

{kind=link}
These days, many individuals learn audiobooks as an alternative of books or different media. Audiobooks not solely let present readers take pleasure in data whereas on the street, however they might additionally assist make content material accessible to teams, together with youngsters, the visually impaired, and anybody studying a brand new language. Conventional audiobook manufacturing methods take money and time and may end up in various recording high quality, comparable to skilled human narration or volunteer-driven initiatives like LibriVox. Attributable to these points, maintaining with the rising variety of printed books takes effort and time.
Nevertheless, automated audiobook creation has traditionally suffered as a result of robotic nature of text-to-speech techniques and the problem in deciding what textual content shouldn’t be learn aloud (comparable to tables of contents, web page numbers, figures, and footnotes). They supply a technique for overcoming the abovementioned difficulties by creating high-quality audiobooks from numerous on-line e-book collections. Their strategy particularly incorporates current developments in neural text-to-speech, expressive studying, scalable computation, and automatic recognition of pertinent content material to supply hundreds of natural-sounding audiobooks.
They contribute over 5,000 audiobooks price of speech, totaling over 35,000 hours, to the open supply. Additionally they present demonstration software program that permits convention members to make their audiobooks by studying any e book from the library aloud of their voices utilizing solely a short pattern of sound. This work introduces a scalable methodology for changing HTML-based e-books to wonderful audiobooks. SynapseML, a scalable machine studying platform that permits distributed orchestration of the entire audiobook technology course of, is the muse for his or her pipeline. Their distribution chain begins with hundreds of Venture Gutenberg-provided free e-books. They deal largely with the HTML format of those e-books because it lends itself to automated parsing, the very best of all of the accessible codecs for these publications.
Consequently, we may set up and visualize the whole assortment of Venture Gutenberg HTML pages and establish many sizable teams of equally structured recordsdata. The key lessons of e-books have been remodeled into an ordinary format that might be mechanically processed utilizing a rule-based HTML normalizer created utilizing these collections of HTML recordsdata. Because of this strategy, we developed a system that might swiftly and deterministically parse an enormous variety of books. Most importantly, it allowed us to give attention to the recordsdata that might end in high-quality recordings when learn.
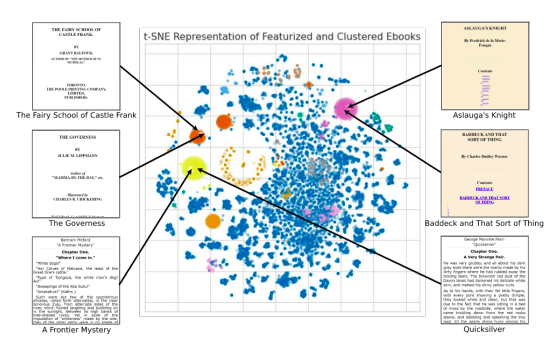
The outcomes of this strategy for clustering are proven in Determine 1, which illustrates how numerous teams of equally organized digital books spontaneously come up within the Venture Gutenberg assortment. After processing, a plain textual content stream could also be extracted and fed into text-to-speech algorithms. There are lots of studying methods required for numerous audiobooks. A transparent, goal voice is greatest for nonfiction, whereas an expressive studying and slightly “appearing” are higher for fiction with dialogue. Nevertheless, of their stay demonstration, they are going to present clients the choice to change the textual content’s voice, tempo, pitch, and intonation. For the majority of the books, they make the most of a transparent and impartial neural text-to-speech voice.
They use zero-shot text-to-speech methods to switch the voice successfully options from a small variety of enrolled recordings to duplicate a person’s voice. By doing this, a person could quickly produce an audiobook of their voice, using only a tiny little bit of audio that has been captured. They make use of an automatic speaker and emotion inference system to dynamically alter the studying voice and tone based mostly on context to supply an emotional textual content studying. This enhances the lifelikeness and curiosity of sequences with a number of individuals and dynamic interplay.
To do that, they first divide the textual content into narrative and dialog, designating a special speaker for every line of dialogue. Then, self-supervised, they predict every dialogue’s emotional tone. Lastly, they use the multi-style and contextual-based neural text-to-speech mannequin launched to assign distinct voices and feelings to the narrator and the character conversations. They suppose this strategy may considerably improve the provision and accessibility of audiobooks.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Venture. Additionally, don’t neglect to affix our 30k+ ML SubReddit, 40k+ Fb Group, Discord Channel, and Electronic mail Publication, the place we share the newest AI analysis information, cool AI initiatives, and extra.
For those who like our work, you’ll love our e-newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing initiatives.