

{kind=link}
Do you know that whereas the Ahrefs Weblog is powered by WordPress, a lot of the remainder of the positioning is powered by JavaScript like React?
The truth of the present net is that JavaScript is in all places. Most web sites use some sort of JavaScript so as to add interactivity and enhance consumer expertise.
But many of the JavaScript used on so many web sites gained’t affect search engine marketing in any respect. When you’ve got a standard WordPress set up with out quite a lot of customization, then seemingly not one of the points will apply to you.
The place you’ll run into points is when JavaScript is used to construct a complete web page, add or take away parts, or change what was already on the web page. Some websites use it for menus, pulling in merchandise or costs, grabbing content material from a number of sources or, in some instances, for all the pieces on the positioning. If this feels like your website, maintain studying.
We’re seeing total techniques and apps constructed with JavaScript frameworks and even some conventional CMSes with a JavaScript aptitude the place they’re headless or decoupled. The CMS is used because the backend supply of information, however the frontend presentation is dealt with by JavaScript.
I’m not saying that SEOs have to exit and learn to program JavaScript. I really don’t suggest it as a result of it’s unlikely that you’ll ever contact the code. What SEOs have to know is how Google handles JavaScript and learn how to troubleshoot points.
JavaScript search engine marketing is part of technical search engine marketing (SEO) that makes JavaScript-heavy web sites straightforward to crawl and index, in addition to search-friendly. The aim is to have these web sites be discovered and rank larger in search engines like google.
JavaScript shouldn’t be unhealthy for search engine marketing, and it’s not evil. It’s simply completely different from what many SEOs are used to, and there’s a little bit of a studying curve.
A whole lot of the processes are just like issues SEOs are already used to seeing, however there could also be slight variations. You’re nonetheless going to be largely HTML code, not really JavaScript.
All the traditional on-page search engine marketing finest practices nonetheless apply. See our information on on-page search engine marketing.
You’ll even discover acquainted plugin-type choices to deal with quite a lot of the essential search engine marketing parts, if it’s not already constructed into the framework you’re utilizing. For JavaScript frameworks, these are known as modules, and also you’ll discover a lot of package deal choices to put in them.
There are variations for lots of the widespread frameworks like React, Vue, Angular, and Svelte that you could find by trying to find the framework + module title like “React Helmet.” Meta tags, Helmet, and Head are all widespread modules with related performance and permit for lots of the widespread tags wanted for search engine marketing to be set.
In some methods, JavaScript is healthier than conventional HTML, resembling ease of constructing and efficiency. In some methods, JavaScript is worse, resembling it might’t be parsed progressively (like HTML and CSS could be), and it may be heavy on web page load and efficiency. Typically, you could be buying and selling efficiency for performance.
JavaScript isn’t excellent, and it isn’t at all times the suitable instrument for the job. Builders do overuse it for issues the place there’s most likely a greater resolution. However typically, it’s a must to work with what you might be given.
These are lots of the frequent search engine marketing points you could run into when working with JavaScript websites.
Have distinctive title tags and meta descriptions
You’re nonetheless going to need to have distinctive title tags and meta descriptions throughout your pages. As a result of quite a lot of the JavaScript frameworks are templatized, you possibly can simply find yourself in a state of affairs the place the identical title or meta description is used for all pages or a bunch of pages.
Test the Duplicates report in Ahrefs’ Web site Audit and click on into any of the groupings to see extra information in regards to the points we discovered.
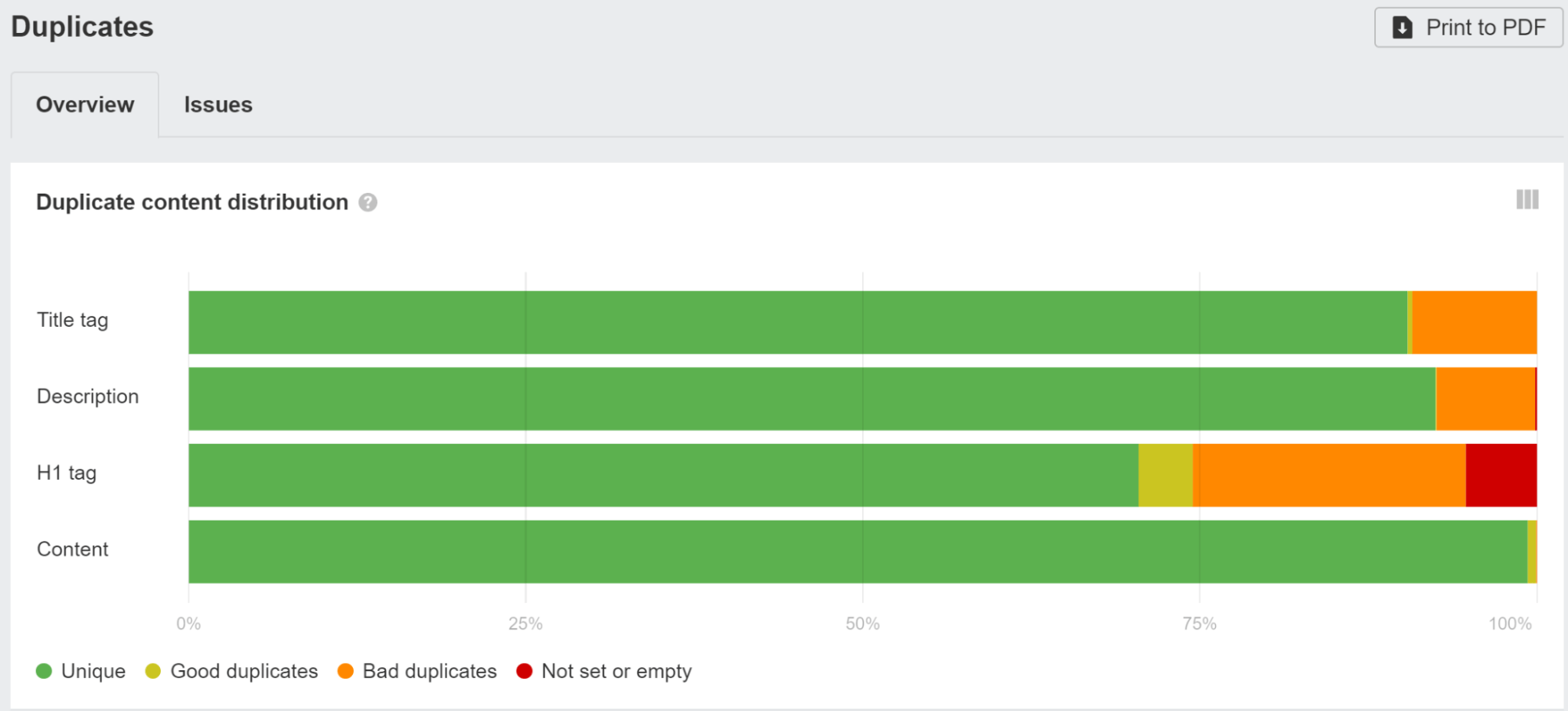
You need to use one of many search engine marketing modules like Helmet to set customized tags for every web page.
JavaScript can be used to overwrite default values you will have set. Google will course of this and use the overwritten title or description. For customers, nonetheless, titles could be problematic, as one title could seem within the browser they usually’ll discover a flash when it will get overwritten.
For those who see the title flashing, you need to use Ahrefs’ search engine marketing Toolbar to see each the uncooked HTML and rendered variations.
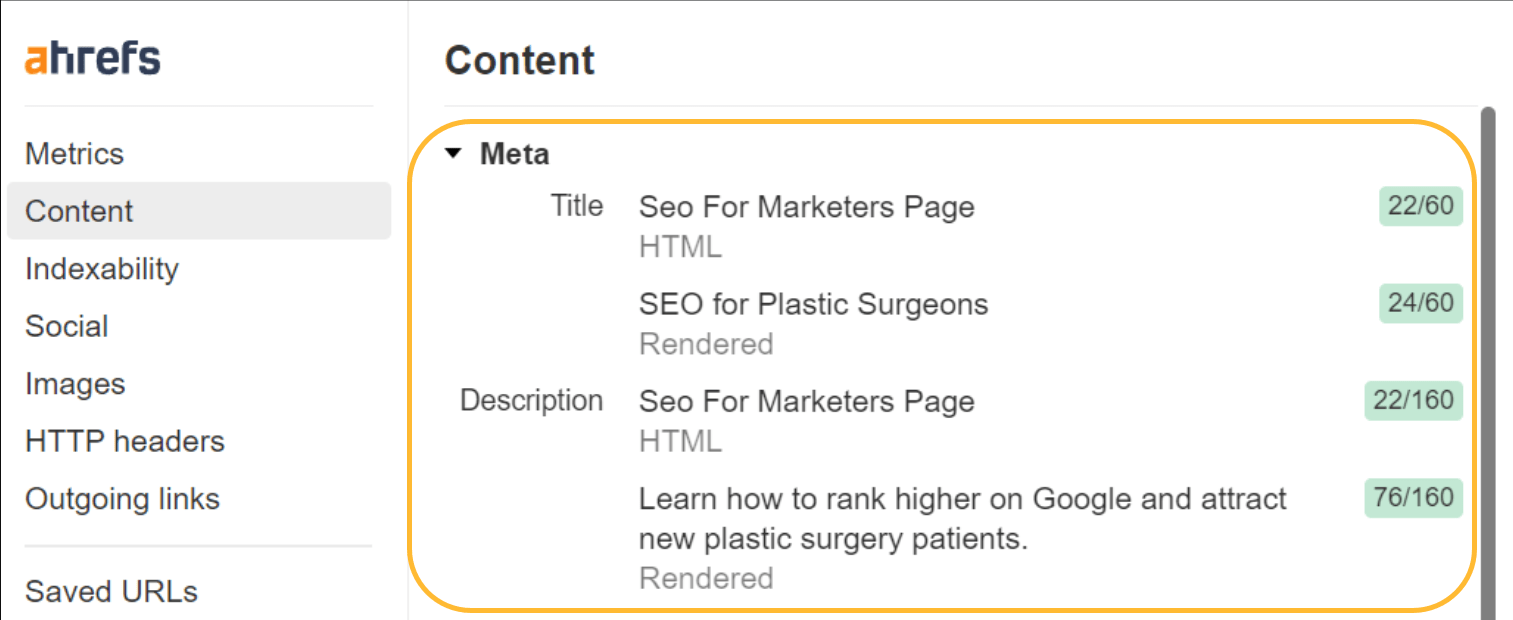
Google could not use your titles or meta descriptions anyway. As I discussed, the titles are price cleansing up for customers. Fixing this for meta descriptions gained’t actually make a distinction, although.
After we studied Google’s rewriting, we discovered that Google overwrites titles 33.4% of the time and meta descriptions 62.78% of the time. In Web site Audit, we’ll even present you which ones of your title tags Google has modified.
Canonical tag points
For years, Google mentioned it didn’t respect canonical tags inserted with JavaScript. It lastly added an exception to the documentation for instances the place there wasn’t already a tag. I precipitated that change. I ran exams to indicate this labored when Google was telling everybody it didn’t.
If there was already a canonical tag current and also you add one other one or overwrite the present one with JavaScript, then you definately’re giving them two canonical tags. On this case, Google has to determine which one to make use of or ignore the canonical tags in favor of different canonicalization indicators.
Commonplace search engine marketing recommendation of “each web page ought to have a self-referencing canonical tag” will get many SEOs in hassle. A dev takes that requirement, they usually make pages with and and not using a trailing slash self-canonical.
instance.com/web page with a canonical of instance.com/web page and instance.com/web page/ with a canonical of instance.com/web page/. Oops, that’s improper! You most likely need to redirect a kind of variations to the different.
The identical factor can occur with parameterized variations that you could be need to mix, however every is self-referencing.
Google makes use of essentially the most restrictive meta robots tag
With meta robots tags, Google is at all times going to take essentially the most restrictive choice it sees—irrespective of the placement.
When you’ve got an index tag within the uncooked HTML and noindex tag within the rendered HTML, Google will deal with it as noindex. When you’ve got a noindex tag within the uncooked HTML however you overwrite it with an index tag utilizing JavaScript, it’s nonetheless going to deal with that web page as noindex.
It really works the identical for nofollow tags. Google goes to take essentially the most restrictive choice.
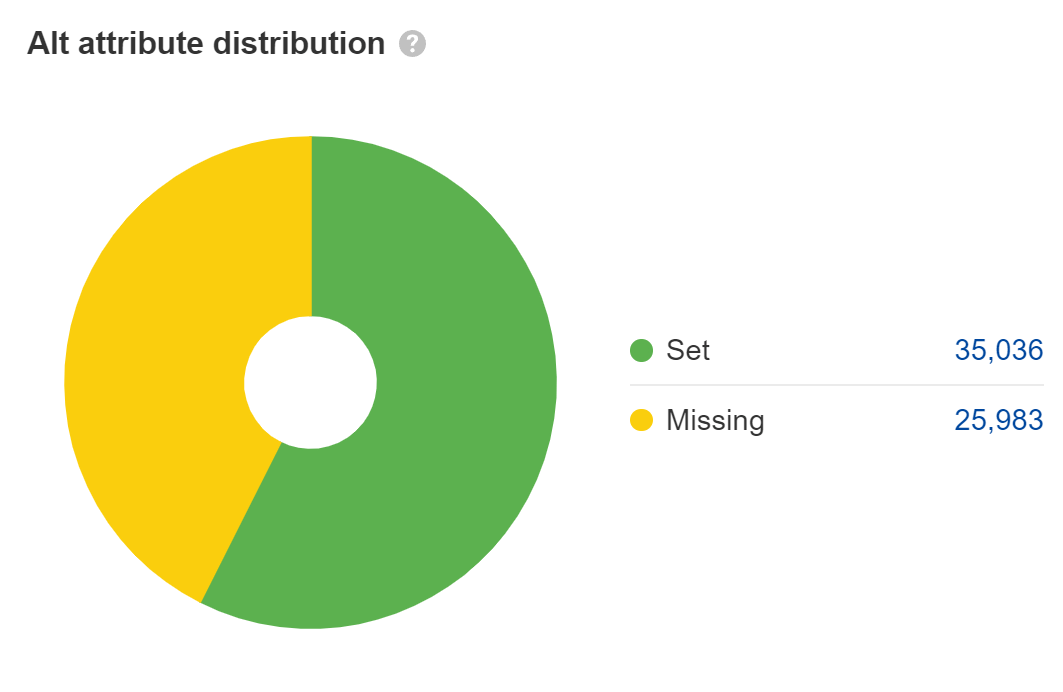
Set alt attributes on pictures
Lacking alt attributes are an accessibility situation, which can flip right into a authorized situation. Most huge corporations have been sued for ADA compliance points on their web sites, and a few get sued a number of instances a yr. I’d repair this for the primary content material pictures, however not for issues like placeholder or ornamental pictures the place you possibly can depart the alt attributes clean.
