

{kind=link}
Pure language processing (NLP) has revolutionized due to self-attention, the transformer design’s key aspect, permitting the mannequin to acknowledge intricate connections inside enter sequences. Self-attention provides numerous elements of the enter sequence different quantities of precedence by evaluating the related token’s relevance to one another. The opposite method has proven to be superb at capturing long-range relationships, which is necessary for reinforcement studying, pc imaginative and prescient, and NLP purposes. Self-attention mechanisms and transformers have achieved outstanding success, clearing the trail for creating advanced language fashions like GPT4, Bard, LLaMA, and ChatGPT.
Can they describe the implicit bias of transformers and the optimization panorama? How does the eye layer select and mix tokens when skilled with gradient descent? Researchers from the College of Pennsylvania, the College of California, the College of British Columbia, and the College of Michigan reply these issues by rigorously tying collectively the eye layer’s optimization geometry with the (Att-SVM) laborious max-margin SVM downside, which separates and chooses the very best tokens from every enter sequence. Experiments present that this formalism, which builds on earlier work, is virtually important and illuminates the nuances of self-attention.
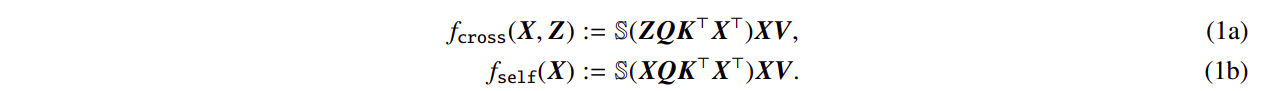
All through, they examine the basic cross-attention and self-attention fashions utilizing enter sequences X, Z ∈ RT×d with size T and embedding dimension d: Right here, the trainable key, question, and worth matrices are Ok, Q ∈ Rd×m, and V ∈ Rd×v respectively. S( . ) stands for the softmax nonlinearity, which is utilized row-wise to XQK⊤X⊤. By setting Z ← X, it may be seen that self-attention (1b) is a novel case of crossattention (1a). Think about using the preliminary token of Z, represented by z, for prediction to disclose their main findings.
Particularly, they deal with the empirical threat minimization with a reducing loss perform l(): R R, expressed as follows: Given a coaching dataset (Yi, Xi, zi)ni=1 with labels Yi ∈ {−1, 1} and inputs Xi ∈ RT×d, zi ∈ Rd, they consider the next: The prediction head on this case, denoted by the image h( . ), consists of the worth weights V. On this formulation, an MLP follows the eye layer within the mannequin f( . ), which precisely depicts a one-layer transformer. The self-attention is restored in (2) by setting zi ← xi1, the place xi1 designates the primary token of the sequence Xi. On account of its nonlinear character, the softmax operation presents a substantial hurdle for optimizing (2).

The problem is nonconvex and nonlinear, even when the prediction head is mounted and linear. This work optimizes the eye weights (Ok, Q, or W) to beat these difficulties and set up a fundamental SVM equivalence.
The next are the paper’s key contributions:
• The layer’s implicit bias in consideration. With the nuclear norm purpose of the mix parameter W:= KQ (Thm 2), optimizing the eye parameters (Ok, Q) with diminishing regularisation converges within the route of a max-margin resolution of (Att-SVM). The regularisation path (RP) directionally converges to the (Att-SVM) resolution with the Frobenius norm goal when cross-attention is explicitly parameterized by the mix parameter W. To their information, that is the primary research that formally compares the optimization dynamics of (Ok, Q) parameterizations to these of (W) parameterizations, highlighting the latter’s low-rank bias. Theorem 11 and SAtt-SVM within the appendix describe how their idea simply extends to sequence-to-sequence or causal categorization contexts and clearly defines the optimality of chosen tokens.
• Gradient descent convergence. With the correct initialization and a linear head h(), the gradient descent iterations for the mixed key-query variable W converge within the route of an Att-SVM resolution that’s regionally optimum. Chosen tokens should carry out higher than their surrounding tokens for native optimality. Domestically optimum guidelines are outlined within the following downside geometry, though they aren’t all the time distinctive. They considerably contribute by figuring out the geometric parameters that guarantee convergence to the globally optimum route. These embrace (i) the power to distinguish preferrred tokens primarily based on their scores or (ii) the alignment of the preliminary gradient route with optimum tokens. Past these, they exhibit how over-parameterization (i.e., dimension d being massive and equal situations) promotes world convergence by guaranteeing (Att-SVM) feasibility and (benign) optimization panorama, which suggests there aren’t any stationary factors and no fictitious regionally optimum instructions.
• The SVM equivalence’s generality. The eye layer, typically referred to as laborious consideration when optimizing with linear h(), is intrinsically biased in the direction of selecting one token from every sequence. On account of the output tokens being convex combos of the enter tokens, that is mirrored within the (Att-SVM).
They exhibit, nevertheless, that nonlinear heads want the creation of a number of tokens, underscoring the importance of those parts to the dynamics of the transformer. They recommend a extra broad SVM equivalency by concluding their idea. Surprisingly, they present that their speculation appropriately predicts the implicit bias of consideration skilled by gradient descent underneath broad situations not addressed by strategy (for instance, h() being an MLP). Their basic equations particularly dissociate consideration weights into two parts: a finite part figuring out the exact composition of the chosen phrases by modifying the softmax possibilities and a directional part managed by SVM that picks the tokens by making use of a 0-1 masks.
The truth that these outcomes may be mathematically verified and utilized to any dataset (at any time when SVM is sensible) is a key side of them. Via insightful experiments, they comprehensively affirm the max-margin equivalence and implicit bias of transformers. They imagine that these outcomes contribute to our information of transformers as hierarchical max-margin token choice processes, and so they anticipate that their findings will present a strong foundation for future analysis on the optimization and generalization dynamics of transformers.
Take a look at the Paper. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t overlook to affix our 30k+ ML SubReddit, 40k+ Fb Neighborhood, Discord Channel, and E-mail E-newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
When you like our work, you’ll love our publication..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with folks and collaborate on fascinating initiatives.