
{kind=link}
Machine studying fashions have turn into an integral part of decision-making throughout a number of industries, but they typically encounter problem when coping with noisy or numerous information units. That’s the place Ensemble Studying comes into play.
This text will demystify ensemble studying and introduce you to its highly effective random forest algorithm. Regardless of in case you are an information scientist seeking to hone your toolkit or a developer on the lookout for sensible insights into constructing sturdy machine studying fashions, this piece is supposed for everybody!
By the top of this text, you’ll acquire an intensive data of Ensemble Studying and the way Random Forests in Python work. So whether or not you’re an skilled information scientist or just curious to develop your machine-learning talents, be a part of us on this journey and advance your machine-learning experience!
Ensemble studying is a machine studying strategy during which predictions from a number of weak fashions are mixed with one another to get stronger predictions. The idea behind ensemble studying is lowering the bias and errors from single fashions by leveraging the predictive energy of every mannequin.
To have a greater instance let’s take a life instance think about that you’ve got seen an animal and also you have no idea what species this animal belongs to. So as an alternative of asking one professional, you ask ten specialists and you’ll take the vote of nearly all of them. This is named arduous voting.
Exhausting voting is once we consider the category predictions for every classifier after which classify an enter primarily based on the utmost votes to a specific class. Then again, gentle voting is once we consider the chance predictions for every class by every classifier after which classify an enter to the category with most chance primarily based on the common chance (averaged over the classifier’s chances) for that class.
Ensemble studying is at all times used to enhance the mannequin efficiency which incorporates bettering the classification accuracy and lowering the imply absolute error for regression fashions. Along with this ensemble learners at all times yield a extra secure mannequin. Ensemble learners work at their finest when the fashions will not be correlated then each mannequin can be taught one thing distinctive and work on bettering the general efficiency.
Though ensemble studying might be utilized in some ways, nonetheless on the subject of making use of it to apply there are three methods which have gained numerous reputation on account of their straightforward implementation and utilization. These three methods are:
- Bagging: Bagging which is brief for bootstrap aggregation is an ensemble studying technique during which the fashions are skilled utilizing random samples of the information set.
- Stacking: Stacking which is brief for stacked generalization is an ensemble studying technique during which we practice a mannequin to mix a number of fashions skilled on our information.
- Boosting: Boosting is an ensemble studying approach that focuses on deciding on the misclassified information to coach the fashions on.
Let’s dive deeper into every of those methods and see how we will use Python to coach these fashions on our dataset.
Bagging takes random samples of information, and makes use of studying algorithms and the imply to search out bagging chances; often known as bootstrap aggregating; it aggregates outcomes from a number of fashions to get one broad consequence.
This strategy includes:
- Splitting the unique dataset into a number of subsets with alternative.
- Develop base fashions for every of those subsets.
- Working all fashions concurrently earlier than operating all predictions via to acquire closing predictions.
Scikit-learn offers us with the power to implement each a BaggingClassifier and BaggingRegressor. A BaggingMetaEstimator identifies random subsets of an unique dataset to suit every base mannequin, then aggregates particular person base mannequin predictions?—?both via voting or averaging?—?right into a closing prediction by aggregating particular person base mannequin predictions into an mixture prediction utilizing voting or averaging. This technique reduces variance by randomizing their development course of.
Let’s take an instance during which we use the bagging estimator utilizing scikit be taught:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=10, max_samples=0.5, max_features=0.5)
The bagging classifier takes into consideration a number of parameters:
- base_estimator: The bottom mannequin used within the bagging strategy. Right here we use the choice tree classifier.
- n_estimators: The variety of estimators we are going to use within the bagging strategy.
- max_samples: The variety of samples that will probably be drawn from the coaching set for every base estimator.
- max_features: The variety of options that will probably be used to coach every base estimator.