For net search, the textual content in alt attributes counts as textual content on the web page, however that’s actually the one position it performs. Its significance is commonly overstated for search engine marketing, in my view. Nonetheless, it does assist with picture search and picture rankings.
Plenty of JavaScript builders depart alt attributes clean, so double-check that yours are there. Have a look at the Pictures report in Web site Audit to search out these.
Permit crawling of JavaScript information
Don’t block entry to assets if they’re wanted to construct a part of the web page or add to the content material. Google must entry and obtain assets in order that it might render the pages correctly. In your robots.txt, the best approach to permit the wanted assets to be crawled is to add:
Person-Agent: GooglebotPermit: .jsPermit: .css
Additionally verify the robots.txt information for any subdomains or further domains you could be making requests from, resembling these to your API calls.
When you’ve got blocked assets with robots.txt, you possibly can verify if it impacts the web page content material utilizing the block choices within the “Community” tab in Chrome Dev Instruments. Choose the file and block it, then reload the web page to see if any modifications have been made.
Test if Google sees your content material
Many pages with JavaScript performance is probably not exhibiting all the content material to Google by default. For those who discuss to your builders, they could discuss with this as being not Doc Object Mannequin (DOM) loaded. This implies the content material wasn’t loaded by default and could be loaded later with an motion like a click on.
A fast verify you are able to do is to easily seek for a snippet of your content material in Google inside citation marks. Seek for “some phrase out of your content material” and see if the web page is returned within the search outcomes. Whether it is, then your content material was seemingly seen.
Sidenote.
Content material that’s hidden by default is probably not proven inside your snippet on the SERPs. It’s particularly necessary to verify your cellular model, as that is typically stripped down for consumer expertise.
You can even right-click and use the “Examine” choice. Seek for the textual content inside the “Parts” tab.
The most effective verify goes to be looking inside the content material of one among Google’s testing instruments just like the URL Inspection instrument in Google Search Console. I’ll discuss extra about this later.
I’d positively verify something behind an accordion or a dropdown. Typically, these parts make requests that load content material into the web page when they’re clicked on. Google doesn’t click on, so it doesn’t see the content material.
For those who use the examine methodology to go looking content material, be sure to repeat the content material after which reload the web page or open it in an incognito window earlier than looking.
For those who’ve clicked the aspect and the content material loaded in when that motion was taken, you’ll discover the content material. You might not see the identical end result with a recent load of the web page.
Duplicate content material points
With JavaScript, there could also be a number of URLs for a similar content material, which ends up in duplicate content material points. This can be attributable to capitalization, trailing slashes, IDs, parameters with IDs, and many others. So all of those could exist:
area.com/Abcarea.com/abcarea.com/123area.com/?id=123
For those who solely need one model listed, it is best to set a self-referencing canonical and both canonical tags from different variations that reference the primary model or ideally redirect the opposite variations to the primary model.
Test the Duplicates report in Web site Audit. We break down which duplicate clusters have canonical tags set and which have points.
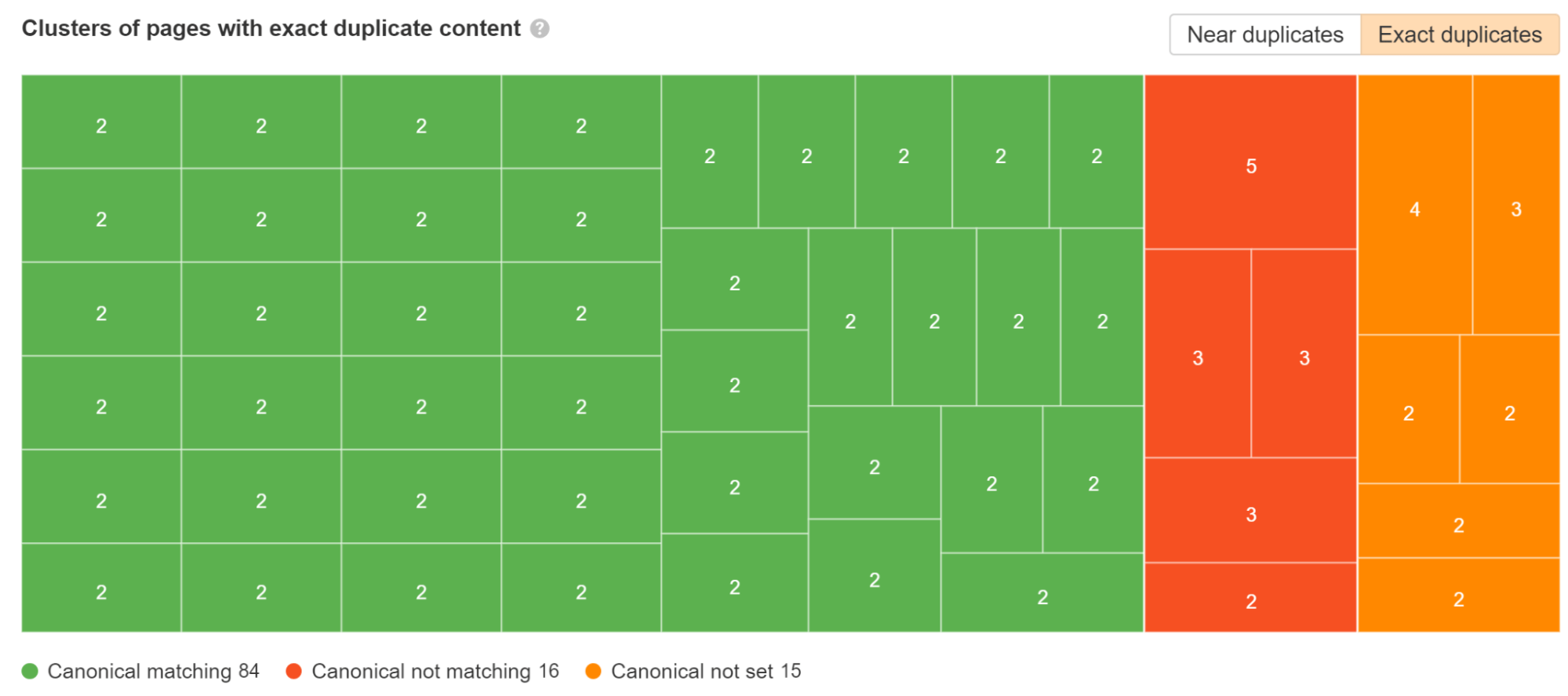
A standard situation with JavaScript frameworks is that pages can exist with and with out the trailing slash. Ideally, you’d choose the model you like and make it possible for model has a self-referencing canonical tag after which redirect the opposite model to your most popular model.
With app shell fashions, little or no content material and code could also be proven within the preliminary HTML response. In actual fact, each web page on the positioning could show the identical code, and this code could also be the very same because the code on another web sites.
For those who see quite a lot of URLs with a low phrase depend in Web site Audit, it might point out you might have this situation.
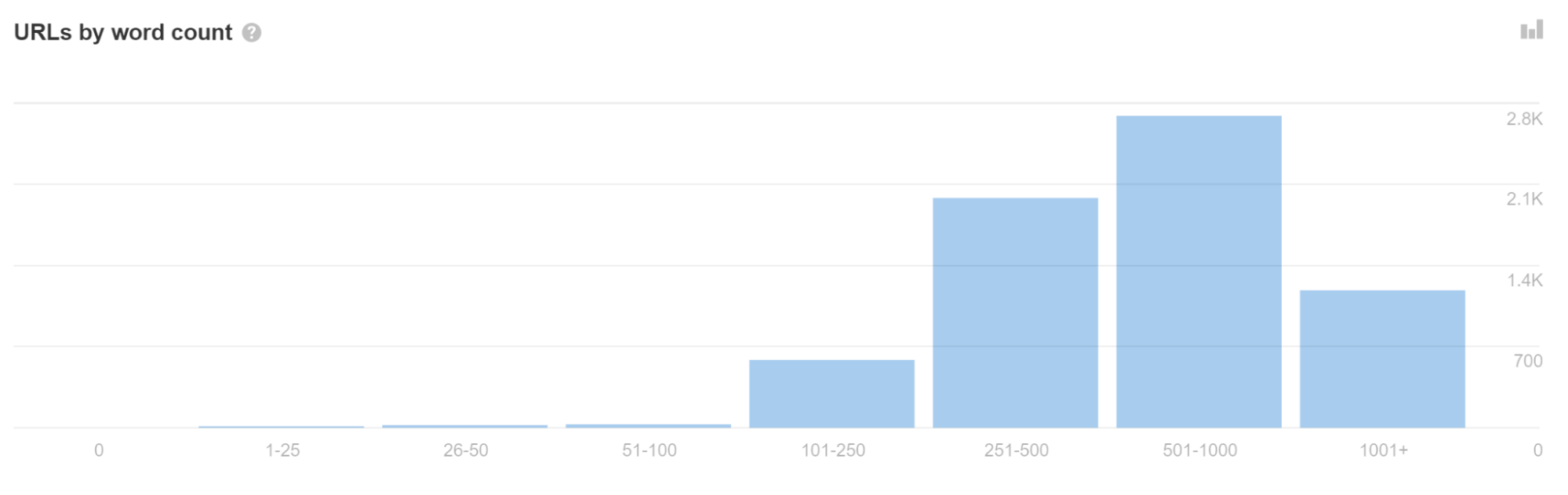
This will typically trigger pages to be handled as duplicates and never instantly go to rendering. Even worse, the improper web page and even the improper website could present in search outcomes. This could resolve itself over time however could be problematic, particularly with newer web sites.
Don’t use fragments (#) in URLs
# already has an outlined performance for browsers. It hyperlinks to a different a part of a web page when clicked—like our “desk of contents” function on the weblog. Servers usually gained’t course of something after a #. So for a URL like abc.com/#one thing, something after a # is usually ignored.
JavaScript builders have determined they need to use # because the set off for various functions, and that causes confusion. The most typical methods they’re misused are for routing and for URL parameters. Sure, they work. No, you shouldn’t do it.
JavaScript frameworks sometimes have routers that map what they name routes (paths) to clear URLs. A whole lot of JavaScript builders use hashes (#) for routing. That is particularly an issue for Vue and among the earlier variations of Angular.
To repair this for Vue, you possibly can work together with your developer to alter the next:
Vue router: Use ‘Historical past’ Mode as a substitute of the standard ‘Hash’ Mode.
const router = new VueRouter ({mode: ‘historical past’,router: [] //the array of router hyperlinks)}
There’s a rising pattern the place persons are utilizing # as a substitute of ? because the fragment identifier, particularly for passive URL parameters like these used for monitoring. I are inclined to suggest in opposition to it due to all the confusion and points. Situationally, I could be OK with it eliminating quite a lot of pointless parameters.
Create a sitemap
The router choices that permit for clear URLs often have an extra module that may additionally create sitemaps. You could find them by trying to find your system + router sitemap, resembling “Vue router sitemap.”
Most of the rendering options may additionally have sitemap choices. Once more, simply discover the system you employ and Google the system + sitemap resembling “Gatsby sitemap,” and also you’re certain to discover a resolution that already exists.
Standing codes and smooth 404s
As a result of JavaScript frameworks aren’t server-side, they will’t actually throw a server error like a 404. You’ve gotten a few completely different choices for error pages, such as:
- Utilizing a JavaScript redirect to a web page that does reply with a 404 standing code.
- Including a noindex tag to the web page that’s failing together with some sort of error message like “404 Web page Not Discovered.” This will probably be handled as a smooth 404 for the reason that precise standing code returned will probably be a 200 okay.
JavaScript redirects are OK, however not most popular
SEOs are used to 301/302 redirects, that are server-side. JavaScript is usually run client-side. Server-side redirects and even meta refresh redirects will probably be simpler for Google to course of than JavaScript redirects because it gained’t need to render the web page to see them.
JavaScript redirects will nonetheless be seen and processed throughout rendering and must be OK typically—they’re simply not as very best as different redirect sorts. They’re handled as everlasting redirects and nonetheless go all indicators like PageRank.
You’ll be able to typically discover these redirects within the code by on the lookout for “window.location.href”. The redirects might doubtlessly be within the config file as properly. Within the Subsequent.js config, there’s a redirect perform you need to use to set redirects. In different techniques, you could discover them within the router.
Internationalization points
There are often a couple of module choices for various frameworks that assist some options wanted for internationalization like hreflang. They’ve generally been ported to the completely different techniques and embrace i18n, intl or, many instances, the identical modules used for header tags like Helmet can be utilized so as to add the wanted tags.
We flag hreflang points within the Localization report in Web site Audit. We additionally ran a research and located that 67% of domains utilizing hreflang have points.
