
{kind=link}

Picture by Writer
In machine studying, unsupervised studying is a paradigm that entails coaching an algorithm on an unlabeled dataset. So there’s no supervision or labeled outputs.
In unsupervised studying, the purpose is to find patterns, buildings, or relationships throughout the knowledge itself, relatively than predicting or classifying primarily based on labeled examples. It entails exploring the inherent construction of the information to achieve insights and make sense of advanced data.
This information will introduce you to unsupervised studying. We’ll begin by going over the variations between supervised and unsupervised studying—to put the bottom for the rest of the dialogue. We’ll then cowl the important thing unsupervised studying methods and the favored algorithms inside them.
Supervised and unsupervised machine studying are two totally different approaches used within the subject of synthetic intelligence and knowledge evaluation. Here is a quick abstract of their key variations:
Coaching Information
In supervised studying, the algorithm is skilled on a labeled dataset, the place enter knowledge is paired with corresponding desired output (labels or goal values).
Unsupervised studying, however, entails working with an unlabeled dataset, the place there aren’t any predefined output labels.
Goal
The purpose of supervised studying algorithms is to be taught a relationship—a mapping—from the enter to the output house. As soon as the mapping is discovered, we will use the mannequin to foretell the output values or class label for unseen knowledge factors.
In unsupervised studying, the purpose is to discover patterns, buildings, or relationships throughout the knowledge, usually for clustering knowledge factors into teams, exploratory evaluation or characteristic extraction.
Widespread Duties
Classification (assigning a category label—one of many many predefined classes—to a beforehand unseen knowledge level) and regression (predicting steady values) are frequent duties in supervised studying.
Clustering (grouping comparable knowledge factors) and dimensionality discount (decreasing the variety of options whereas preserving essential data) are frequent duties in unsupervised studying. We’ll talk about these in better element shortly.
When To Use
Supervised studying is extensively used when the specified output is understood and well-defined, corresponding to spam electronic mail detection, picture classification, and medical analysis.
Unsupervised studying is used when there may be restricted or no prior information in regards to the knowledge and the target is to uncover hidden patterns or acquire insights from the information itself.
Right here’s a abstract of the variations:
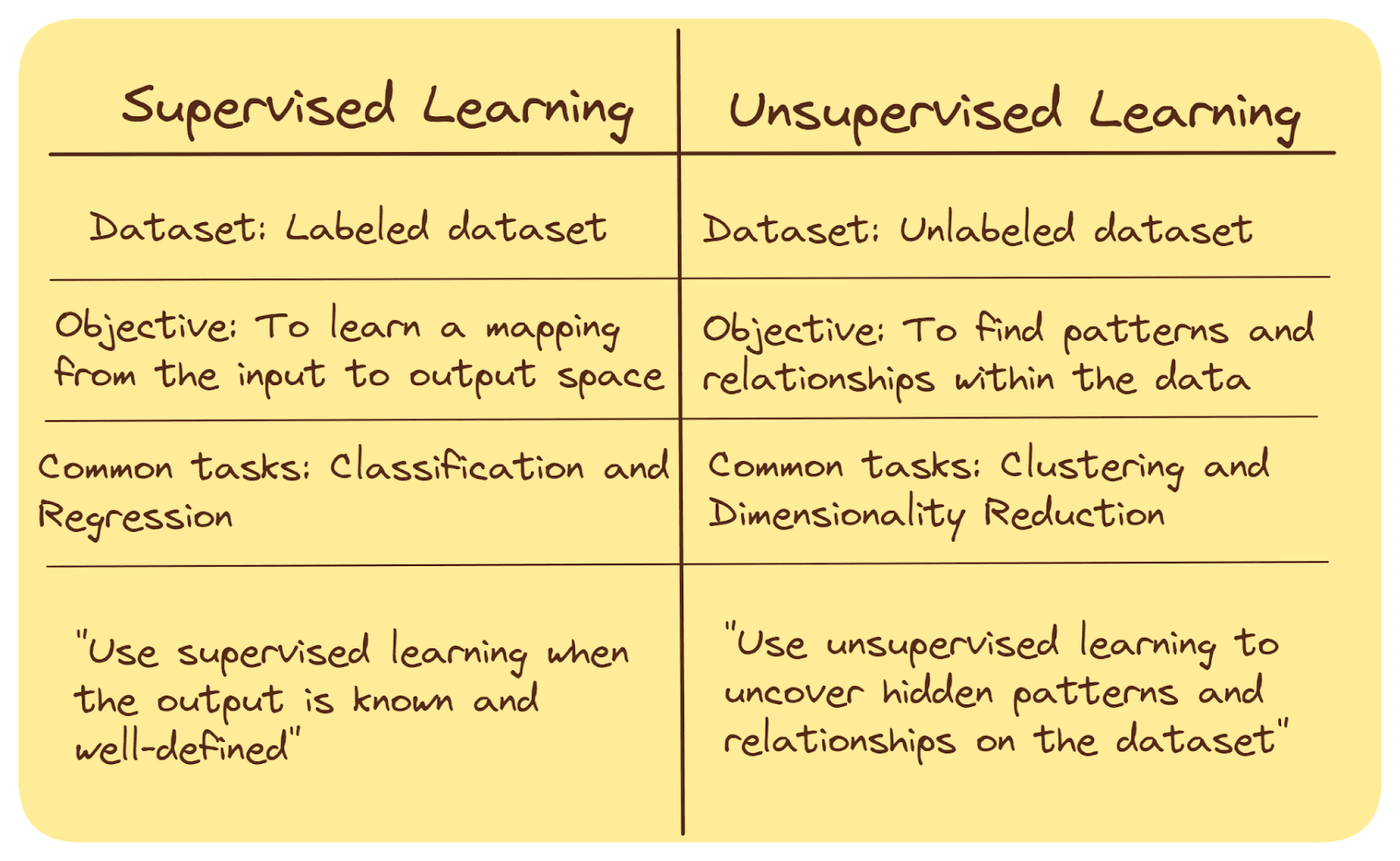
Supervised vs. Unsupervised Studying | Picture by Writer
Summing up: Supervised studying focuses on studying from labeled knowledge to make predictions or classifications, whereas unsupervised studying seeks to find patterns and relationships inside unlabeled knowledge. Each approaches have their very own purposes—primarily based on the character of the information and the issue at hand.
As mentioned, in unsupervised studying, we’ve got the enter knowledge and are tasked with discovering significant patterns or representations inside that knowledge. Unsupervised studying algorithms achieve this by figuring out similarities, variations, and relationships among the many knowledge factors with out being supplied with predefined classes or labels.
