
{kind=link}

Picture by Writer
In a world the place information is the brand new oil, understanding the nuances of a profession in information science is extra essential than ever. Whether or not you’re a information fanatic trying or a veteran exploring alternatives, utilizing SQL can provide insights into the information science job market.
I hope you’re wanting to know which information science job titles are essentially the most engaging, or which of them provide the beefiest paychecks. Or maybe, you are questioning how expertise ranges tie into information science common salaries?
On this article, now we have obtained all these questions (and extra) coated as we go deep into the information science job market. Let’s begin!
The dataset that we are going to use on this article is designed to make clear wage patterns within the Information Science discipline from 2021 to 2023. By spotlighting components equivalent to work historical past, job positions, and company areas, it presents essential insights into wage dispersion within the sector.
This text will discover a solution to the next questions:
- What Does the Common Wage Look Like Throughout Totally different Expertise Ranges?
- What are the Most Widespread Job Titles in Information Science?
- How Does Wage Distribution Differ with Firm Measurement?
- The place are Information Science Jobs Primarily Positioned Geographically?
- Which Job Titles Supply the Prime Salaries in Information Science?
You’ll be able to obtain this information from the Kaggle.
1. What Does the Common Wage Look Like Throughout Totally different Expertise Ranges?
On this SQL question, we’re discovering the common wage for various expertise ranges. The GROUP BY clause teams the information by expertise degree and the AVG perform calculates the common wage for every group.
This helps to grasp how expertise within the discipline influences the incomes potential, which is important for you whereas planning your profession paths in information science. Let’s see the code.
SELECT experience_level, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY experience_level;
Now let’s visualize this output by utilizing Python.
Right here is the code.
# Import required libraries for plotting
import matplotlib.pyplot as plt
import seaborn as sns
# Arrange the fashion for the graphs
sns.set(fashion="whitegrid")
# Initialize the listing for storing graphs
graphs = []
plt.determine(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', information=df, estimator=lambda x: sum(x) / len(x))
plt.title('Common Wage by Expertise Degree')
plt.xlabel('Expertise Degree')
plt.ylabel('Common Wage (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.present()
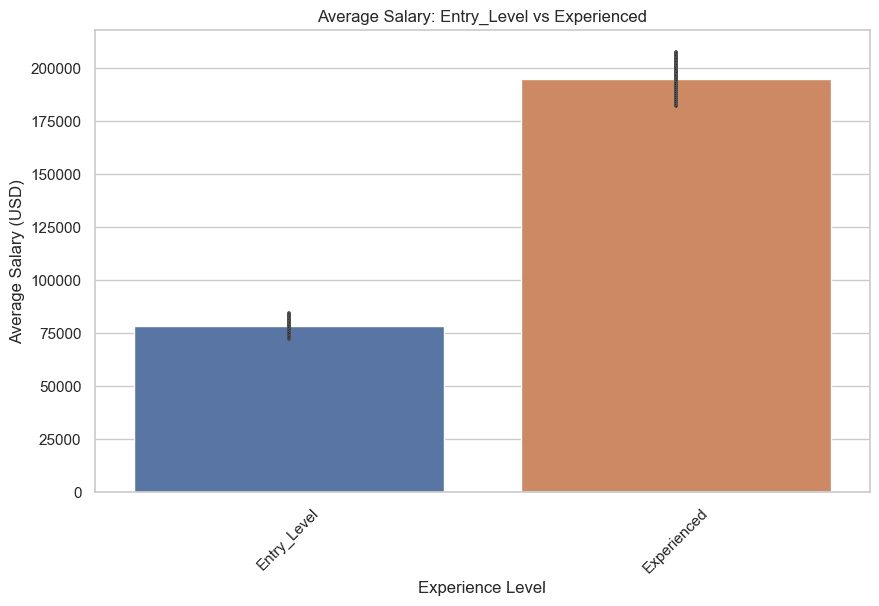
Now let’s examine, entry-level & skilled and mid-level & senior salaries.
Let’s begin with entry-level & skilled. Right here is the code.
# Filter the information for Entry_Level and Skilled ranges
entry_experienced = df[df['experience_level'].isin(['Entry_Level', 'Experienced'])]
# Filter the information for Mid-Degree and Senior ranges
mid_senior = df[df['experience_level'].isin(['Mid-Level', 'Senior'])]
# Plotting the Entry_Level vs Skilled graph
plt.determine(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', information=entry_experienced, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Common Wage: Entry_Level vs Skilled')
plt.xlabel('Expertise Degree')
plt.ylabel('Common Wage (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.present()
Right here is the graph.