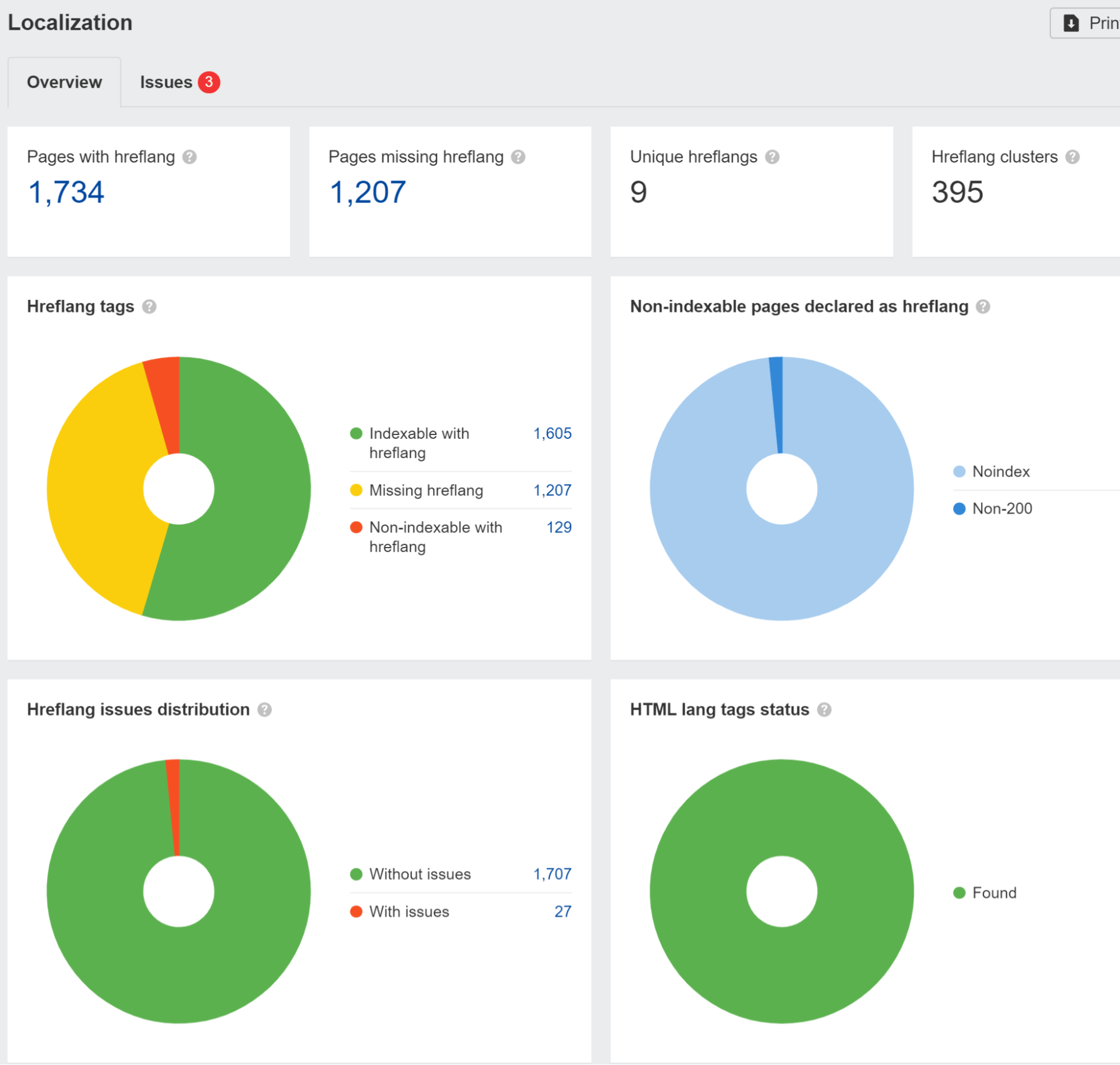
You additionally should be cautious in case your website is obstructing or treating guests from a particular nation or utilizing a specific IP in several methods. This will trigger your content material to not be seen by Googlebot. When you’ve got logic redirecting customers, you could need to exclude bots from this logic.
We’ll let you already know if that is occurring when establishing a venture in Web site Audit.

Use structured information
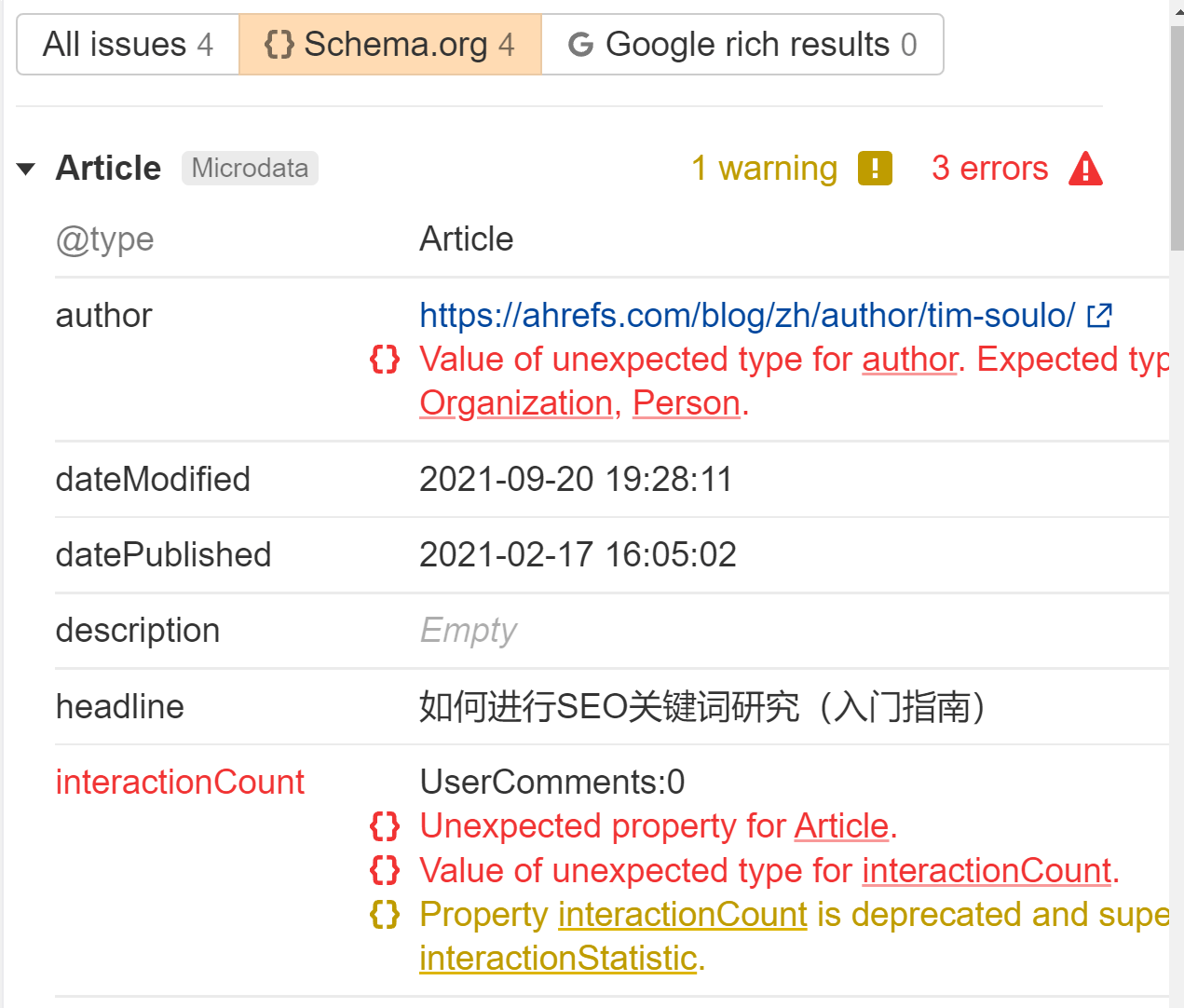
JavaScript can be utilized to generate or to inject structured information in your pages. It’s fairly frequent to do that with JSON-LD and never prone to trigger any points, however run some exams to ensure all the pieces comes out such as you anticipate.
We’ll flag any structured information we see within the Points report in Web site Audit. Search for the “Structured information has schema.org validation” error. We’ll inform you precisely what’s improper for every web page.
Use customary format hyperlinks
Hyperlinks to different pages must be within the net customary format. Inner and exterior hyperlinks should be an <a> tag with an href attribute. There are numerous methods you may make hyperlinks work for customers with JavaScript that aren’t search-friendly.
Good:
<a href=”/web page”>easy is sweet</a>
<a href=”/web page” onclick=”goTo(‘web page’)”>nonetheless okay</a>
Unhealthy:
<a onclick=”goTo(‘web page’)”>nope, no href</a>
<a href=”javascript:goTo(‘web page’)”>nope, lacking hyperlink</a>
<a href=”javascript:void(0)”>nope, lacking hyperlink</a>
<span onclick=”goTo(‘web page’)”>not the suitable HTML aspect</span>
<choice worth="web page">nope, improper HTML aspect</choice>
<a href=”#”>no hyperlink</a>
Button, ng-click, there are various extra methods this may be completed incorrectly.
In my expertise, Google nonetheless processes lots of the unhealthy hyperlinks and crawls them, however I’m undecided the way it treats them as far passing indicators like PageRank. The net is a messy place, and Google’s parsers are sometimes pretty forgiving.
It’s additionally price noting that inside hyperlinks added with JavaScript is not going to get picked up till after rendering. That must be comparatively fast and never a trigger for concern in most instances.
Use file versioning to resolve for unimaginable states being listed
Google closely caches all assets on its finish. I’ll discuss this a bit extra later, however it is best to know that its system can result in some unimaginable states being listed. This can be a quirk of its techniques. In these instances, earlier file variations are used within the rendering course of, and the listed model of a web page could include components of older information.
You need to use file versioning or fingerprinting (file.12345.js) to generate new file names when vital modifications are made in order that Google has to obtain the up to date model of the useful resource for rendering.
You might not see what’s proven to Googlebot
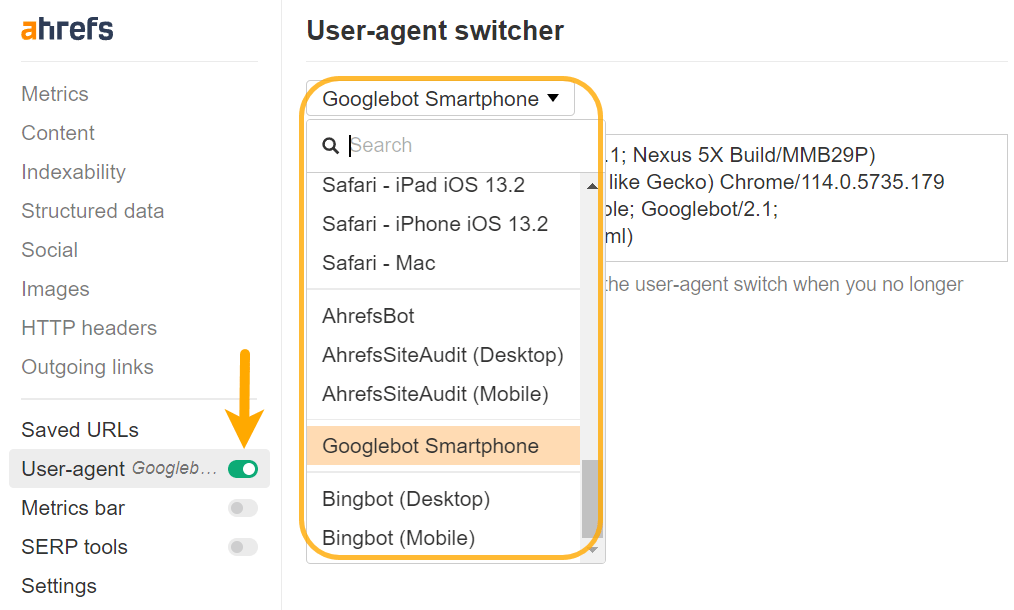
You might want to alter your user-agent to correctly diagnose some points. Content material could be rendered in another way for various user-agents and even IPs. You need to verify what Google really sees with its testing instruments, and I’ll cowl these in a bit.
You’ll be able to set a customized user-agent with Chrome DevTools to troubleshoot websites that prerender primarily based on particular user-agents, or you possibly can simply do that with our toolbar as properly.
Use polyfills for unsupported options
There could be options utilized by builders that Googlebot doesn’t assist. Your builders can use function detection. And if there’s a lacking function, they will select to both skip that performance or use a fallback methodology with a polyfill to see if they will make it work.
That is largely an FYI for SEOs. For those who see one thing you suppose Google must be seeing and it’s not seeing it, it might be due to the implementation.
Use lazy loading
Since I initially wrote this, lazy loading has largely moved from being JavaScript-driven to being dealt with by browsers.
You should still run into some JavaScript-driven lazy load setups. For essentially the most half, they’re most likely superb if the lazy loading is for pictures. The principle factor I’d verify is to see if content material is being lazy loaded. Refer again to the “Test if Google sees your content material” part above. These sorts of setups have precipitated issues with the content material being picked up appropriately.
Infinite scroll points
When you’ve got an infinite scroll setup, I nonetheless suggest a paginated web page model in order that Google can nonetheless crawl correctly.
One other situation I’ve seen with this setup is, sometimes, two pages get listed as one. I’ve seen this a couple of instances when individuals mentioned they couldn’t get their web page listed. However I’ve discovered their content material listed as a part of one other web page that’s often the earlier publish from them.
My concept is that when Google resized the viewport to be longer (extra on this later), it triggered the infinite scroll and loaded one other article in when it was rendering. On this case, what I like to recommend is to dam the JavaScript file that handles the infinite scrolling so the performance can’t set off.
Efficiency points
A whole lot of the JavaScript frameworks care for a ton of contemporary efficiency optimization for you.
The entire conventional efficiency finest practices nonetheless apply, however you get some fancy new choices. Code splitting chunks the information into smaller information. Tree shaking breaks out wanted components, so that you’re not loading all the pieces for each web page such as you’d see in conventional monolithic setups.
JavaScript setups completed properly are a factor of magnificence. JavaScript setups that aren’t completed properly could be bloated and trigger lengthy load instances.