For this dialogue, we’ll go over the 2 foremost unsupervised studying methods:
- Clustering
- Dimensionality Discount
What Is Clustering?
Clustering entails grouping comparable knowledge factors collectively into clusters primarily based on some similarity measure. The algorithm goals to search out pure teams or classes throughout the knowledge the place knowledge factors in the identical cluster are extra comparable to one another than to these in different clusters.
As soon as we’ve got the dataset grouped into totally different clusters we will primarily label them. And if wanted, we will carry out supervised studying on the clustered dataset.
What Is Dimensionality Discount?
Dimensionality discount refers to methods that cut back the variety of options—dimensions—within the knowledge whereas preserving essential data. Excessive-dimensional knowledge will be advanced and tough to work with, so dimensionality discount helps in simplifying the information for evaluation.
Each clustering and dimensionality discount are highly effective methods in unsupervised studying, offering precious insights and simplifying advanced knowledge for additional evaluation or modeling.
Within the the rest of the article, let’s evaluate essential clustering and dimensionality discount algorithms.
As mentioned, clustering is a elementary approach in unsupervised studying that entails grouping comparable knowledge factors collectively into clusters, the place knowledge factors throughout the similar cluster are extra comparable to one another than to these in different clusters. Clustering helps establish pure divisions throughout the knowledge, which might present insights into patterns and relationships.
There are numerous algorithms used for clustering, every with its personal strategy and traits:
Okay-Means Clustering
Okay-Means clustering is a straightforward, strong, and generally used algorithm. It partitions the information right into a predefined variety of clusters (Okay) by iteratively updating cluster centroids primarily based on the imply of information factors inside every cluster.
It iteratively refines cluster assignments till convergence.
Right here’s how the Okay-Means clustering algorithm works:
- Initialize Okay cluster centroids.
- Assign every knowledge level—primarily based on the chosen distance metric—to the closest cluster centroid.
- Replace centroids by computing the imply of information factors in every cluster.
- Repeat steps 2 and three till convergence or an outlined variety of iterations.
Hierarchical Clustering
Hierarchical clustering creates a tree-like construction—a dendrogram—of information factors, capturing similarities at a number of ranges of granularity. Agglomerative clustering is essentially the most generally used hierarchical clustering algorithm. It begins with particular person knowledge factors as separate clusters and step by step merges them primarily based on a linkage criterion, corresponding to distance or similarity.
Right here’s how the agglomerative clustering algorithm works:
- Begin with `n` clusters: every knowledge level as its personal cluster.
- Merge closest knowledge factors/clusters into a bigger cluster.
- Repeat 2. till a single cluster stays or an outlined variety of clusters is reached.
- The outcome will be interpreted with the assistance of a dendrogram.