Now we are going to match this classifier on the coaching set and rating it.
bagging.match(X_train, y_train)
bagging.rating(X_test,y_test)
We will do the identical for regression duties, the distinction will probably be that we’ll be utilizing regression estimators as an alternative.
from sklearn.ensemble import BaggingRegressor
bagging = BaggingRegressor(DecisionTreeRegressor())
bagging.match(X_train, y_train)
mannequin.rating(X_test,y_test)
Stacking is a way for combining a number of estimators to be able to reduce their biases and produce correct predictions. Predictions from every estimator are then mixed and fed into an final prediction meta-model skilled via cross-validation; stacking might be utilized to each classification and regression issues.
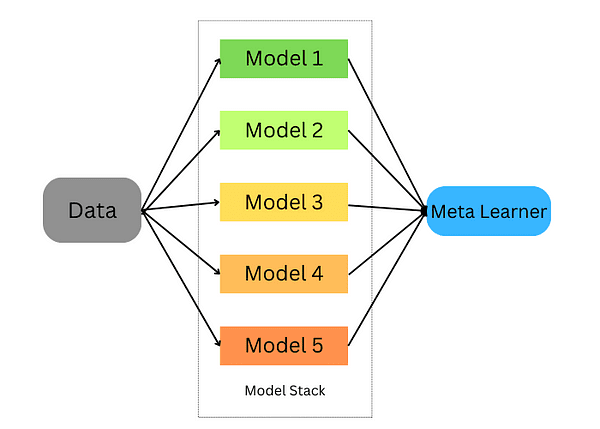
Stacking ensemble studying
Stacking happens within the following steps:
- Break up the information right into a coaching and validation set
- Divide the coaching set into Okay folds
- Prepare a base mannequin on k-1 folds and make predictions on the k-th fold
- Repeat till you will have a prediction for every fold
- Match the bottom mannequin on the entire coaching set
- Use the mannequin to make predictions on the take a look at set
- Repeat steps 3–6 for different base fashions
- Use predictions from the take a look at set as options of a brand new mannequin (the meta mannequin)
- Make closing predictions on the take a look at set utilizing the meta-model
On this instance under, we start by creating two base classifiers (RandomForestClassifier and GradientBoostingClassifier) and one meta-classifier (LogisticRegression) and use Okay-fold cross-validation to make use of predictions from these classifiers on coaching information (iris dataset) for enter options for our meta-classifier (LogisticRegression).
After utilizing Okay-fold cross-validation to make predictions from the bottom classifiers on take a look at information units as enter options for our meta-classifier, predictions on take a look at units utilizing each units collectively and consider their accuracy towards their stacked ensemble counterparts.
# Load the dataset
information = load_iris()
X, y = information.information, information.goal
# Break up the information into coaching and testing units
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Outline base classifiers
base_classifiers = [
RandomForestClassifier(n_estimators=100, random_state=42),
GradientBoostingClassifier(n_estimators=100, random_state=42)
]
# Outline a meta-classifier
meta_classifier = LogisticRegression()
# Create an array to carry the predictions from base classifiers
base_classifier_predictions = np.zeros((len(X_train), len(base_classifiers)))
# Carry out stacking utilizing Okay-fold cross-validation
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.cut up(X_train):
train_fold, val_fold = X_train[train_index], X_train[val_index]
train_target, val_target = y_train[train_index], y_train[val_index]
for i, clf in enumerate(base_classifiers):
cloned_clf = clone(clf)
cloned_clf.match(train_fold, train_target)
base_classifier_predictions[val_index, i] = cloned_clf.predict(val_fold)
# Prepare the meta-classifier on base classifier predictions
meta_classifier.match(base_classifier_predictions, y_train)
# Make predictions utilizing the stacked ensemble
stacked_predictions = np.zeros((len(X_test), len(base_classifiers)))
for i, clf in enumerate(base_classifiers):
stacked_predictions[:, i] = clf.predict(X_test)
# Make closing predictions utilizing the meta-classifier
final_predictions = meta_classifier.predict(stacked_predictions)
# Consider the stacked ensemble's efficiency
accuracy = accuracy_score(y_test, final_predictions)
print(f"Stacked Ensemble Accuracy: {accuracy:.2f}")
Boosting is a machine studying ensemble approach that reduces bias and variance by turning weak learners into sturdy learners. These weak learners are utilized sequentially to the dataset; firstly by creating an preliminary mannequin and becoming it to the coaching set. As soon as errors from the primary mannequin have been recognized, one other mannequin is designed to appropriate them.