Take a look at our Core Internet Vitals information for extra about web site efficiency.
JavaScript websites use extra crawl price range
JavaScript XHR requests eat crawl price range, and I imply they gobble it down. Not like most different assets which can be cached, these get fetched stay through the rendering course of.
One other attention-grabbing element is that the rendering service tries to not fetch assets that don’t contribute to the content material of the web page. If it will get this improper, you could be lacking some content material.
Staff aren’t supported, or are they?
Whereas Google traditionally says that it rejects service staff and repair staff can’t edit the DOM, Google’s personal Martin Splitt indicated that you could be get away with utilizing net staff typically.
Use HTTP connections
Googlebot helps HTTP requests however doesn’t assist different connection sorts like WebSockets or WebRTC. For those who’re utilizing these, present a fallback that makes use of HTTP connections.
One “gotcha” with JavaScript websites is they will do partial updates of the DOM. Shopping to a different web page as a consumer could not replace some points like title tags or canonical tags within the DOM, however this is probably not a problem for search engines like google.
Google hundreds every web page stateless prefer it’s a recent load. It’s not saving earlier data and never navigating between pages.
I’ve seen SEOs get tripped up considering there’s a downside due to what they see after navigating from one web page to a different, resembling a canonical tag that doesn’t replace. However Google could by no means see this state.
Devs can repair this by updating the state utilizing what’s known as the Historical past API. However once more, it is probably not an issue. A whole lot of time, it’s simply SEOs making hassle for the builders as a result of it seems to be bizarre to them. Refresh the web page and see what you see. Or higher but, run it by means of one among Google’s testing instruments to see what it sees.
Talking of its testing instruments, let’s discuss these.
Google testing instruments
Google has a number of testing instruments which can be helpful for JavaScript.
URL Inspection instrument in Google Search Console
This must be your supply of fact. Once you examine a URL, you’ll get quite a lot of data about what Google noticed and the precise rendered HTML from its system.
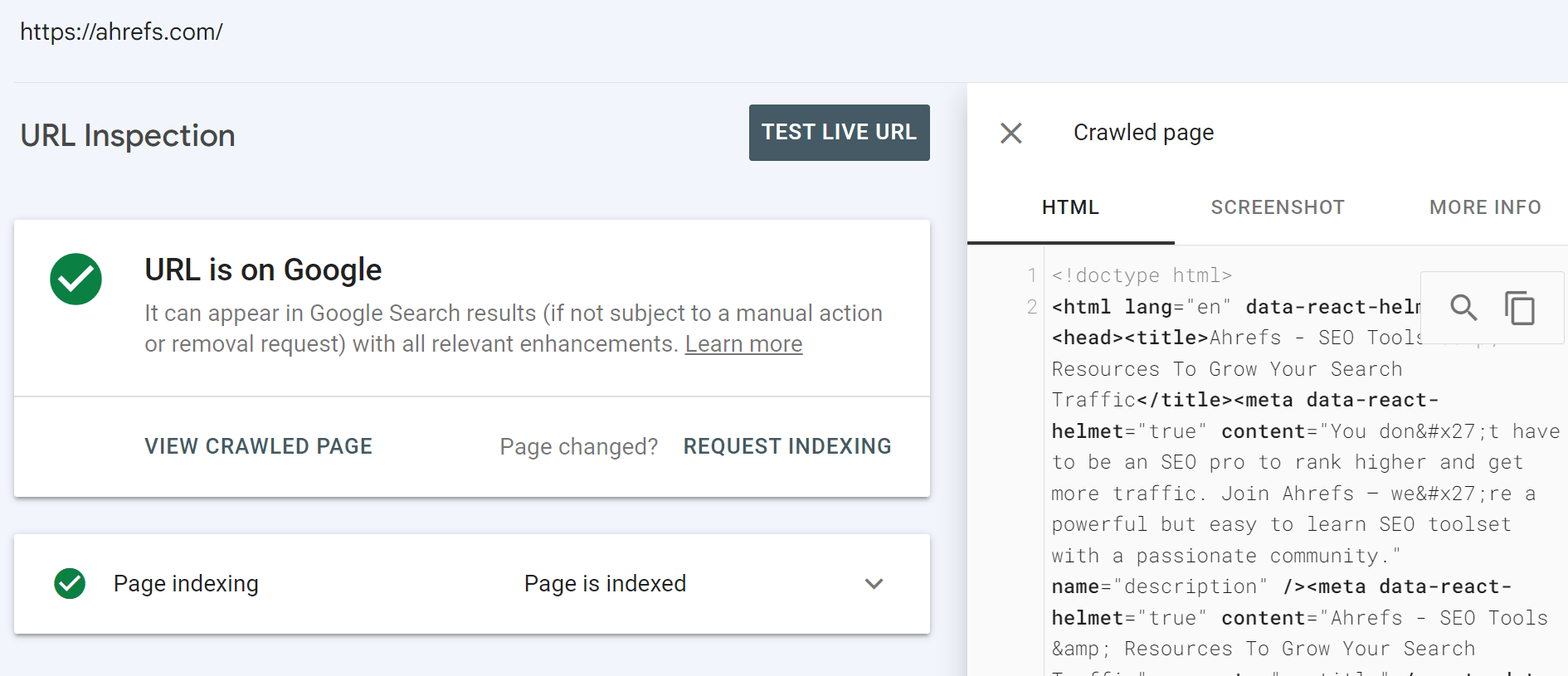
You’ve gotten the choice to run a stay check as properly.
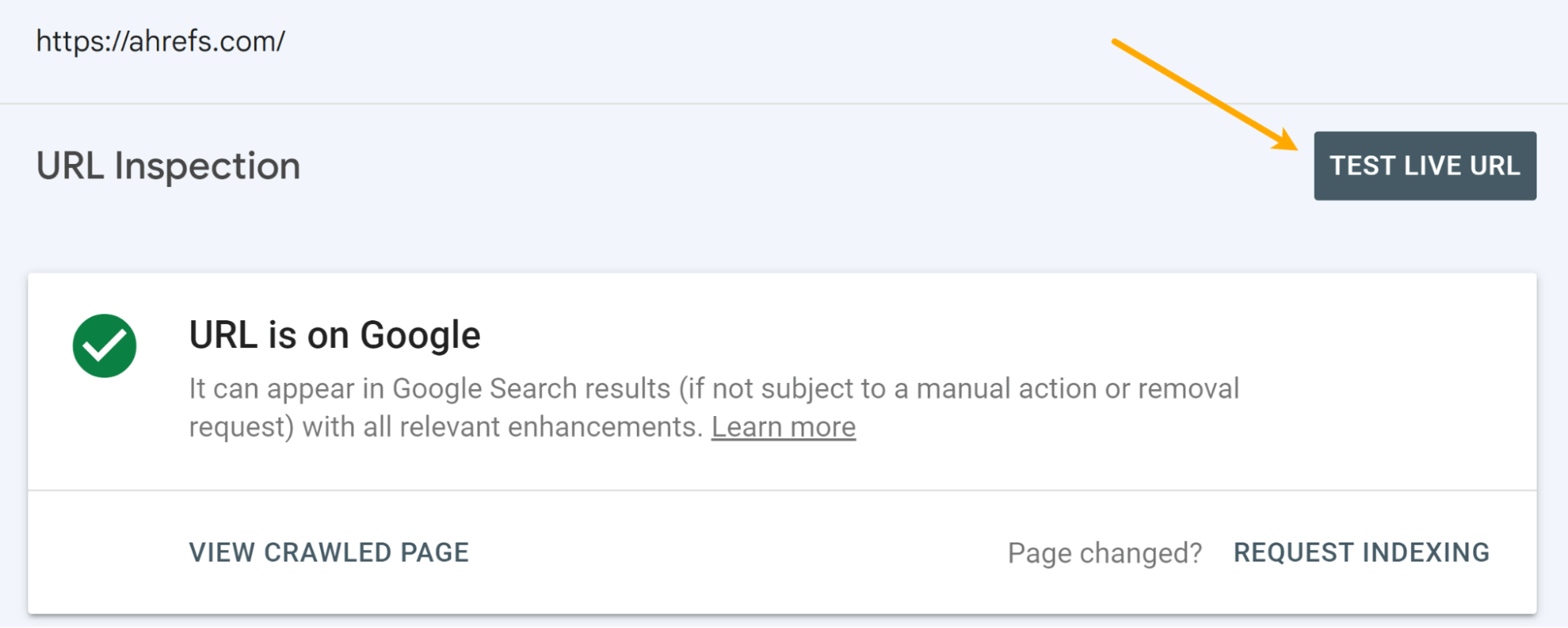
There are some variations between the primary renderer and the stay check. The renderer makes use of cached assets and is pretty affected person. The stay check and different testing instruments use stay assets, they usually reduce off rendering early since you’re ready for a end result. I’ll go into extra element about this within the rendering part later.
The screenshots in these instruments additionally present pages with the pixels painted, which Google doesn’t really do when rendering a web page.
The instruments are helpful to see if content material is DOM-loaded. The HTML proven in these instruments is the rendered DOM. You’ll be able to seek for a snippet of textual content to see if it was loaded in by default.
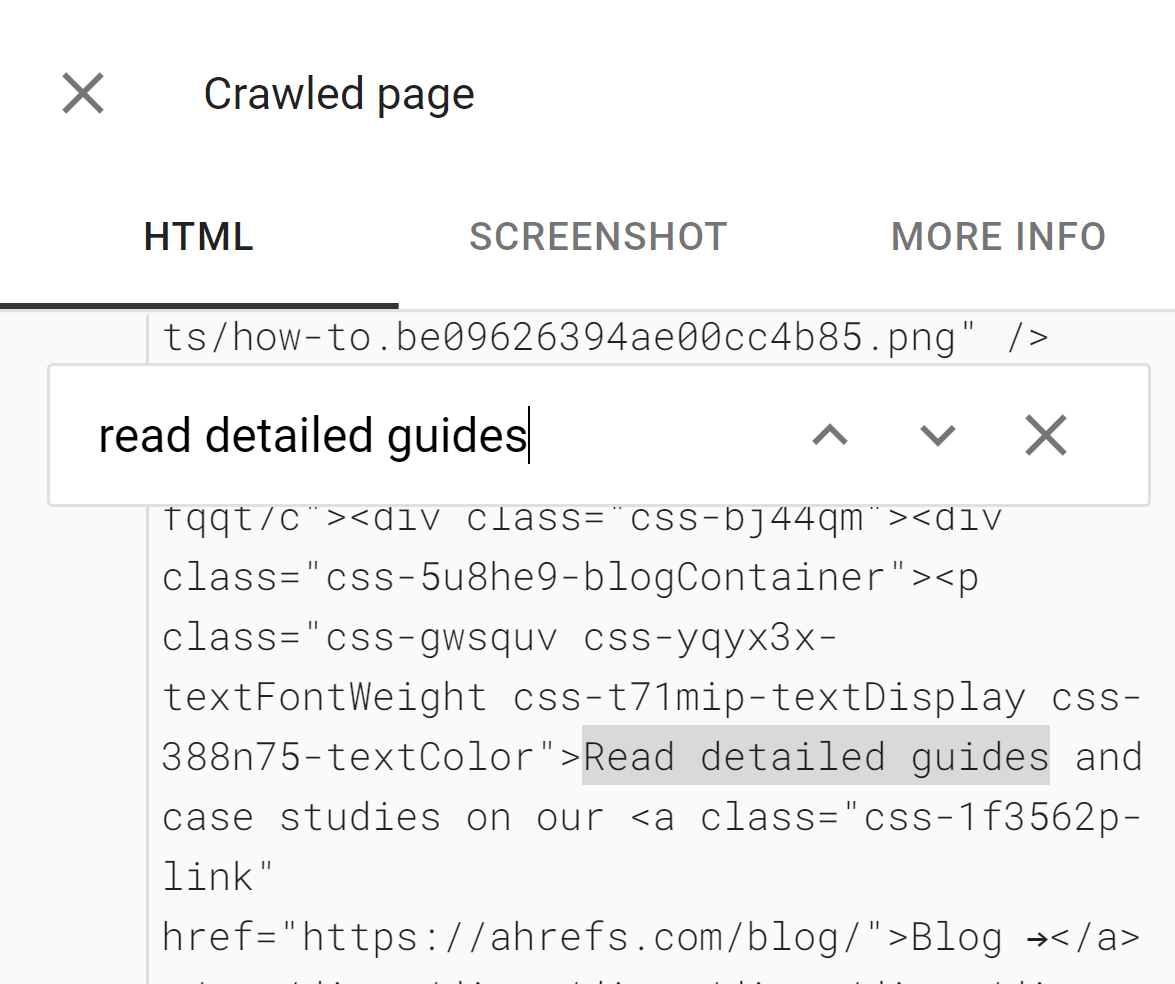
The instruments may also present you assets that could be blocked and console error messages, that are helpful for debugging.
