
{kind=link}

Picture generated utilizing Secure Diffusion
The world of AI has shifted dramatically in direction of generative modeling over the previous years, each in Pc Imaginative and prescient and Pure Language Processing. Dalle-2 and Midjourney have caught individuals’s consideration, main them to acknowledge the distinctive work being completed within the discipline of Generative AI.
A lot of the AI-generated photographs at the moment produced depend on Diffusion Fashions as their basis. The target of this text is to make clear a number of the ideas surrounding Secure Diffusion and supply a basic understanding of the methodology employed.
This flowchart exhibits the simplified model of a Secure Diffusion structure. We are going to undergo it piece by piece to construct a greater understanding of the interior workings. We are going to elaborate on the coaching course of for higher understanding, with the inference having just a few refined adjustments.
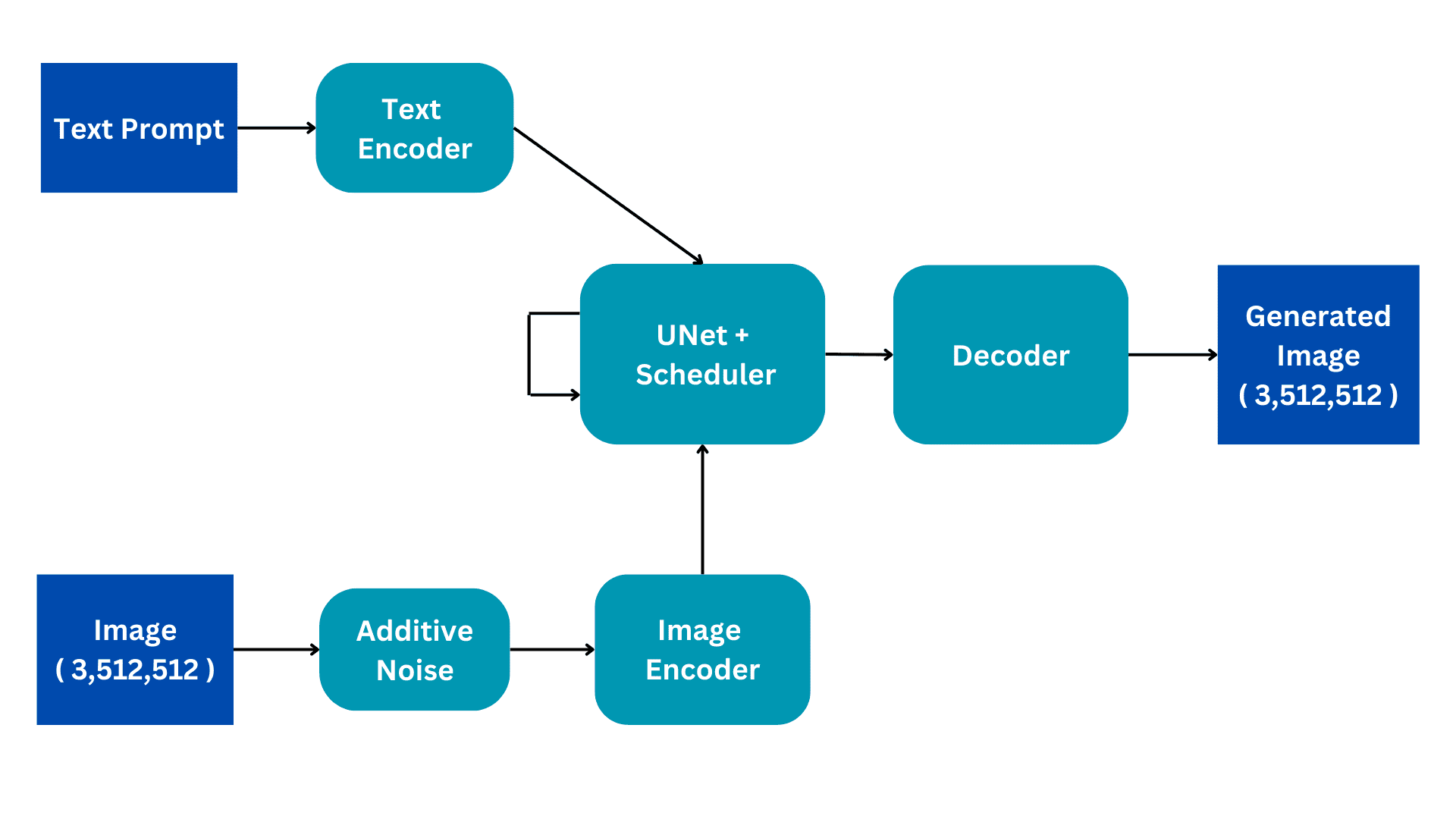
Picture by Creator
Inputs
The Secure Diffusion fashions are skilled on Picture Captioning datasets the place every picture has an related caption or immediate that describes the picture. There are due to this fact two inputs to the mannequin; a textual immediate in pure language and a picture of dimension (3,512,512) having 3 coloration channels and dimensions of dimension 512.
