employees['Age'].plot.hist(title="Age Distribution", bins=15)
A field plot is useful in understanding the distribution of a variable, its unfold, and for figuring out outliers.
Let’s create a field plot to match the distribution of salaries throughout totally different departments—giving a high-level comparability of wage distribution inside the group.
Field plot will even assist determine the wage vary in addition to helpful info such because the median wage and potential outliers for every division.
Right here, we use boxplot of the ‘Wage’ column grouped by ‘Division’:
# Field Plot: Wage distribution by Division
df_employees.boxplot(column='Wage', by='Division', grid=True, vert=False)
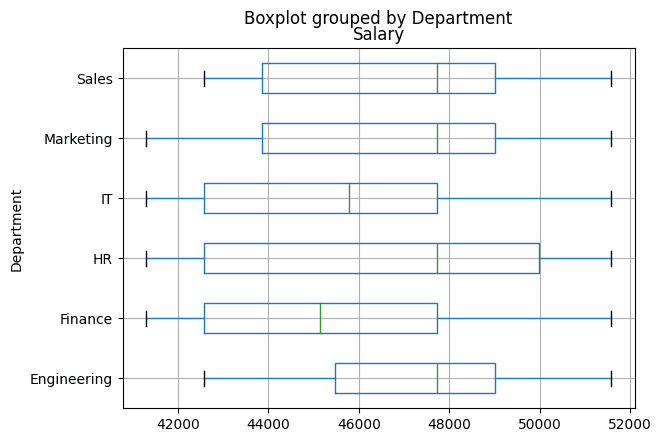
From the field plot, we see that some departments have a larger unfold of salaries than others.
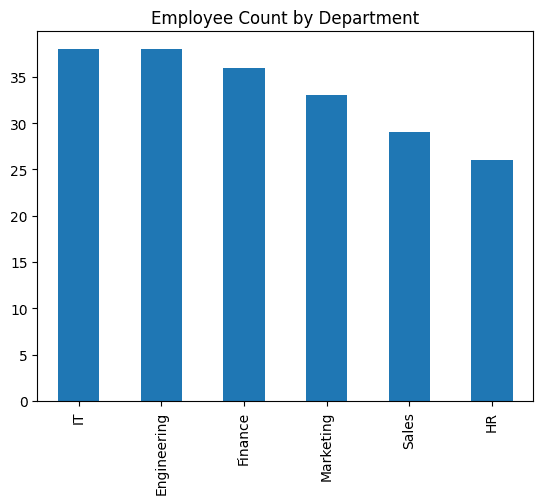
While you need to perceive the distribution of variables when it comes to frequency of prevalence, you should use a bar plot.
Now let’s create a bar plot utilizing plot.bar() to visualise the variety of staff:
# Bar Plot: Division-wise worker depend
df_employees['Department'].value_counts().plot.bar(title="Worker Depend by Division")
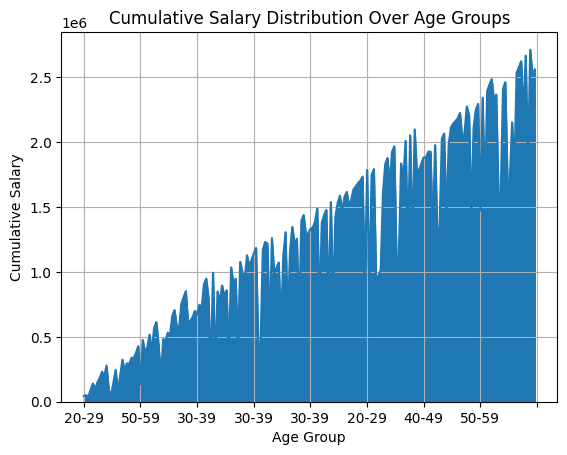
Space plots are typically used for visualizing the cumulative distribution of a variable over the continual or categorical axis.
For the staff dataframe, we are able to plot the cumulative wage distribution over totally different age teams. To map the staff into bins primarily based on age group, we use pd.minimize().
We then discover the cumulative sum of the salaries group the wage by ‘AgeGroup’. To get the world plot, we use plot.space():
# Space Plot: Cumulative Wage Distribution Over Age Teams
df_employees['AgeGroup'] = pd.minimize(df_employees['Age'], bins=[20, 30, 40, 50, 60], labels=['20-29', '30-39', '40-49', '50-59'])
cumulative_salary_by_age_group = df_employees.groupby('AgeGroup')['Salary'].cumsum()
df_employees['CumulativeSalaryByAgeGroup'] = cumulative_salary_by_age_group
df_employees.plot.space(x='AgeGroup', y='CumulativeSalaryByAgeGroup', title="Cumulative Wage Distribution Over Age Teams", xlabel="Age Group", ylabel="Cumulative Wage", legend=False, grid=True)
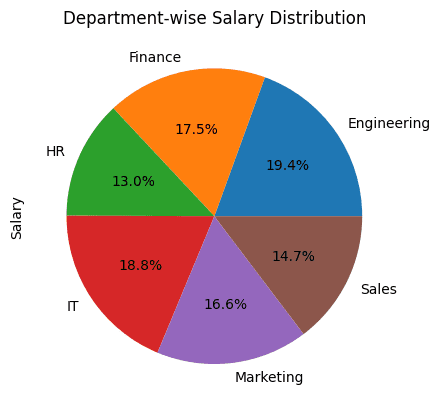
Pie Charts are useful while you need to visualize the proportion of every of the classes inside a complete.
For our instance, it is smart to create a pie chart that shows the distribution of salaries throughout departments inside the group.
We discover the entire wage of the staff grouped by the division. After which use plot.pie() to plot the pie chart:
# Pie Chart: Division-wise Wage distribution
df_employees.groupby('Division')['Salary'].sum().plot.pie(title="Division-wise Wage Distribution", autopct="%1.1f%%")
I hope you discovered a number of useful plotting features you should use in pandas.
Sure, you possibly can generate a lot prettier plots with matplotlib and seaborn. However for fast information visualization, these features will be tremendous helpful.
What are a few of the different pandas plotting features that you simply use usually? Tell us within the feedback.
Bala Priya C is a developer and technical author from India. She likes working on the intersection of math, programming, information science, and content material creation. Her areas of curiosity and experience embrace DevOps, information science, and pure language processing. She enjoys studying, writing, coding, and low! At present, she’s engaged on studying and sharing her data with the developer group by authoring tutorials, how-to guides, opinion items, and extra.