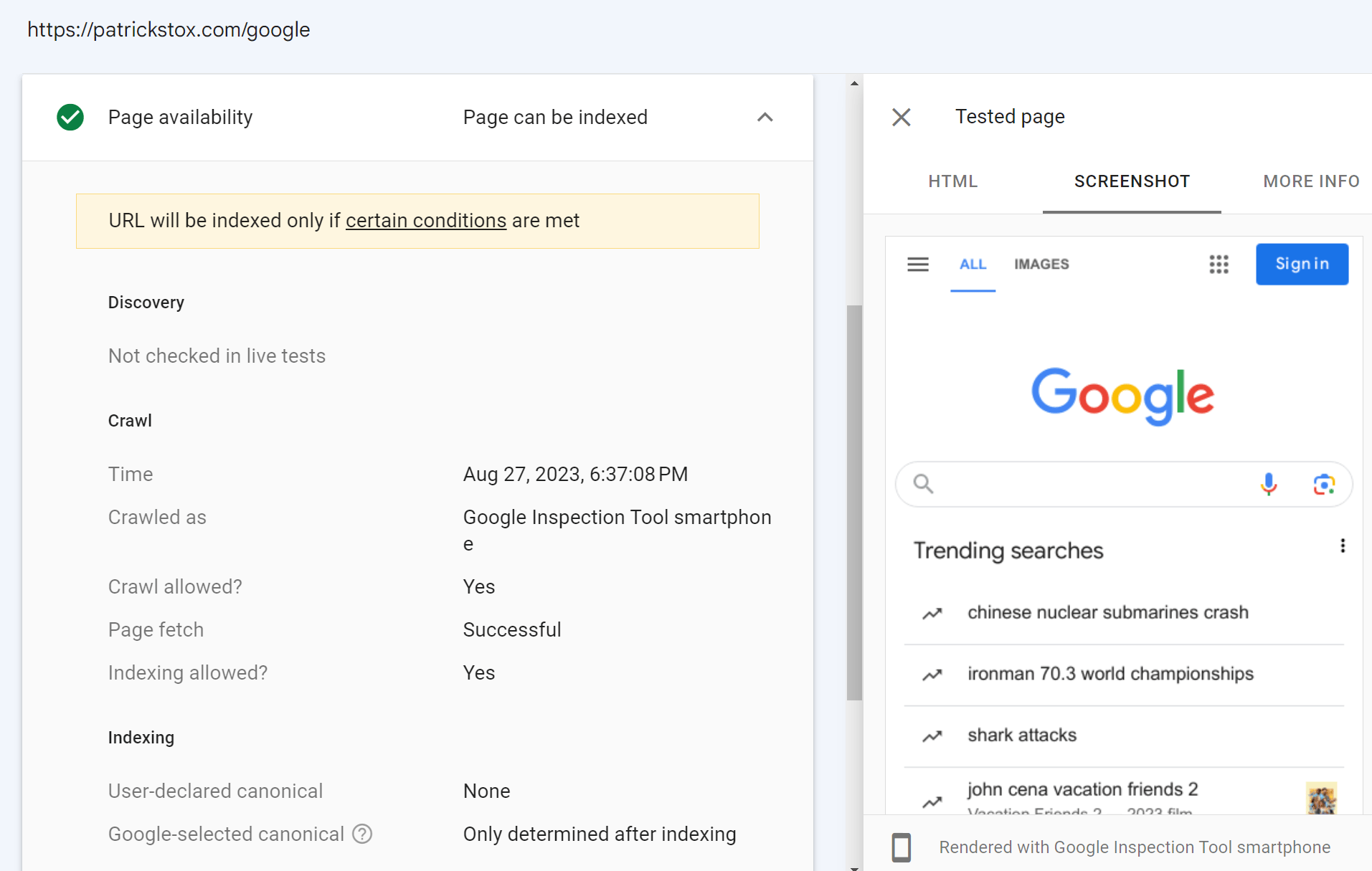
For those who don’t have entry to the Google Search Console property for an internet site, you possibly can nonetheless run a stay check on it. For those who add a redirect by yourself web site on a property the place you might have Google Search Console entry, then you possibly can examine that URL and the inspection instrument will observe the redirect and present you the stay check end result for the web page on the opposite area.
Within the screenshot under, I added a redirect from my website to Google’s homepage. The stay check for this follows the redirect and reveals me Google’s homepage. I don’t even have entry to Google’s Google Search Console account, though I want I did.
Wealthy Outcomes Take a look at instrument
The Wealthy Outcomes Take a look at instrument permits you to verify your rendered web page as Googlebot would see it for cellular or for desktop.
Cellular-Pleasant Take a look at instrument
You’ll be able to nonetheless use the Cellular-Pleasant Take a look at instrument for now, however Google has introduced it’s shutting down in December 2023.
It has the identical quirks as the opposite testing instruments from Google.
Ahrefs
Ahrefs is the one main search engine marketing instrument that renders webpages when crawling the net, so we’ve information from JavaScript websites that no different instrument does. We render ~200M pages a day, however that’s a fraction of what we crawl.
It permits us to verify for JavaScript redirects. We are able to additionally present hyperlinks we discovered inserted with JavaScript, which we present with a JS tag within the hyperlink reviews:

Within the drop-down menu for pages in Web site Explorer, we even have an examine choice that permits you to see the historical past of a web page and evaluate it to different crawls. We’ve got a JS marker there for pages that have been rendered with JavaScript enabled.
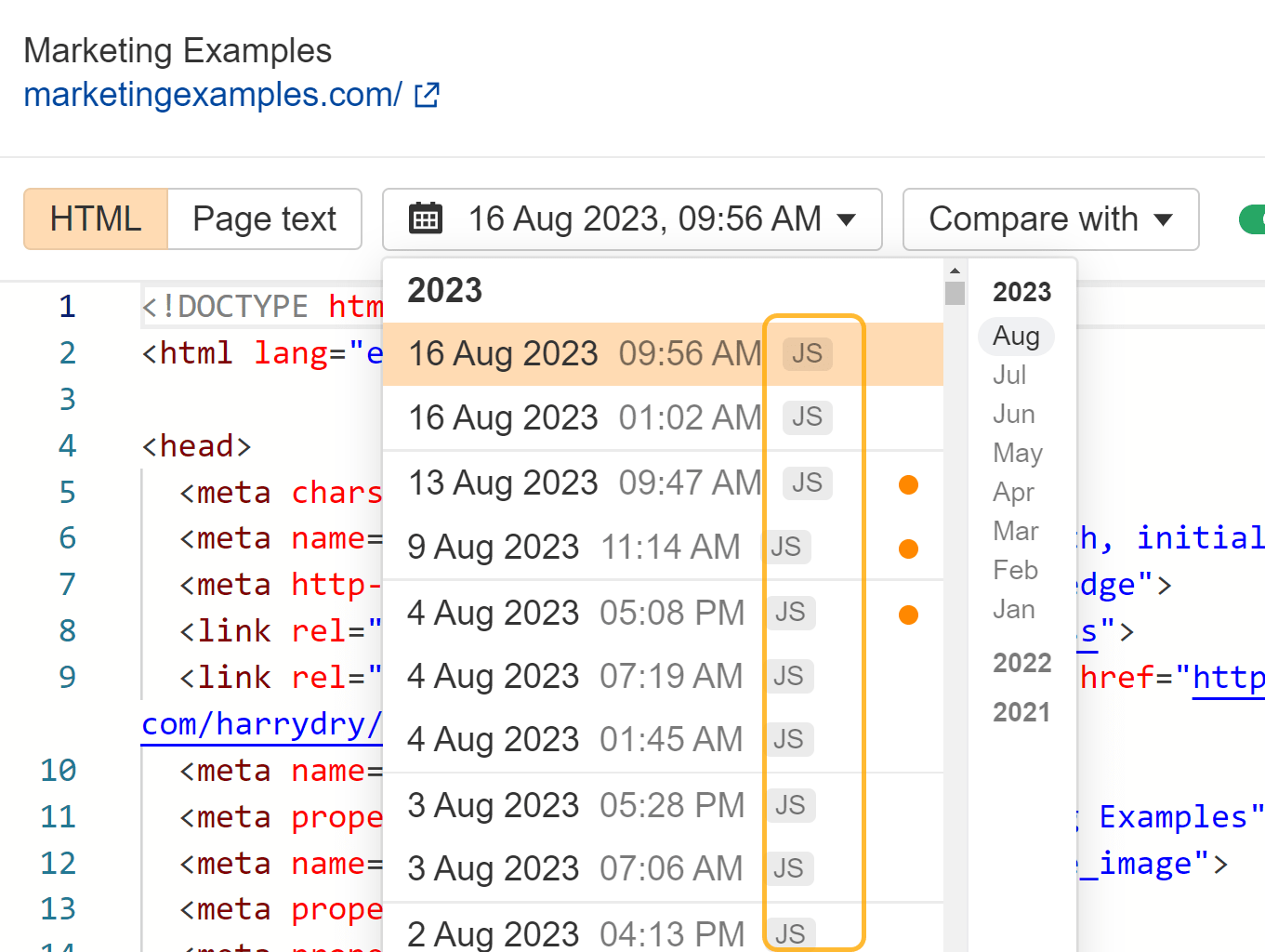
You’ll be able to allow JavaScript in Web site Audit crawls to unlock extra information in your audits.
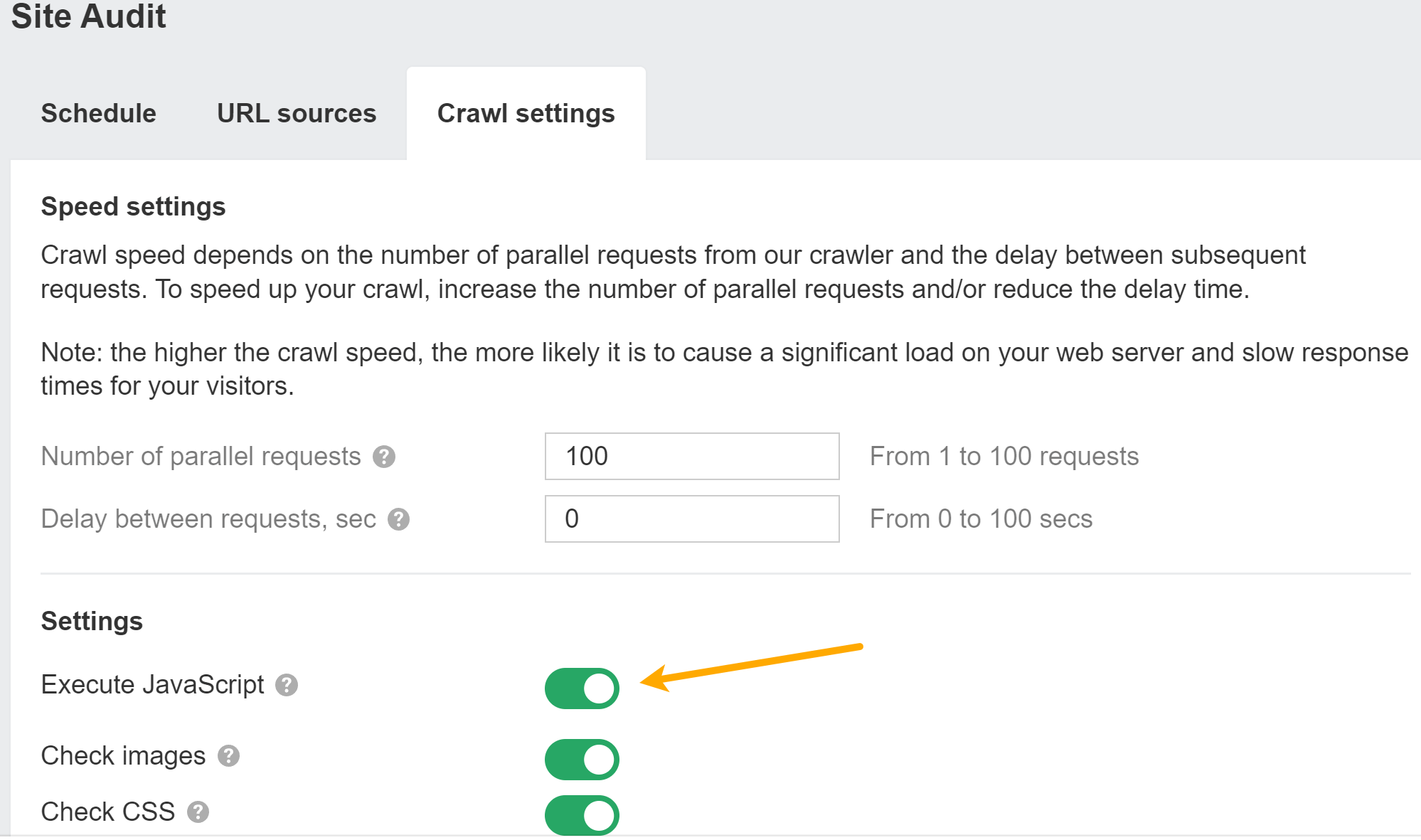
When you’ve got JavaScript rendering enabled, we are going to present the uncooked and rendered HTML for each web page. Use the “magnifying glass” choice subsequent to a web page in Web page Explorer and go to “View supply” within the menu. You can even evaluate in opposition to earlier crawls and search inside the uncooked or rendered HTML throughout all pages on the website.