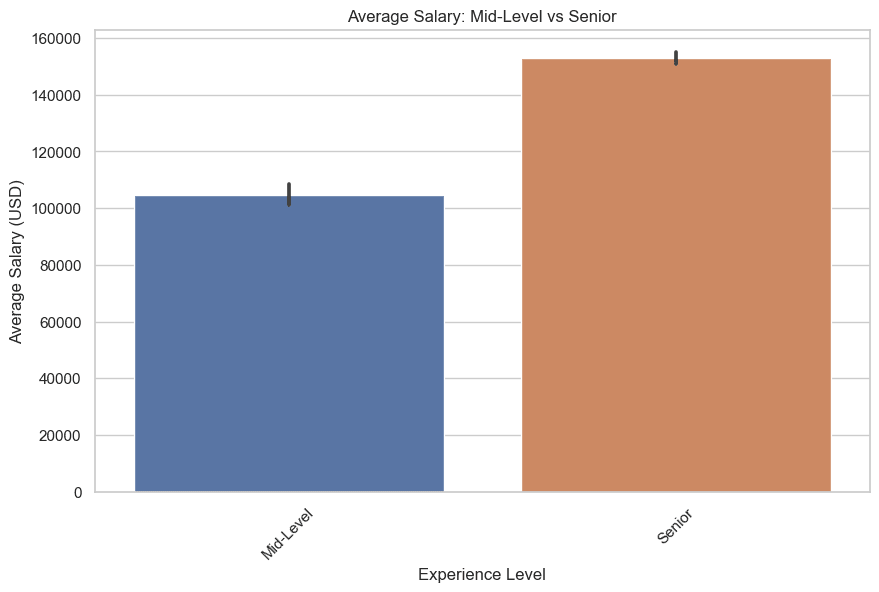
Now let’s draw, mid-level & senior. Right here is the code.
# Plotting the Mid-Degree vs Senior graph
plt.determine(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', information=mid_senior, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Common Wage: Mid-Degree vs Senior')
plt.xlabel('Expertise Degree')
plt.ylabel('Common Wage (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.present()
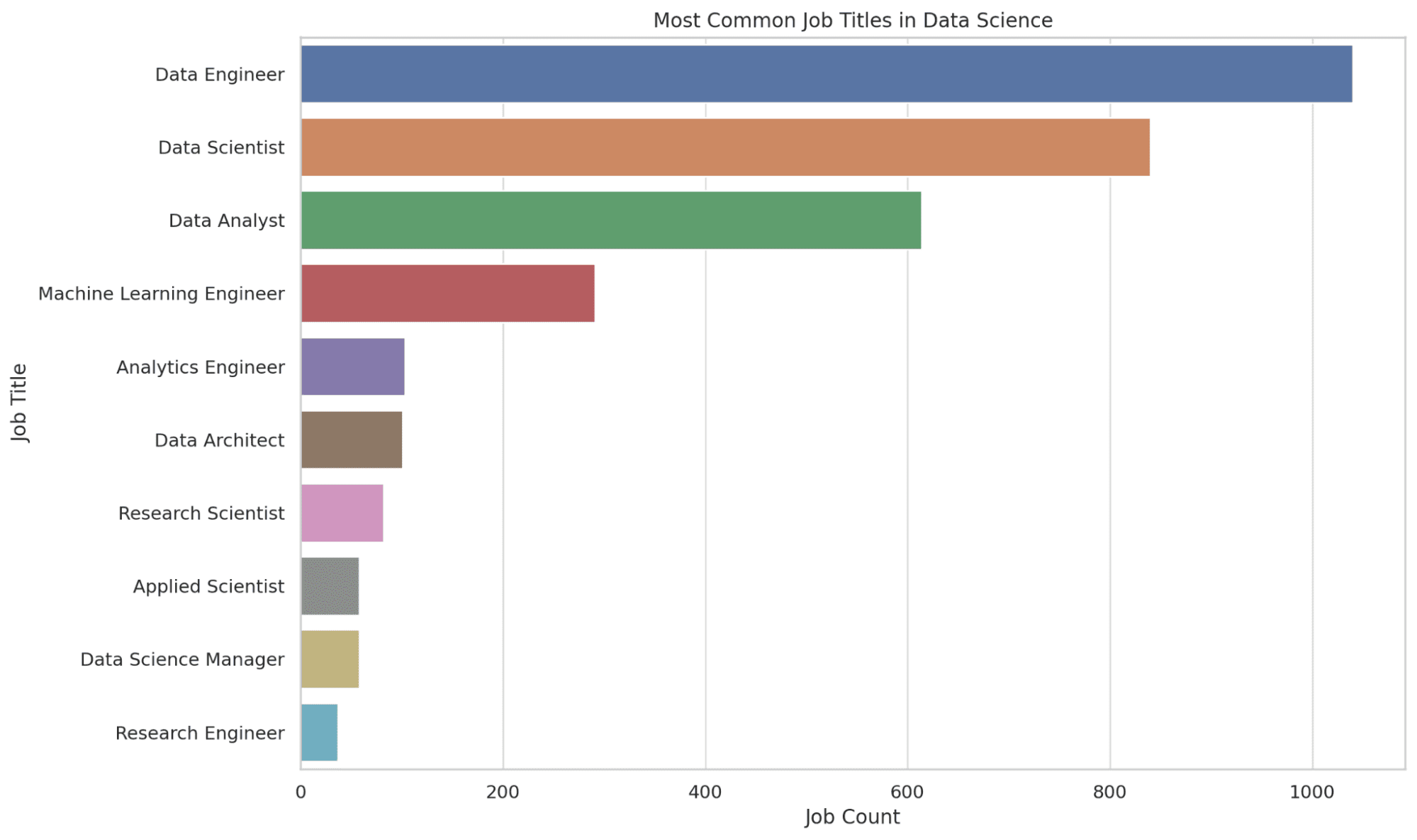
2. What are the Most Widespread Job Titles in Information Science?
Right here, we extract the highest 10 most typical job titles in information science. The COUNT perform counts the variety of occurrences of every job title, and the outcomes are ordered in descending order to get the most typical titles on the high.
This data offers you a way of the job market demand, guiding you in figuring out potential roles you may goal. Let’s see the code.
SELECT job_title, COUNT(*) AS job_count
FROM salary_data
GROUP BY job_title
ORDER BY job_count DESC
LIMIT 10;
Okay, it’s time to visualize this question by utilizing Python.
Right here is the code.
plt.determine(figsize=(12, 8))
sns.countplot(y='job_title', information=df, order=df['job_title'].value_counts().index[:10])
plt.title('Most Widespread Job Titles in Information Science')
plt.xlabel('Job Depend')
plt.ylabel('Job Title')
graphs.append(plt.gcf())
plt.present()
Let’s see the graph.