Additive Noise
The picture is transformed to finish noise by including Gaussian noise to the unique picture. That is performed in consequent steps, for instance, a small quantity is noise is added to the picture for 50 consecutive steps till the picture is totally noisy. The diffusion course of will intention to take away this noise and reproduce the unique picture. How that is performed shall be defined additional.
Picture Encoder
The Picture encoder capabilities as a element of a Variational AutoEncoder, changing the picture right into a ‘latent area’ and resizing it to smaller dimensions, equivalent to (4, 64, 64), whereas additionally together with a further batch dimension. This course of reduces computational necessities and enhances efficiency. Not like the unique diffusion fashions, Secure Diffusion incorporates the encoding step into the latent dimension, leading to decreased computation, in addition to decreased coaching and inference time.
Textual content Encoder
The pure language immediate is reworked right into a vectorized embedding by the textual content encoder. This course of employs a Transformer Language mannequin, equivalent to BERT or GPT-based CLIP Textual content fashions. Enhanced textual content encoder fashions considerably improve the standard of the generated photographs. The ensuing output of the textual content encoder consists of an array of 768-dimensional embedding vectors for every phrase. As a way to management the immediate size, a most restrict of 77 is about. Because of this, the textual content encoder produces a tensor with dimensions of (77, 768).
UNet
That is essentially the most computationally costly a part of the structure and important diffusion processing happens right here. It receives textual content encoding and noisy latent picture as enter. This module goals to breed the unique picture from the noisy picture it receives. It does this via a number of inference steps which may be set as a hyperparameter. Usually 50 inference steps are ample.
Think about a easy situation the place an enter picture undergoes a change into noise by regularly introducing small quantities of noise in 50 consecutive steps. This cumulative addition of noise ultimately transforms the unique picture into full noise. The target of the UNet is to reverse this course of by predicting the noise added on the earlier timestep. Throughout the denoising course of, the UNet begins by predicting the noise added on the fiftieth timestep for the preliminary timestep. It then subtracts this predicted noise from the enter picture and repeats the method. In every subsequent timestep, the UNet predicts the noise added on the earlier timestep, regularly restoring the unique enter picture from full noise. All through this course of, the UNet internally depends on the textual embedding vector as a conditioning issue.
The UNet outputs a tensor of dimension (4, 64, 64) that’s handed to the decoder a part of the Variational AutoEncoder.
Decoder
The decoder reverses the latent illustration conversion performed by the encoder. It takes a latent illustration and converts it again to picture area. Due to this fact, it outputs a (3,512,512) picture, the identical dimension as the unique enter area. Throughout coaching, we intention to reduce the loss between the unique picture and generated picture. On condition that, given a textual immediate, we will generate a picture associated to the immediate from a very noisy picture.
Throughout inference, we’ve got no enter picture. We work solely in text-to-image mode. We take away the Additive Noise half and as an alternative use a randomly generated tensor of the required dimension. The remainder of the structure stays the identical.
The UNet has undergone coaching to generate a picture from full noise, leveraging textual content immediate embedding. This particular enter is used through the inference stage, enabling us to efficiently generate artificial photographs from the noise. This normal idea serves as the elemental instinct behind all generative pc imaginative and prescient fashions.
Muhammad Arham is a Deep Studying Engineer working in Pc Imaginative and prescient and Pure Language Processing. He has labored on the deployment and optimizations of a number of generative AI purposes that reached the worldwide high charts at Vyro.AI. He’s eager about constructing and optimizing machine studying fashions for clever methods and believes in continuous enchancment.