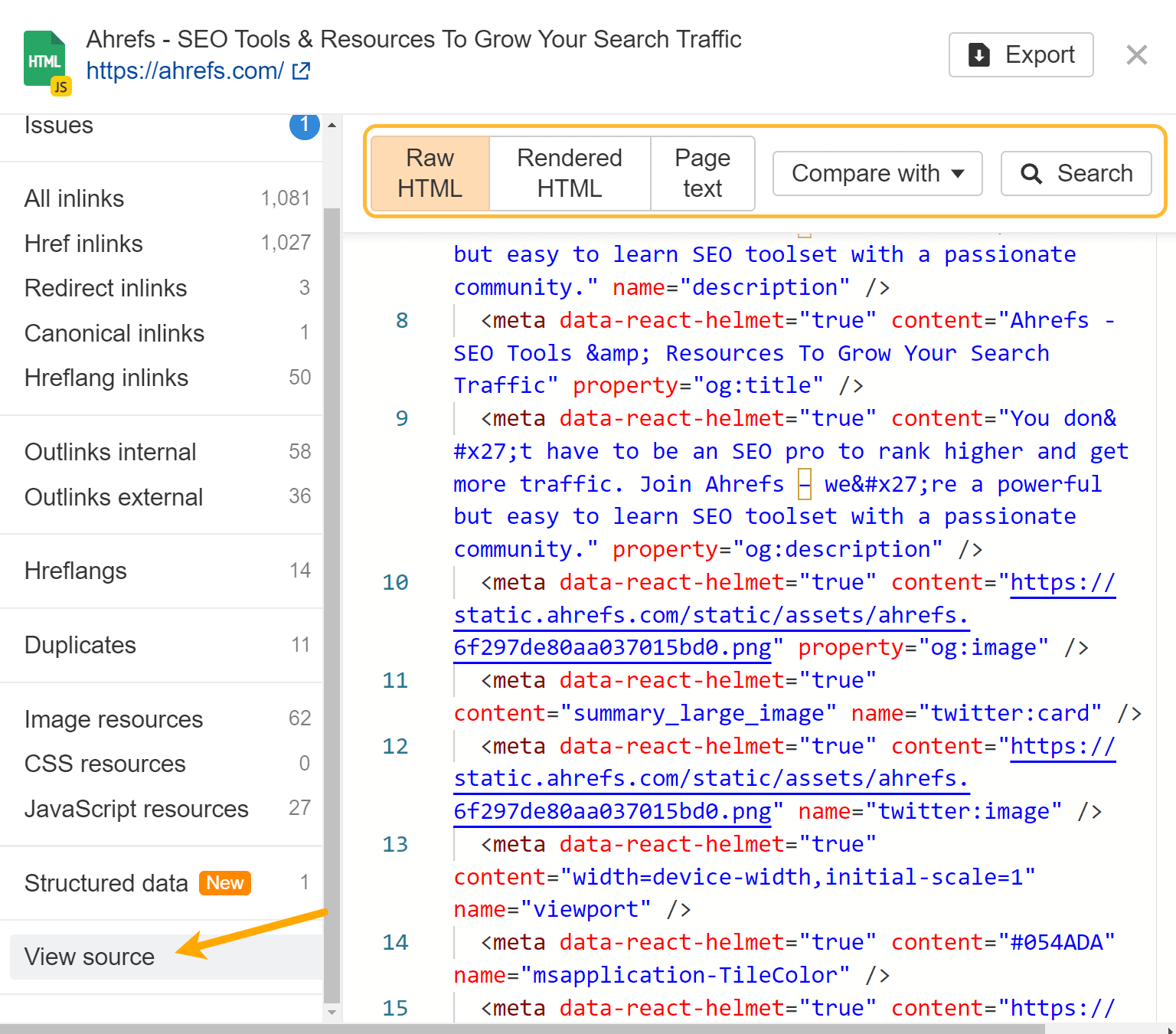
For those who run a crawl with out JavaScript after which one other one with it, you need to use our crawl comparability options to see variations between the variations.
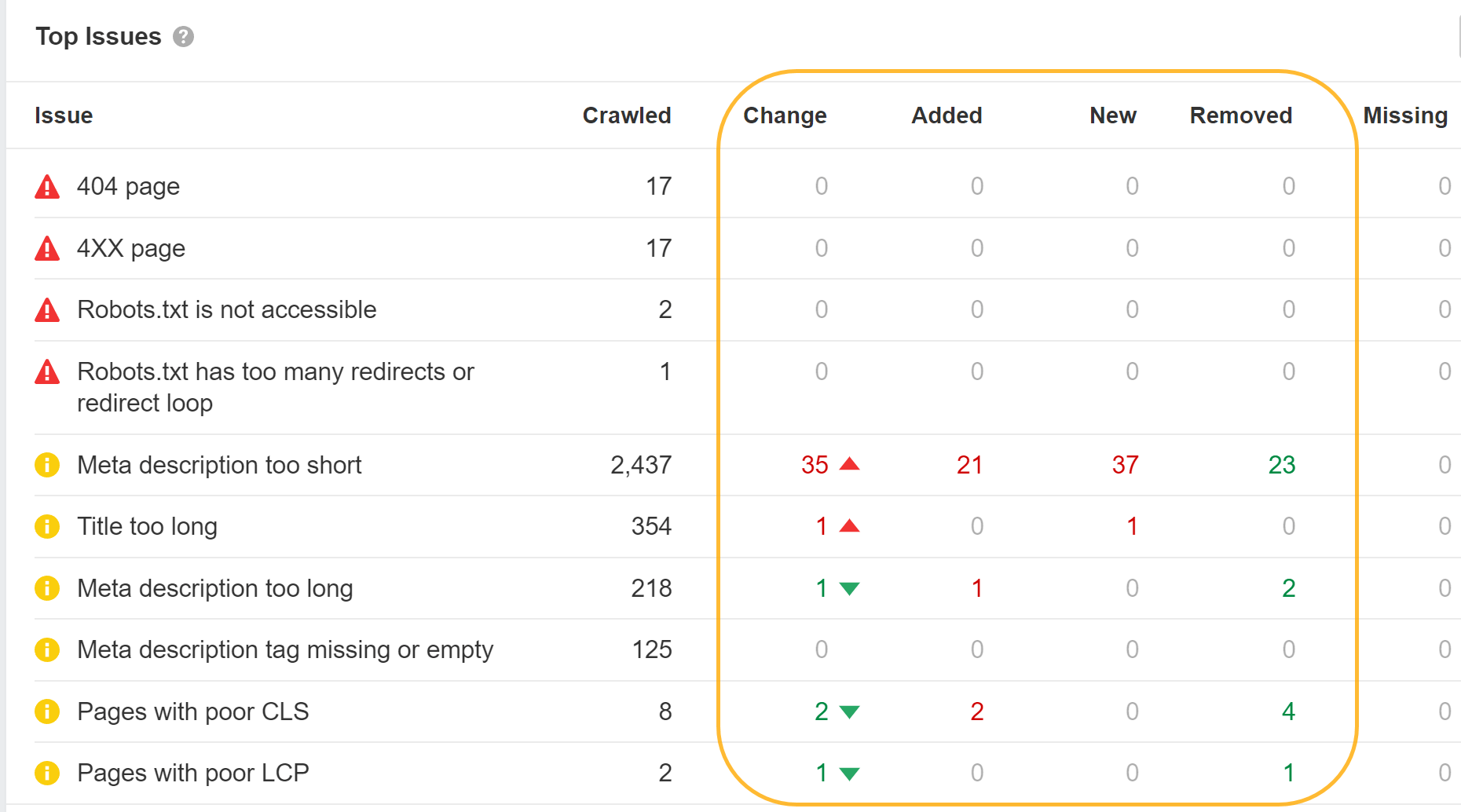
Ahrefs’ search engine marketing Toolbar additionally helps JavaScript and permits you to evaluate HTML to rendered variations of tags.
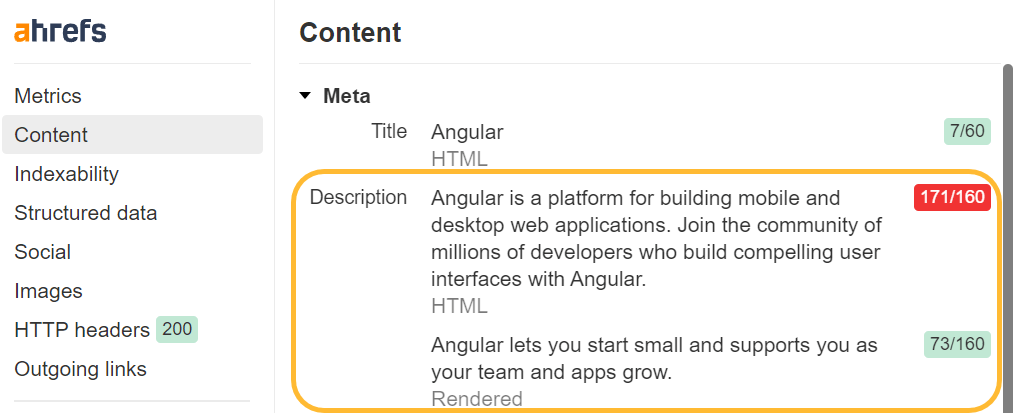
View supply vs. examine
Once you right-click in a browser window, you’ll see a few choices for viewing the supply code of the web page and for inspecting the web page. View supply goes to indicate you a similar as a GET request would. That is the uncooked HTML of the web page.

Examine reveals you the processed DOM after modifications have been made and is nearer to the content material that Googlebot sees. It’s the web page after JavaScript has run and made modifications to it.
You need to largely use examine over view supply when working with JavaScript.
Typically you’ll want to verify view supply
As a result of Google seems to be at each uncooked and rendered HTML for some points, you should still have to verify view supply at instances. For example, if Google’s instruments are telling you the web page is marked noindex, however you don’t see a noindex tag within the rendered HTML, it’s doable that it was there within the uncooked HTML and overwritten.
For issues like noindex, nofollow, and canonical tags, you could have to verify the uncooked HTML since points can carry over. Do not forget that Google will take essentially the most restrictive statements it noticed for the meta robots tags, and it’ll ignore canonical tags while you present it a number of canonical tags.
Don’t browse with JavaScript turned off
I’ve seen this advisable manner too many instances. Google renders JavaScript, so what you see with out JavaScript is under no circumstances like what Google sees. That is simply foolish.
Don’t use Google Cache
Google’s cache shouldn’t be a dependable approach to verify what Googlebot sees. What you sometimes see within the cache is the uncooked HTML snapshot. Your browser then fires the JavaScript that’s referenced within the HTML. It’s not what Google noticed when it rendered the web page.
To complicate this additional, web sites could have their Cross-Origin Useful resource Sharing (CORS) coverage arrange in a manner that the required assets can’t be loaded from a distinct area.
The cache is hosted on webcache.googleusercontent.com. When that area tries to request the assets from the precise area, the CORS coverage says, “Nope, you possibly can’t entry my information.” Then the information aren’t loaded, and the web page seems to be damaged within the cache.
The cache system was made to see the content material when an internet site is down. It’s not notably helpful as a debug instrument.
Within the early days of search engines like google, a downloaded HTML response was sufficient to see the content material of most pages. Due to the rise of JavaScript, search engines like google now have to render many pages as a browser would to allow them to see content material as how a consumer sees it.
The system that handles the rendering course of at Google known as the Internet Rendering Service (WRS). Google has supplied a simplistic diagram to cowl how this course of works.
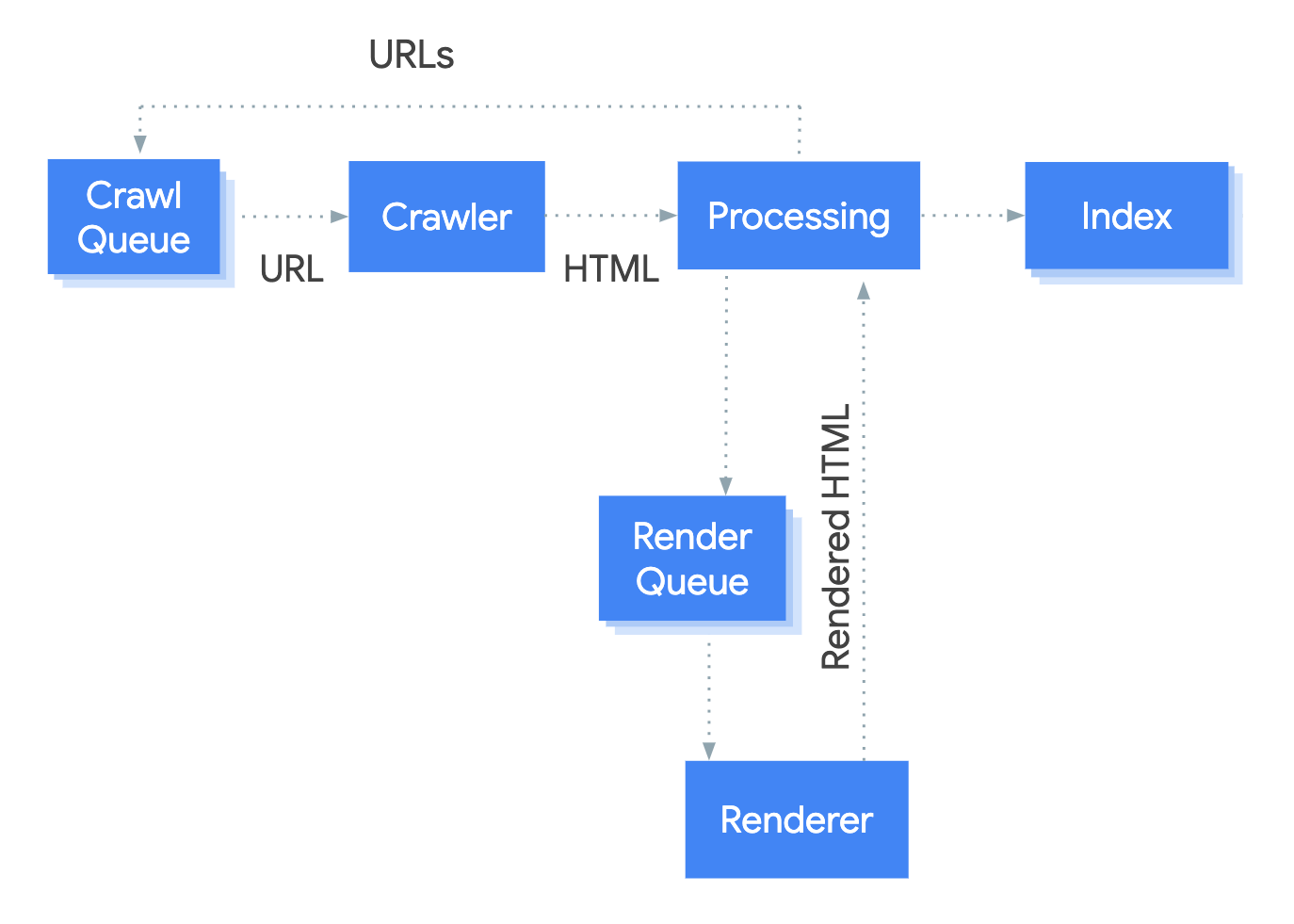
Let’s say we begin the method at URL.
1. Crawler
The crawler sends GET requests to the server. The server responds with headers and the contents of the file, which then will get saved. The headers and the content material sometimes are available in the identical request.
The request is prone to come from a cellular user-agent since Google is on mobile-first indexing now, however it additionally nonetheless crawls with the desktop user-agent.
The requests largely come from Mountain View (CA, U.S.), however it additionally does some crawling for locale-adaptive pages outdoors of the U.S. As I discussed earlier, this may trigger points if websites are blocking or treating guests in a particular nation in several methods.