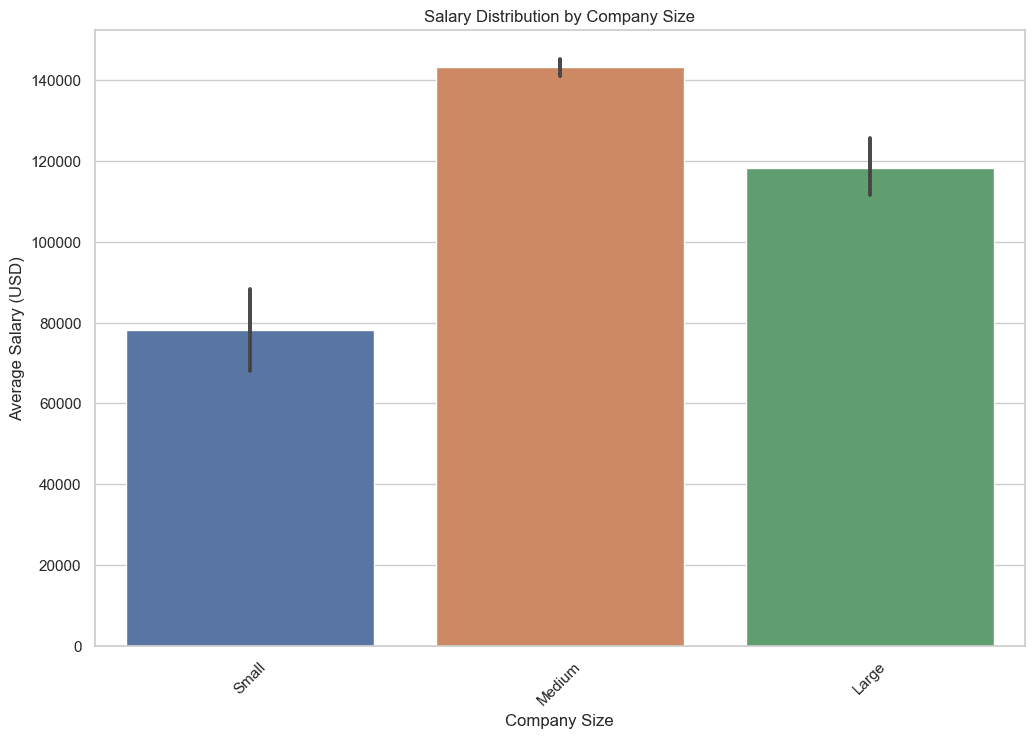
3. How Does Wage Distribution Differ with Firm Measurement?
On this question, we extract the common, minimal, and most salaries for every firm dimension grouping. Utilizing combination features equivalent to AVG, MIN, and MAX helps to supply a complete view of the wage panorama in relation to the dimensions of an organization.
This information is important because it helps you perceive the potential earnings you may anticipate relying on the dimensions of the corporate you need to be part of, let’s see the code.
SELECT company_size, AVG(salary_in_usd) AS avg_salary, MIN(salary_in_usd) AS min_salary, MAX(salary_in_usd) AS max_salary
FROM salary_data
GROUP BY company_size;
Now let’s visualize this question, by utilizing Python.
Right here is the code.
plt.determine(figsize=(12, 8))
sns.barplot(x='company_size', y='salary_in_usd', information=df, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0, order=['Small', 'Medium', 'Large'])
plt.title('Wage Distribution by Firm Measurement')
plt.xlabel('Firm Measurement')
plt.ylabel('Common Wage (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.present()
Right here is the output.
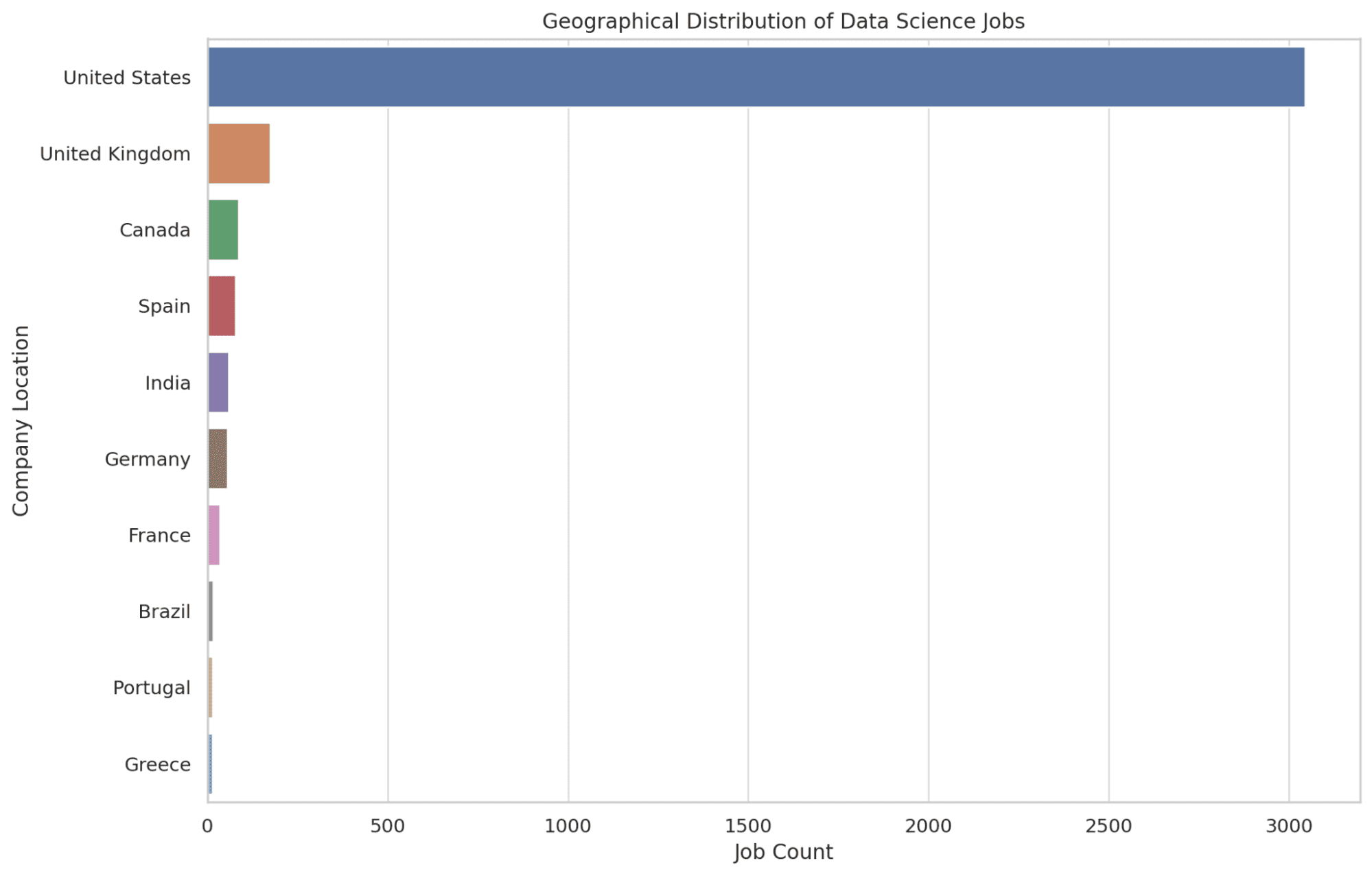
4. The place are Information Science Jobs Primarily Positioned Geographically?
Right here, we pinpoint the highest 10 areas holding the very best variety of information science job alternatives. We use the COUNT perform to find out the variety of job postings in every location, arranging them in descending order to highlight the areas with essentially the most alternatives.
Having this data equips readers with information of the geographical areas which are hubs for information science roles, aiding in potential relocation selections. Let’s see the code.
SELECT company_location, COUNT(*) AS job_count
FROM salary_data
GROUP BY company_location
ORDER BY job_count DESC
LIMIT 10;
Now let’s create graphs of the code above, with Python.
plt.determine(figsize=(12, 8))
sns.countplot(y='company_location', information=df, order=df['company_location'].value_counts().index[:10])
plt.title('Geographical Distribution of Information Science Jobs')
plt.xlabel('Job Depend')
plt.ylabel('Firm Location')
graphs.append(plt.gcf())
plt.present()
Let’s see the graph beneath.
5. Which Job Titles Supply the Prime Salaries in Information Science?