There are well-liked algorithms and implementations for enhancing ensemble studying strategies. Let’s discover essentially the most well-known ones.
6.1. AdaBoost
AdaBoost is an efficient ensemble studying approach, that employs weak learners sequentially for coaching functions. Every iteration prioritizes incorrect predictions whereas lowering weight assigned to accurately predicted situations; this strategic emphasis on difficult observations compels AdaBoost to turn into more and more correct over time, with its final prediction decided by aggregating majority votes or weighted sum of its weak learners.
AdaBoost is a flexible algorithm appropriate for each regression and classification duties, however right here we give attention to its utility to classification issues utilizing Scikit-learn. Let’s take a look at how we will use it for classification duties within the instance under:
from sklearn.ensemble import AdaBoostClassifier
mannequin = AdaBoostClassifier(n_estimators=100)
mannequin.match(X_train, y_train)
mannequin.rating(X_test,y_test)
On this instance, we used the AdaBoostClassifier from scikit be taught and set the n_estimators to 100. The default be taught is a call tree and you may change it. Along with this, the parameters of the choice tree might be tuned.
2. EXtreme Gradient Boosting (XGBoost)
eXtreme Gradient Boosting or is extra popularly often known as XGBoost, is among the finest implementations of boosting ensemble learners on account of its parallel computations which makes it very optimized to run on a single laptop. XGBoost is offered to make use of via the xgboost package deal developed by the machine studying group.
import xgboost as xgb
params = {"goal":"binary:logistic",'colsample_bytree': 0.3,'learning_rate': 0.1,
'max_depth': 5, 'alpha': 10}
mannequin = xgb.XGBClassifier(**params)
mannequin.match(X_train, y_train)
mannequin.match(X_train, y_train)
mannequin.rating(X_test,y_test)
3. LightGBM
LightGBM is one other gradient-boosting algorithm that’s primarily based on tree studying. Nevertheless, it’s not like different tree-based algorithms in that it makes use of leaf-wise tree progress which makes it converge quicker.
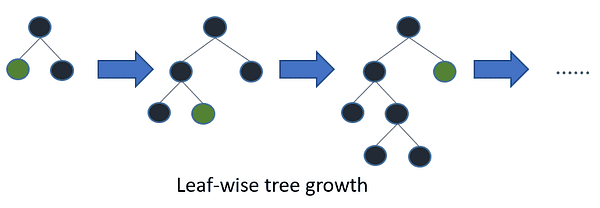
Leaf-wise tree progress / Picture by LightGBM
Within the instance under we are going to apply LightGBM to a binary classification downside:
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt',
'goal': 'binary',
'num_leaves': 40,
'learning_rate': 0.1,
'feature_fraction': 0.9
}
gbm = lgb.practice(params,
lgb_train,
num_boost_round=200,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train','valid'],
)
Ensemble studying and random forests are highly effective machine studying fashions which can be at all times utilized by machine studying practitioners and information scientists. On this article, we coated the fundamental instinct behind them, when to make use of them, and eventually, we coated the most well-liked algorithms of them and find out how to use them in Python.
Youssef Rafaat is a pc imaginative and prescient researcher & information scientist. His analysis focuses on creating real-time laptop imaginative and prescient algorithms for healthcare functions. He additionally labored as an information scientist for greater than 3 years within the advertising, finance, and healthcare area.