It’s additionally necessary to notice that whereas Google states the output of the crawling course of as “HTML” on the picture above, in actuality, it’s crawling and storing the assets wanted to construct the web page just like the HTML, JavaScript information, and CSS information. There’s additionally a 15 MB max dimension restrict for HTML information.
2. Processing
There are quite a lot of techniques obfuscated by the time period “Processing” within the picture. I’m going to cowl a couple of of those which can be related to JavaScript.
Assets and hyperlinks
Google doesn’t navigate from web page to web page as a consumer would. A part of “Processing” is to verify the web page for hyperlinks to different pages and information wanted to construct the web page. These hyperlinks are pulled out and added to the crawl queue, which is what Google is utilizing to prioritize and schedule crawling.
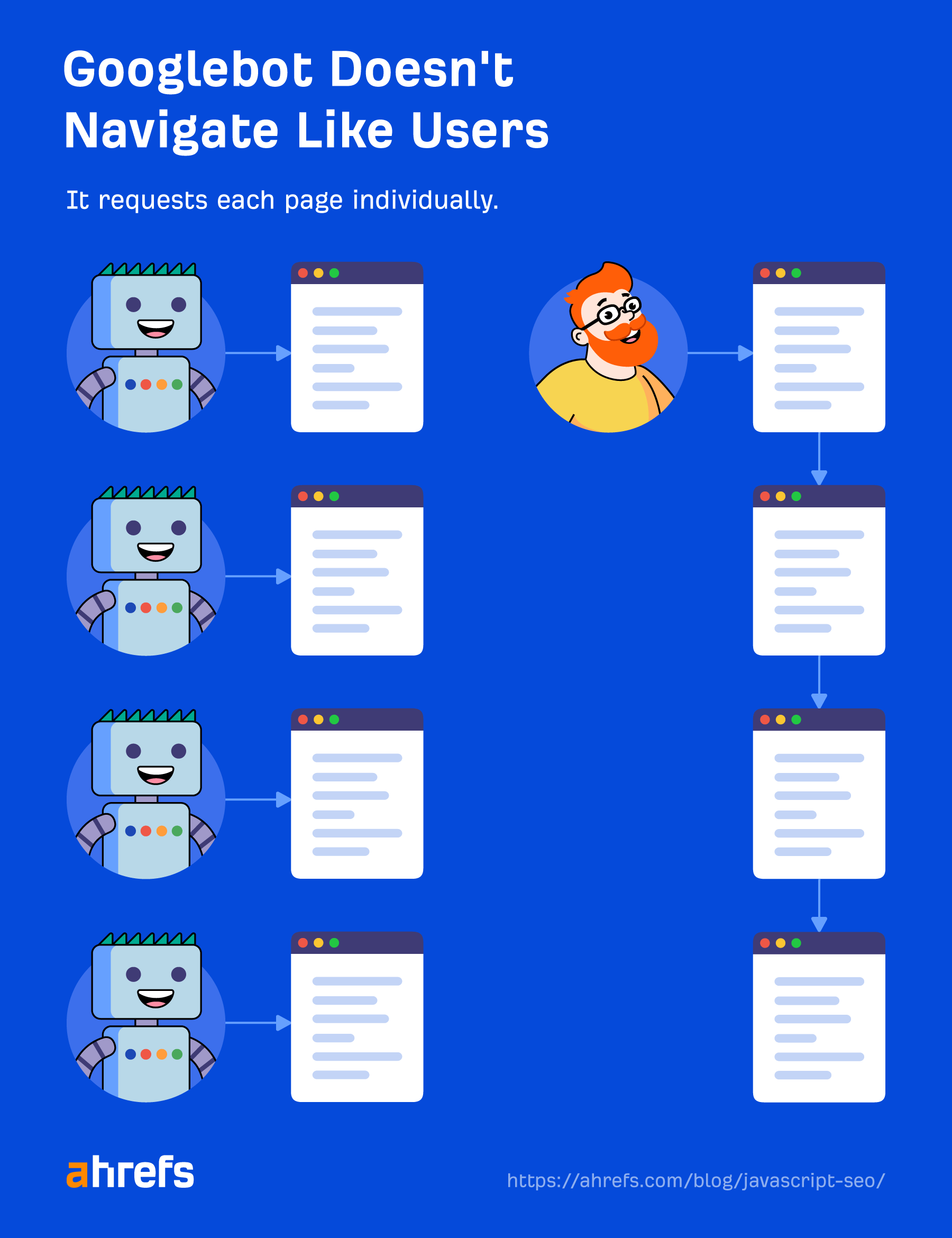
Google will pull useful resource hyperlinks (CSS, JS, and many others.) wanted to construct a web page from issues like <hyperlink> tags.
As I discussed earlier, inside hyperlinks added with JavaScript is not going to get picked up till after rendering. That must be comparatively fast and never a trigger for concern typically. Issues like information websites would be the exception the place each second counts.
Caching
Each file that Google downloads, together with HTML pages, JavaScript information, CSS information, and many others., goes to be aggressively cached. Google will ignore your cache timings and fetch a brand new copy when it needs to. I’ll discuss a bit extra about this and why it’s necessary within the “Renderer” part.
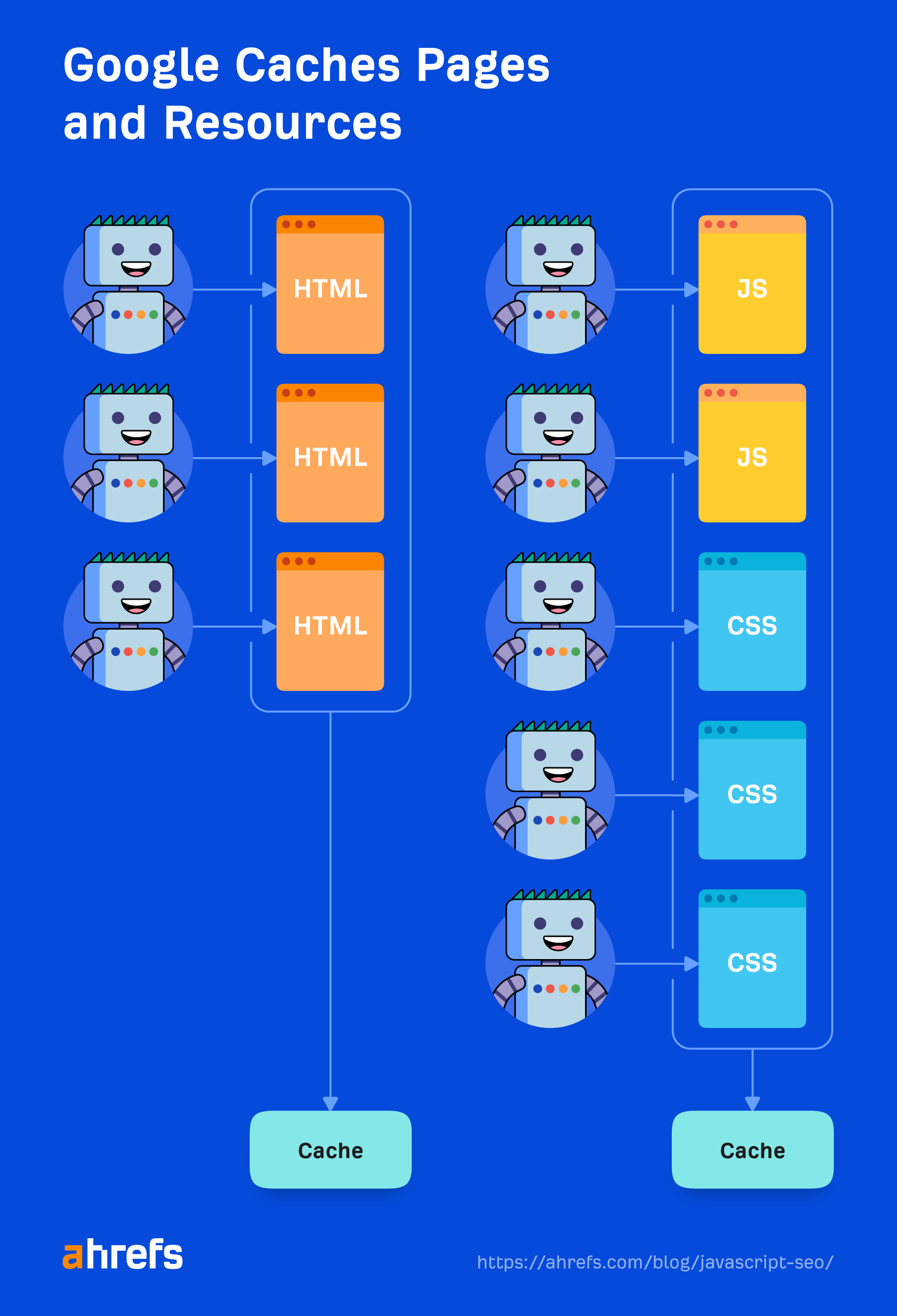
Duplicate elimination
Duplicate content material could also be eradicated or deprioritized from the downloaded HTML earlier than it will get despatched to rendering. I already talked about this within the “Duplicate content material” part above.
Most restrictive directives
As I discussed earlier, Google will select essentially the most restrictive statements between HTML and the rendered model of a web page. If JavaScript modifications a press release and that conflicts with the assertion from HTML, Google will merely obey whichever is essentially the most restrictive. Noindex will override index, and noindex in HTML will skip rendering altogether.
3. Render queue
One of many greatest considerations from many SEOs with JavaScript and two-stage indexing (HTML then rendered web page) is that pages could not get rendered for days and even weeks. When Google regarded into this, it discovered pages went to the renderer at a median time of 5 seconds, and the ninetieth percentile was minutes. So the period of time between getting the HTML and rendering the pages shouldn’t be a priority in most instances.
Nonetheless, Google doesn’t render all pages. Like I discussed beforehand, a web page with a robots meta tag or header containing a noindex tag is not going to be despatched to the renderer. It gained’t waste assets rendering a web page it might’t index anyway.
It additionally has high quality checks on this course of. If it seems to be on the HTML or can fairly decide from different indicators or patterns {that a} web page isn’t ok high quality to index, then it gained’t hassle sending that to the renderer.
There’s additionally a quirk with information websites. Google needs to index pages on information websites quick so it might index the pages primarily based on the HTML content material first—and are available again later to render these pages.
4. Renderer
The renderer is the place Google renders a web page to see what a consumer sees. That is the place it’s going to course of the JavaScript and any modifications made by JavaScript to the DOM.
For this, Google is utilizing a headless Chrome browser that’s now “evergreen,” which implies it ought to use the most recent Chrome model and assist the most recent options. Years in the past, Google was rendering with Chrome 41, and lots of options weren’t supported at that time.
Google has extra data on the WRS, which incorporates issues like denying permissions, being stateless, flattening mild DOM and shadow DOM, and extra that’s price studying.
Rendering at web-scale would be the eighth surprise of the world. It’s a critical enterprise and takes an incredible quantity of assets. Due to the size, Google is taking many shortcuts with the rendering course of to hurry issues up.
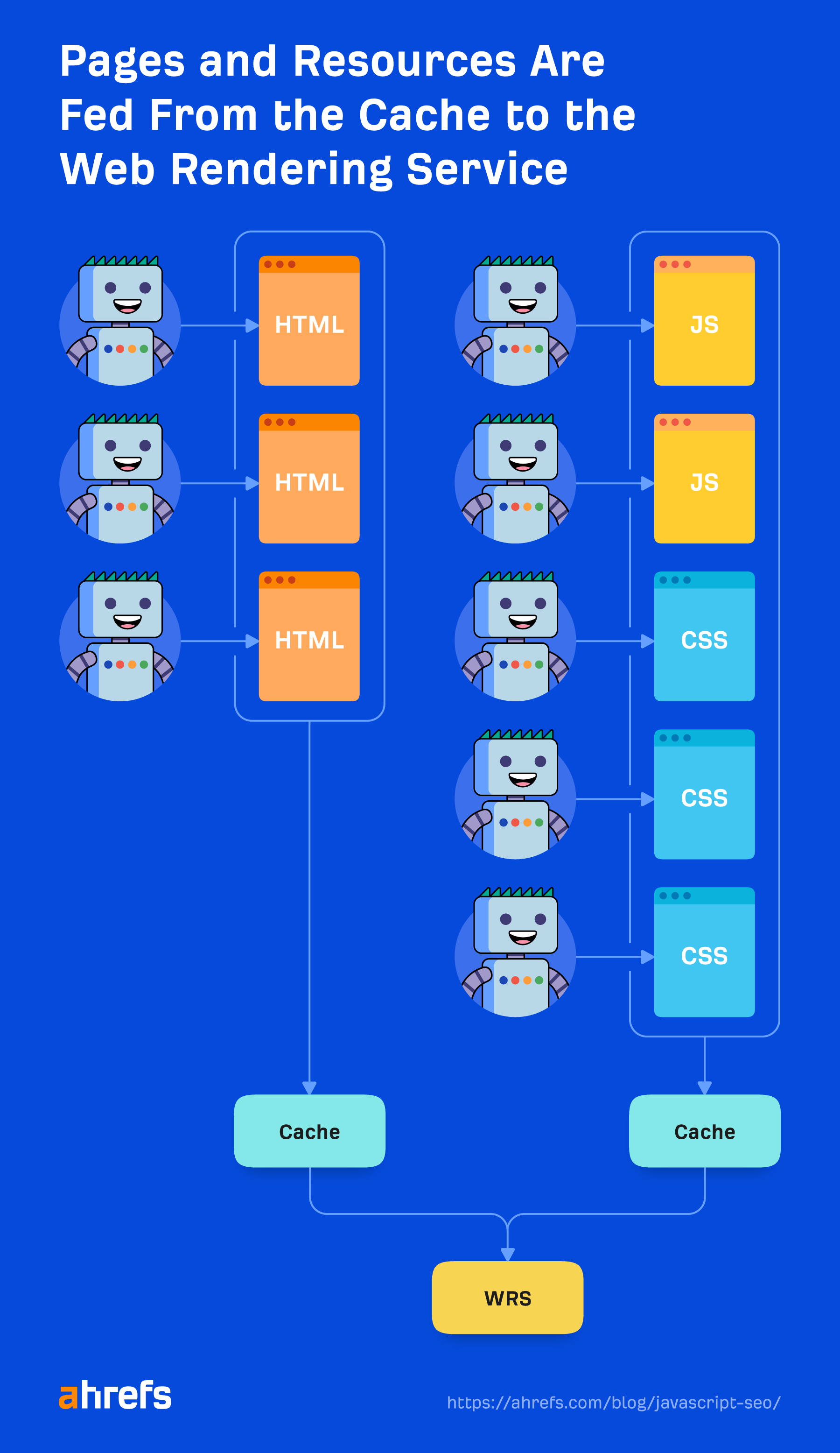
Cached assets
Google is relying closely on caching assets. Pages are cached. Recordsdata are cached. Almost all the pieces is cached earlier than being despatched to the renderer. It’s not going out and downloading every useful resource for each web page load, as a result of that might be costly for it and web site homeowners. As an alternative, it makes use of these cached assets to be extra environment friendly.