Right here, we’re figuring out the highest 10 highest-paying job titles within the information science sector. Through the use of the AVG, we calculate the common wage for every job title, sorting them in descending order based mostly on the common wage to spotlight essentially the most profitable positions.
You’ll be able to aspire to in your profession journey, by taking a look at this information. Let’s proceed to grasp how readers can create a Python visualization for this information.
SELECT job_title, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY job_title
ORDER BY avg_salary DESC
LIMIT 10;
Right here is the output.
(Right here we can’t use pictures, as a result of we added 4 pictures above, and one left for a thumbnail, Do now we have an opportunity to make use of a desk like beneath to reveal the output?)
| Rank | Job Title | Common Wage (USD) |
| 1 | Information Science Tech Lead | 375,000.00 |
| 2 | Cloud Information Architect | 250,000.00 |
| 3 | Information Lead | 212,500.00 |
| 4 | Information Analytics Lead | 211,254.50 |
| 5 | Principal Information Scientist | 198,171.13 |
| 6 | Director of Information Science | 195,140.73 |
| 7 | Principal Information Engineer | 192,500.00 |
| 8 | Machine Studying Software program Engineer | 192,420.00 |
| 9 | Information Science Supervisor | 191,278.78 |
| 10 | Utilized Scientist | 190,264.48 |
This time, let’s attempt to create a graph by your self.
Suggestions: You should utilize the next immediate in ChatGPT to generate a Pythonic code of this graph:
<SQL Question right here>
Create a Python graph to visualise the highest 10 highest-paying job titles in Information Science, just like the insights gathered from the given SQL question above.
As we wrap up our journey by the varied terrains of the information science profession world, we hope SQL proves to be a reliable information, serving to you unearth gems of insights to assist your profession selections.
I hope that you simply really feel extra outfitted now, not simply in mapping your profession path, but additionally in utilizing SQL in shaping uncooked information into highly effective narratives. So here is to stepping right into a future full of alternatives, with information as your compass and SQL as your guiding pressure!
Thanks for studying!
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from high firms. Join with him on Twitter: StrataScratch or LinkedIn.