

{kind=link}
Lately, giant language fashions (LLMs) have gained prominence in synthetic intelligence, however they’ve primarily centered on textual content and struggled with understanding visible content material. Multimodal giant language fashions (MLLMs) have emerged to bridge this hole. MLLMs mix visible and textual data in a single Transformer-based mannequin, permitting them to study and generate content material from each modalities, marking a big development in AI capabilities.
KOSMOS-2.5 is a multimodal mannequin designed to deal with two carefully associated transcription duties inside a unified framework. The primary process includes producing textual content blocks with spatial consciousness and assigning spatial coordinates to textual content traces inside text-rich pictures. The second process focuses on producing structured textual content output in markdown format, capturing varied types and constructions.
Each duties are managed beneath a single system, using a shared Transformer structure, task-specific prompts, and adaptable textual content representations. The mannequin’s structure combines a imaginative and prescient encoder based mostly on ViT (Imaginative and prescient Transformer) with a language decoder based mostly on the Transformer structure, related by a resampler module.
To coach this mannequin, it undergoes pretraining on a considerable dataset of text-heavy pictures, which embrace textual content traces with bounding bins and plain markdown textual content. This dual-task coaching method enhances KOSMOS-2.5’s total multimodal literacy capabilities.
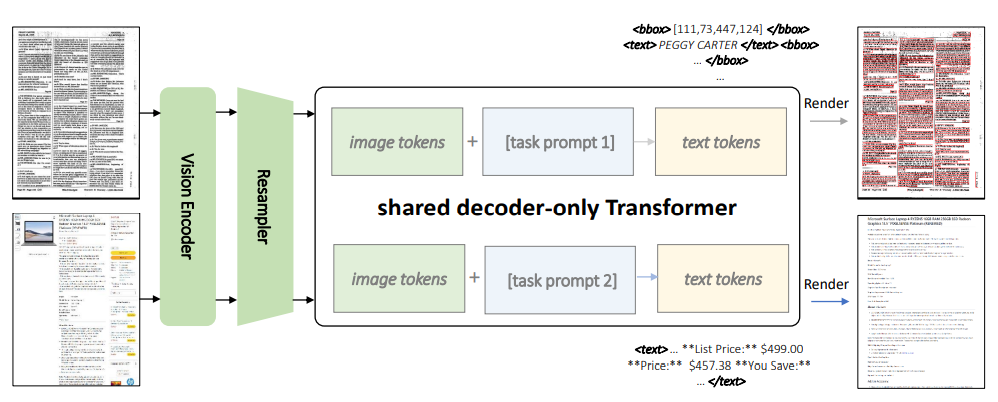
The above picture exhibits the Mannequin structure of KOSMOS-2.5. The efficiency of KOSMOS-2.5 is evaluated throughout two major duties: end-to-end document-level textual content recognition and the era of textual content from pictures in markdown format. Experimental outcomes have showcased its sturdy efficiency in understanding text-intensive picture duties. Moreover, KOSMOS-2.5 displays promising capabilities in situations involving few-shot and zero-shot studying, making it a flexible device for real-world functions that cope with text-rich pictures.
Regardless of these promising outcomes, the present mannequin faces some limitations, providing useful future analysis instructions. As an illustration, KOSMOS-2.5 presently doesn’t help fine-grained management of doc components’ positions utilizing pure language directions, regardless of being pre-trained on inputs and outputs involving the spatial coordinates of textual content. Within the broader analysis panorama, a big route lies in furthering the event of mannequin scaling capabilities.
Try the Paper and Challenge. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to hitch our 30k+ ML SubReddit, 40k+ Fb Neighborhood, Discord Channel, and E mail E-newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
In case you like our work, you’ll love our e-newsletter..
Janhavi Lande, is an Engineering Physics graduate from IIT Guwahati, class of 2023. She is an upcoming information scientist and has been working on the planet of ml/ai analysis for the previous two years. She is most fascinated by this ever altering world and its fixed demand of people to maintain up with it. In her pastime she enjoys touring, studying and writing poems.