
{kind=link}
Immediately, we’re comfortable to function a visitor publish written by Juan Cruz, exhibiting find out how to use Auto-Keras from R. Juan holds a grasp’s diploma in Laptop Science. At present, he’s ending his grasp’s diploma in Utilized Statistics, in addition to a Ph.D. in Laptop Science, on the Universidad Nacional de Córdoba. He began his R journey virtually six years in the past, making use of statistical strategies to biology information. He enjoys software program initiatives centered on making machine studying and information science obtainable to everybody.
Prior to now few years, synthetic intelligence has been a topic of intense media hype. Machine studying, deep studying, and synthetic intelligence come up in numerous articles, typically outdoors of technology-minded publications. For many any matter, a quick search on the internet yields dozens of texts suggesting the appliance of 1 or the opposite deep studying mannequin.
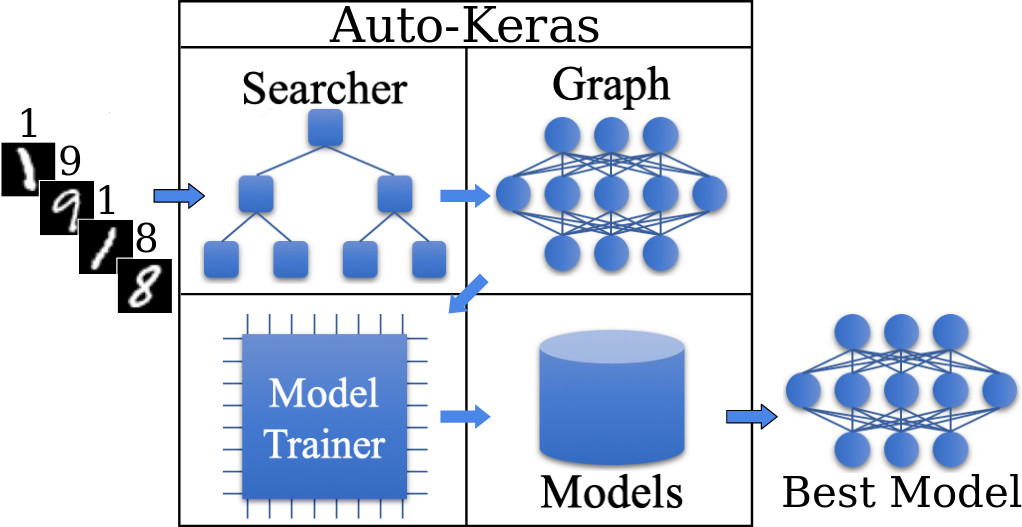
Nonetheless, duties comparable to function engineering, hyperparameter tuning, or community design, are in no way straightforward for individuals with no wealthy pc science background. Currently, analysis began to emerge within the space of what’s often called Neural Structure Search (NAS) (Baker et al. 2016; Pham et al. 2018; Zoph and Le 2016; Luo et al. 2018; Liu et al. 2017; Actual et al. 2018; Jin, Music, and Hu 2018). The primary purpose of NAS algorithms is, given a selected tagged dataset, to seek for probably the most optimum neural community to carry out a sure process on that dataset. On this sense, NAS algorithms permit the person to not have to fret about any process associated to information science engineering. In different phrases, given a tagged dataset and a process, e.g., picture classification, or textual content classification amongst others, the NAS algorithm will practice a number of high-performance deep studying fashions and return the one which outperforms the remaining.
A number of NAS algorithms have been developed on completely different platforms (e.g. Google Cloud AutoML), or as libraries of sure programming languages (e.g. Auto-Keras, TPOT, Auto-Sklearn). Nonetheless, for a language that brings collectively consultants from such numerous disciplines as is the R programming language, to the perfect of our information, there isn’t a NAS instrument to today. On this publish, we current the Auto-Keras R bundle, an interface from R to the Auto-Keras Python library (Jin, Music, and Hu 2018). Due to using Auto-Keras, R programmers with few traces of code will be capable of practice a number of deep studying fashions for his or her information and get the one which outperforms the others.
Let’s dive into Auto-Keras!
Auto-Keras
Be aware: the Python Auto-Keras library is barely appropriate with Python 3.6. So be sure that this model is at the moment put in, and appropriately set for use by the reticulate R library.
Set up
To start, set up the autokeras R bundle from GitHub as follows:
The Auto-Keras R interface makes use of the Keras and TensorFlow backend engines by default. To put in each the core Auto-Keras library in addition to the Keras and TensorFlow backends use the install_autokeras() operate:
This may give you default CPU-based installations of Keras and TensorFlow. If you’d like a extra custom-made set up, e.g. if you wish to reap the benefits of NVIDIA GPUs, see the documentation for install_keras() from the keras R library.
MNIST Instance
We will study the fundamentals of Auto-Keras by strolling by means of a easy instance: recognizing handwritten digits from the MNIST dataset. MNIST consists of 28 x 28 grayscale photographs of handwritten digits like this:

The dataset additionally contains labels for every picture, telling us which digit it’s. For instance, the label for the above picture is 2.
