

{kind=link}
Important progress has been noticed within the improvement of diffusion fashions for numerous picture synthesis duties within the area of pc imaginative and prescient. Prior analysis has illustrated the applicability of the diffusion prior, built-in into synthesis fashions like Secure Diffusion, to a spread of downstream content material creation duties, together with picture and video enhancing.
On this article, the investigation expands past content material creation and explores the potential benefits of using diffusion priors for super-resolution (SR) duties. Tremendous-resolution, a low-level imaginative and prescient process, introduces an extra problem because of its demand for top picture constancy, which contrasts with the inherent stochastic nature of diffusion fashions.
A typical answer to this problem entails coaching a super-resolution mannequin from the bottom up. These strategies incorporate the low-resolution (LR) picture as an extra enter to constrain the output area, aiming to protect constancy. Whereas these approaches have achieved commendable outcomes, they usually require substantial computational sources for coaching the diffusion mannequin. Moreover, initiating community coaching from scratch can doubtlessly compromise the generative priors captured in synthesis fashions, doubtlessly resulting in suboptimal community efficiency.
In response to those limitations, another method has been explored. This various entails introducing constraints into the reverse diffusion technique of a pre-trained synthesis mannequin. This paradigm eliminates the necessity for intensive mannequin coaching whereas leveraging the advantages of the diffusion prior. Nonetheless, it’s value noting that designing these constraints assumes prior data of the picture degradations, which is usually each unknown and complicated. Consequently, such strategies reveal restricted generalizability.
To handle the talked about limitations, the researchers introduce StableSR, an method designed to retain pre-trained diffusion priors with out requiring specific assumptions about picture degradations. An outline of the introduced approach is illustrated under.
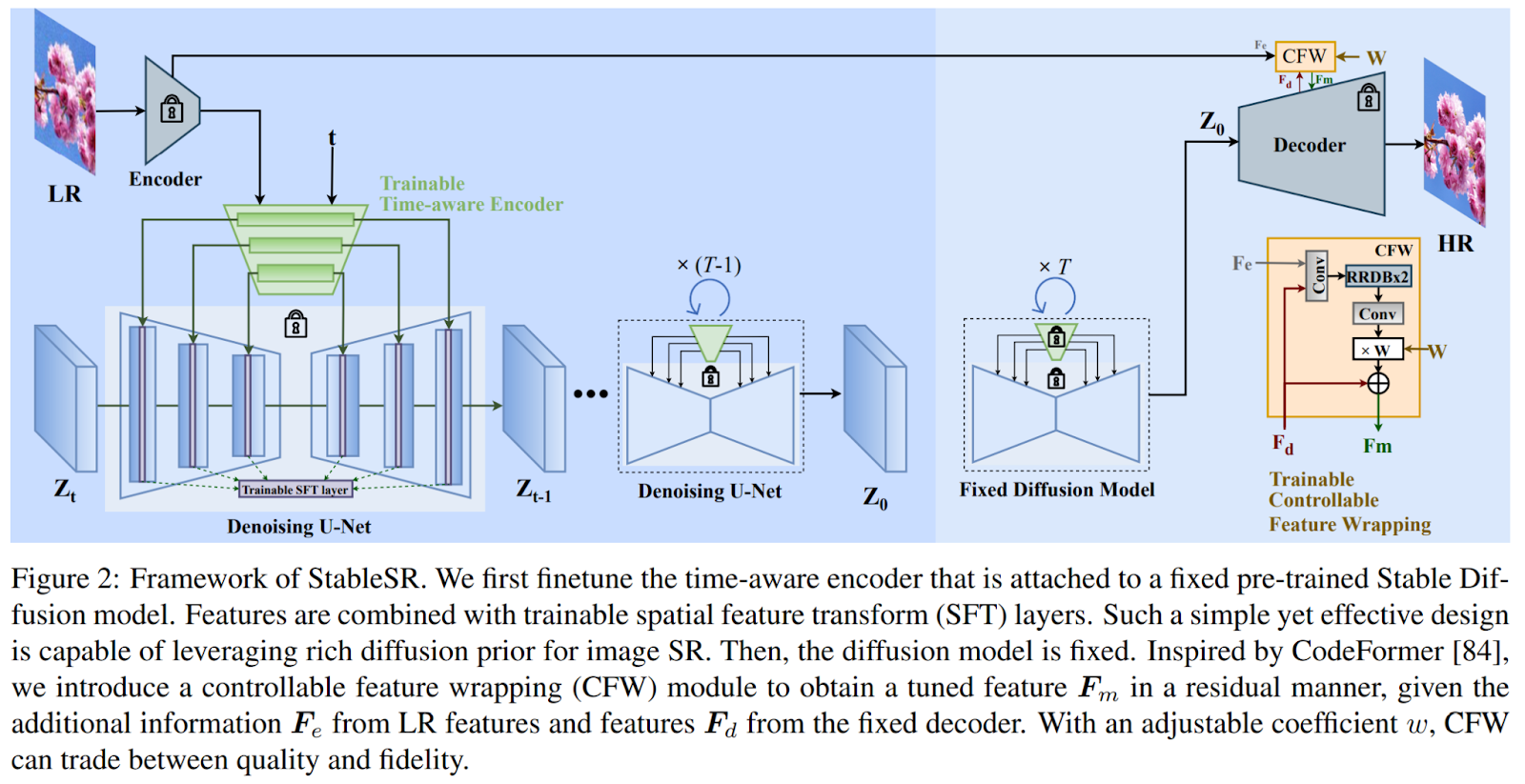
In distinction to prior approaches that concatenate the low-resolution (LR) picture with intermediate outputs, necessitating the coaching of a diffusion mannequin from scratch, StableSR entails fine-tuning a light-weight time-aware encoder and some function modulation layers particularly tailor-made for super-resolution (SR) duties.