The exception to that’s XHR requests, which the renderer will do in actual time.
There’s no five-second timeout
A standard search engine marketing fantasy is that Google solely waits 5 seconds to load your web page. Whereas it’s at all times a good suggestion to make your website sooner, this fantasy doesn’t actually make sense with the way in which Google caches information talked about above. It’s already loading a web page with all the pieces cached in its techniques, not making requests for recent assets.
If it solely waited 5 seconds, it could miss quite a lot of content material.
The parable seemingly comes from the testing instruments just like the URL Inspection instrument the place assets are fetched stay as a substitute of cached, and they should return a end result to customers inside an inexpensive period of time. It might additionally come from pages not being prioritized for crawling, which makes individuals suppose they’re ready a very long time to render and index them.
There isn’t any fastened timeout for the renderer. It runs with a sped-up timer to see if something is added at a later time. It additionally seems to be on the occasion loop within the browser to see when all the actions have been taken. It’s actually affected person, and also you shouldn’t be involved about any particular time restrict.
It’s affected person, however it additionally has safeguards in place in case one thing will get caught or somebody is attempting to mine Bitcoin on its pages. Sure, it’s a factor. We had so as to add safeguards for Bitcoin mining as properly and even revealed a research about it.
What Googlebot sees
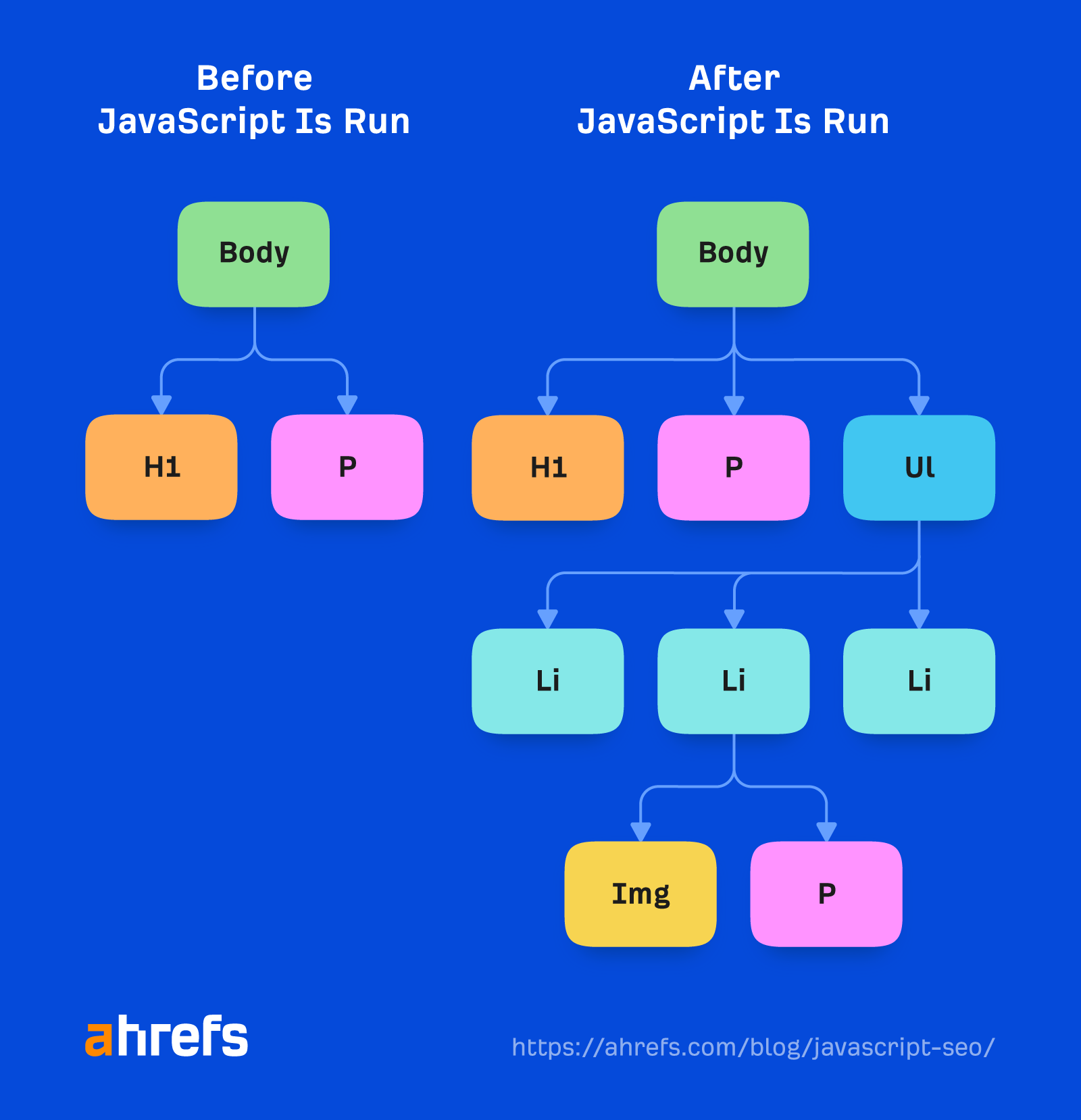
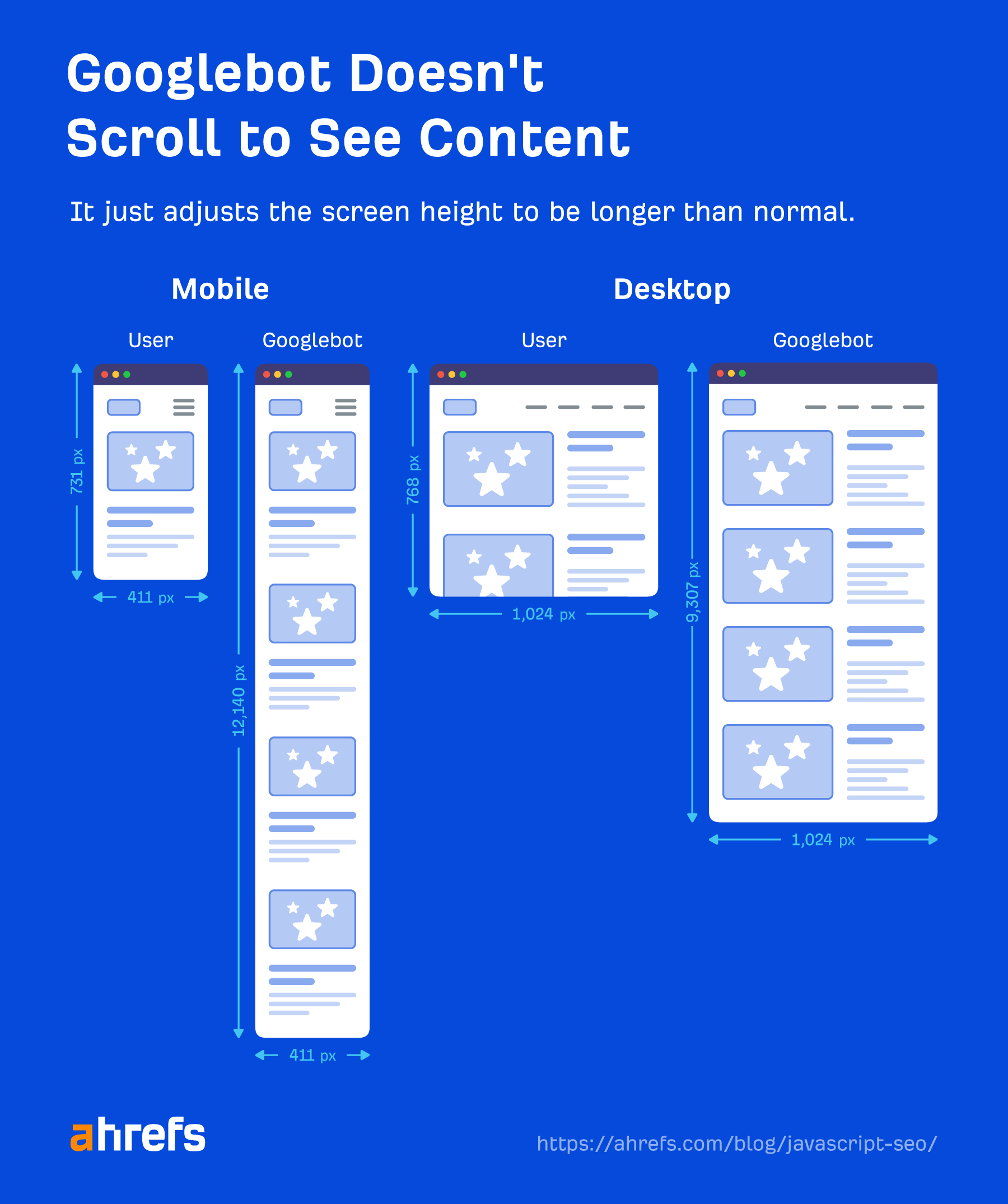
Googlebot doesn’t take motion on webpages. It’s not going to click on issues or scroll, however that doesn’t imply it doesn’t have workarounds. So long as content material is loaded within the DOM and not using a wanted motion, Google will see it. If it’s not loaded into the DOM till after a click on, then the content material gained’t be discovered.
Google doesn’t have to scroll to see your content material both as a result of it has a intelligent workaround to see the content material. For cellular, it hundreds the web page with a display dimension of 411×731 pixels and resizes the size to 12,140 pixels.
Basically, it turns into a very lengthy telephone with a display dimension of 411×12140 pixels. For desktop, it does the identical and goes from 1024×768 pixels to 1024×9307 pixels. I haven’t seen any latest exams for these numbers, and it might change relying on how lengthy the pages are.
One other attention-grabbing shortcut is that Google doesn’t paint the pixels through the rendering course of. It takes time and extra assets to complete a web page load, and it doesn’t actually need to see the ultimate state with the pixels painted. In addition to, graphics playing cards are costly between gaming, crypto mining, and AI.
Google simply must know the construction and the format, and it will get that with out having to really paint the pixels. As Martin places it:
In Google search we don’t actually care in regards to the pixels as a result of we don’t actually need to present it to somebody. We need to course of the knowledge and the semantic data so we’d like one thing within the intermediate state. We don’t have to really paint the pixels.
A visible could assist clarify what’s reduce out a bit higher. In Chrome Dev Instruments, when you run a check on the “Efficiency” tab, you get a loading chart. The strong inexperienced half right here represents the portray stage. For Googlebot, that by no means occurs, so it saves assets.

Grey = Downloads
Blue = HTML
Yellow = JavaScript
Purple = Structure
Inexperienced = Portray
5. Crawl queue
Google has a useful resource that talks a bit about crawl price range. However it is best to know that every website has its personal crawl price range, and every request needs to be prioritized. Google additionally has to steadiness crawling your pages vs. each different web page on the web.
Newer websites typically or websites with quite a lot of dynamic pages will seemingly be crawled slower. Some pages will probably be up to date much less typically than others, and a few assets may additionally be requested much less often.
There are many choices with regards to rendering JavaScript. Google has a strong chart that I’m simply going to indicate. Any sort of SSR, static rendering, and prerendering setup goes to be superb for search engines like google. Gatsby, Subsequent, Nuxt, and many others., are all nice.

Essentially the most problematic one goes to be full client-side rendering the place all the rendering occurs within the browser. Whereas Google will most likely be OK client-side rendering, it’s finest to decide on a distinct rendering choice to assist different search engines like google.
Bing additionally has assist for JavaScript rendering, however the scale is unknown. Yandex and Baidu have restricted assist from what I’ve seen, and lots of different search engines like google have little to no assist for JavaScript. Our personal search engine, Yep, has assist, and we render ~200M pages per day. However we don’t render each web page we crawl.
There’s additionally the choice of dynamic rendering, which is rendering for sure user-agents. This can be a workaround and, to be trustworthy, I by no means advisable it and am glad Google is recommending in opposition to it now as properly.
Situationally, you could need to use it to render for sure bots like search engines like google and even social media bots. Social media bots don’t run JavaScript, so issues like OG tags gained’t be seen until you render the content material earlier than serving it to them.
Virtually, it makes setups extra complicated and tougher for SEOs to troubleshoot. It’s positively cloaking, though Google says it’s not and that it’s OK with it.
Notice
For those who have been utilizing the previous AJAX crawling scheme with hashbangs (#!), do know this has been deprecated and is now not supported.
Ultimate ideas
JavaScript shouldn’t be one thing for SEOs to concern. Hopefully, this text has helped you perceive learn how to work with it higher.
Don’t be afraid to achieve out to your builders and work with them and ask them questions. They will be your biggest allies in serving to to enhance your JavaScript website for search engines like google.
Have questions? Let me know on Twitter.