Loading the Information
The MNIST dataset is included with Keras and could be accessed utilizing the dataset_mnist() operate from the keras R library. Right here we load the dataset, after which create variables for our check and coaching information:
The x information is a 3-D array (photographs,width,top) of grayscale integer values ranging between 0 to 255.
x_train[1, 14:20, 14:20] # present some pixels from the primary picture [,1] [,2] [,3] [,4] [,5] [,6] [,7]
[1,] 241 225 160 108 1 0 0
[2,] 81 240 253 253 119 25 0
[3,] 0 45 186 253 253 150 27
[4,] 0 0 16 93 252 253 187
[5,] 0 0 0 0 249 253 249
[6,] 0 46 130 183 253 253 207
[7,] 148 229 253 253 253 250 182The y information is an integer vector with values starting from 0 to 9.
n_imgs <- 8
head(y_train, n = n_imgs) # present first 8 labels[1] 5 0 4 1 9 2 1 3Every of those photographs could be plotted in R:
library("ggplot2")
library("tidyr")
# get every of the primary n_imgs from the x_train dataset and
# convert them to broad format
mnist_to_plot <-
do.name(rbind, lapply(seq_len(n_imgs), operate(i) {
samp_img <- x_train[i, , ] %>%
as.information.body()
colnames(samp_img) <- seq_len(ncol(samp_img))
information.body(
img = i,
collect(samp_img, "x", "worth", convert = TRUE),
y = seq_len(nrow(samp_img))
)
}))
ggplot(mnist_to_plot, aes(x = x, y = y, fill = worth)) + geom_tile() +
scale_fill_gradient(low = "black", excessive = "white", na.worth = NA) +
scale_y_reverse() + theme_minimal() + theme(panel.grid = element_blank()) +
theme(facet.ratio = 1) + xlab("") + ylab("") + facet_wrap(~img, nrow = 2)
Information prepared, let’s get the mannequin!
Information pre-processing? Mannequin definition? Metrics, epochs definition, anybody? No, none of them are required by Auto-Keras. For picture classification duties, it’s sufficient for Auto-Keras to be handed the x_train and y_train objects as outlined above.
So, to coach a number of deep studying fashions for 2 hours, it is sufficient to run:
# practice an Picture Classifier for 2 hours
clf <- model_image_classifier(verbose = TRUE) %>%
match(x_train, y_train, time_limit = 2 * 60 * 60)Saving Listing: /tmp/autokeras_ZOG76O
Preprocessing the photographs.
Preprocessing completed.
Initializing search.
Initialization completed.
+----------------------------------------------+
| Coaching mannequin 0 |
+----------------------------------------------+
No loss lower after 5 epochs.
Saving mannequin.
+--------------------------------------------------------------------------+
| Mannequin ID | Loss | Metric Worth |
+--------------------------------------------------------------------------+
| 0 | 0.19463148526847363 | 0.9843999999999999 |
+--------------------------------------------------------------------------+
+----------------------------------------------+
| Coaching mannequin 1 |
+----------------------------------------------+
No loss lower after 5 epochs.
Saving mannequin.
+--------------------------------------------------------------------------+
| Mannequin ID | Loss | Metric Worth |
+--------------------------------------------------------------------------+
| 1 | 0.210642946138978 | 0.984 |
+--------------------------------------------------------------------------+Consider it:
clf %>% consider(x_test, y_test)[1] 0.9866After which simply get the best-trained mannequin with:
clf %>% final_fit(x_train, y_train, x_test, y_test, retrain = TRUE)No loss lower after 30 epochs.Consider the ultimate mannequin:
clf %>% consider(x_test, y_test)[1] 0.9918And the mannequin could be saved to take it into manufacturing with:
clf %>% export_autokeras_model("./myMnistModel.pkl")Conclusions
On this publish, the Auto-Keras R bundle was offered. It was proven that, with virtually no deep studying information, it’s attainable to coach fashions and get the one which returns the perfect outcomes for the specified process. Right here we skilled fashions for 2 hours. Nonetheless, we’ve got additionally tried coaching for twenty-four hours, leading to 15 fashions being skilled, to a ultimate accuracy of 0.9928. Though Auto-Keras won’t return a mannequin as environment friendly as one generated manually by an knowledgeable, this new library has its place as a wonderful start line on the planet of deep studying. Auto-Keras is an open-source R bundle, and is freely obtainable in https://github.com/jcrodriguez1989/autokeras/.
Though the Python Auto-Keras library is at the moment in a pre-release model and comes with not too many sorts of coaching duties, that is more likely to change quickly, because the venture it was lately added to the keras-team set of repositories. This may undoubtedly additional its progress so much.
So keep tuned, and thanks for studying!
Reproducibility
To appropriately reproduce the outcomes of this publish, we advocate utilizing the Auto-Keras docker picture by typing:
docker pull jcrodriguez1989/r-autokeras:0.1.0
docker run -it jcrodriguez1989/r-autokeras:0.1.0 /bin/bashBaker, Bowen, Otkrist Gupta, Nikhil Naik, and Ramesh Raskar. 2016. “Designing Neural Community Architectures Utilizing Reinforcement Studying.” arXiv Preprint arXiv:1611.02167.
Jin, Haifeng, Qingquan Music, and Xia Hu. 2018. “Auto-Keras: An Environment friendly Neural Structure Search System.” arXiv Preprint arXiv:1806.10282.
Liu, Hanxiao, Karen Simonyan, Oriol Vinyals, Chrisantha Fernando, and Koray Kavukcuoglu. 2017. “Hierarchical Representations for Environment friendly Structure Search.” arXiv Preprint arXiv:1711.00436.
Luo, Renqian, Fei Tian, Tao Qin, Enhong Chen, and Tie-Yan Liu. 2018. “Neural Structure Optimization.” In Advances in Neural Info Processing Programs, 7816–27.
Pham, Hieu, Melody Y Guan, Barret Zoph, Quoc V Le, and Jeff Dean. 2018. “Environment friendly Neural Structure Search through Parameter Sharing.” arXiv Preprint arXiv:1802.03268.
Actual, Esteban, Alok Aggarwal, Yanping Huang, and Quoc V Le. 2018. “Regularized Evolution for Picture Classifier Structure Search.” arXiv Preprint arXiv:1802.01548.
Zoph, Barret, and Quoc V Le. 2016. “Neural Structure Search with Reinforcement Studying.” arXiv Preprint arXiv:1611.01578.