The encoder incorporates a time embedding layer to generate time-aware options, enabling adaptive modulation of options throughout the diffusion mannequin at totally different iterations. This not solely enhances coaching effectivity but in addition maintains the integrity of the generative prior. Moreover, the time-aware encoder gives adaptive steerage through the restoration course of, with stronger steerage at earlier iterations and weaker steerage at later levels, contributing considerably to improved efficiency.
To handle the inherent randomness of the diffusion mannequin and mitigate data loss through the encoding technique of the autoencoder, StableSR applies a controllable function wrapping module. This module introduces an adjustable coefficient to refine the outputs of the diffusion mannequin through the decoding course of, utilizing multi-scale intermediate options from the encoder in a residual method. The adjustable coefficient permits for a steady trade-off between constancy and realism, accommodating a variety of degradation ranges.
Moreover, adapting diffusion fashions for super-resolution duties at arbitrary resolutions has traditionally posed challenges. To beat this, StableSR introduces a progressive aggregation sampling technique. This method divides the picture into overlapping patches and fuses them utilizing a Gaussian kernel at every diffusion iteration. The result’s a smoother transition at boundaries, making certain a extra coherent output.
Some output samples of StableSR introduced within the authentic article in contrast with state-of-the-art approaches are reported within the determine under.

In abstract, StableSR gives a novel answer for adapting generative priors to real-world picture super-resolution challenges. This method leverages pre-trained diffusion fashions with out making specific assumptions about degradations, addressing problems with constancy and arbitrary decision via the incorporation of the time-aware encoder, controllable function wrapping module, and progressive aggregation sampling technique. StableSR serves as a strong baseline, inspiring future analysis within the software of diffusion priors for restoration duties.
In case you are and wish to study extra about it, please be at liberty to consult with the hyperlinks cited under.
Try the Paper, Github, and Undertaking Web page. All Credit score For This Analysis Goes To the Researchers on This Undertaking. Additionally, don’t overlook to affix our 30k+ ML SubReddit, 40k+ Fb Neighborhood, Discord Channel, and E-mail Publication, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Should you like our work, you’ll love our publication..
Daniele Lorenzi acquired his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Data Know-how (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s presently working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embody adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.