Density-Based mostly Spatial Clustering of Purposes with Noise (DBSCAN)
DBSCAN identifies clusters primarily based on the density of information factors in a neighborhood. It will possibly discover arbitrarily formed clusters and also can establish noise factors and detect outliers.
The algorithm entails the next (simplified to incorporate the important thing steps):
- Choose a knowledge level and discover its neighbors inside a specified radius.
- If the purpose has ample neighbors, increase the cluster by together with the neighbors of its neighbors.
- Repeat for all factors, forming clusters linked by density.
Dimensionality discount is the method of decreasing the variety of options (dimensions) in a dataset whereas retaining important data. Excessive-dimensional knowledge will be advanced, computationally costly, and is susceptible to overfitting. Dimensionality discount algorithms assist simplify knowledge illustration and visualization.
Principal Element Evaluation (PCA)
Principal Element Evaluation—or PCA—transforms knowledge into a brand new coordinate system to maximise variance alongside the principal elements. It reduces knowledge dimensions whereas preserving as a lot variance as potential.
Right here’s how one can carry out PCA for dimensionality discount:
- Compute the covariance matrix of the enter knowledge.
- Carry out eigenvalue decomposition on the covariance matrix. Compute the eigenvectors and eigenvalues of the covariance matrix.
- Kind eigenvectors by eigenvalues in descending order.
- Challenge knowledge onto the eigenvectors to create a lower-dimensional illustration.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
The primary time I used t-SNE was to visualise phrase embeddings. t-SNE is used for visualization by decreasing high-dimensional knowledge to a lower-dimensional illustration whereas sustaining native pairwise similarities.
Here is how t-SNE works:
- Assemble chance distributions to measure pairwise similarities between knowledge factors in high-dimensional and low-dimensional areas.
- Decrease the divergence between these distributions utilizing gradient descent. Iteratively transfer knowledge factors within the lower-dimensional house, adjusting their positions to reduce the associated fee perform.
As well as, there are deep studying architectures corresponding to autoencoders that can be utilized for dimensionality discount. Autoencoders are neural networks designed to encode after which decode knowledge, successfully studying a compressed illustration of the enter knowledge.
Let’s discover some purposes of unsupervised studying. Listed below are some examples:
Buyer Segmentation
In advertising and marketing, companies use unsupervised studying to phase their buyer base into teams with comparable behaviors and preferences. This helps tailor advertising and marketing methods, campaigns, and product choices. For instance, retailers categorize clients into teams corresponding to “price range customers,” “luxurious patrons,” and “occasional purchasers.”
Doc Clustering
You may run a clustering algorithm on a corpus of paperwork. This helps group comparable paperwork collectively, aiding in doc group, search, and retrieval.
Anomaly Detection
Unsupervised studying can be utilized to establish uncommon and weird patterns—anomalies—in knowledge. Anomaly detection has purposes in fraud detection and community safety to detect uncommon—anomalous—conduct. Detecting fraudulent bank card transactions by figuring out uncommon spending patterns is a sensible instance.
Picture Compression
Clustering can be utilized for picture compression to rework pictures from high-dimensional shade house to a a lot decrease dimensional shade house. This reduces picture storage and transmission dimension by representing comparable pixel areas with a single centroid.
Social Community Evaluation
You may analyze social community knowledge—primarily based on person interactions—to uncover communities, influencers, and patterns of interplay.
Matter Modeling
In pure language processing, the duty of matter modeling is used to extract subjects from a group of textual content paperwork. This helps categorize and perceive the primary themes—subjects—inside a big textual content corpus.
Say, we’ve got a corpus of reports articles and we don’t have the paperwork and their corresponding classes beforehand. So we will carry out matter modeling on the gathering of reports articles to establish subjects corresponding to politics, expertise, and leisure.
Genomic Information Evaluation
Unsupervised studying additionally has purposes in biomedical and genomic knowledge evaluation. Examples embody clustering genes primarily based on their expression patterns to find potential associations with particular illnesses.
I hope this text helped you perceive the fundamentals of unsupervised studying. The following time you’re employed with a real-world dataset, strive to determine the training downside at hand. And attempt to assess if it may be modeled as a supervised or an unsupervised studying downside.
Should you’re working with a dataset with high-dimensional options, attempt to apply dimensionality discount earlier than constructing the machine studying mannequin. Continue to learn!
Bala Priya C is a developer and technical author from India. She likes working on the intersection of math, programming, knowledge science, and content material creation. Her areas of curiosity and experience embody DevOps, knowledge science, and pure language processing. She enjoys studying, writing, coding, and low! At the moment, she’s engaged on studying and sharing her information with the developer group by authoring tutorials, how-to guides, opinion items, and extra.