
{kind=link}

Picture by Editor
Lately, the Giant Language Mannequin (LLM) has modified how individuals work and has been utilized in many fields, equivalent to training, advertising and marketing, analysis, and so on. Given the potential, LLM might be enhanced to unravel our enterprise issues higher. This is the reason we might carry out LLM fine-tuning.
We wish to fine-tune our LLM for a number of causes, together with adopting particular area use instances, enhancing the accuracy, knowledge privateness and safety, controlling the mannequin bias, and lots of others. With all these advantages, it’s important to discover ways to fine-tune our LLM to have one in manufacturing.
One option to carry out LLM fine-tuning robotically is by utilizing Hugging Face’s AutoTrain. The HF AutoTrain is a no-code platform with Python API to coach state-of-the-art fashions for numerous duties equivalent to Pc Imaginative and prescient, Tabular, and NLP duties. We will use the AutoTrain functionality even when we don’t perceive a lot concerning the LLM fine-tuning course of.
So, how does it work? Let’s discover additional.
Even when HF AutoTrain is a no-code answer, we will develop it on high of the AutoTrain utilizing Python API. We might discover the code routes because the no-code platform isn’t secure for coaching. Nevertheless, if you wish to use the no-code platform, We will create the AutoTrain house utilizing the next web page. The general platform will likely be proven within the picture under.
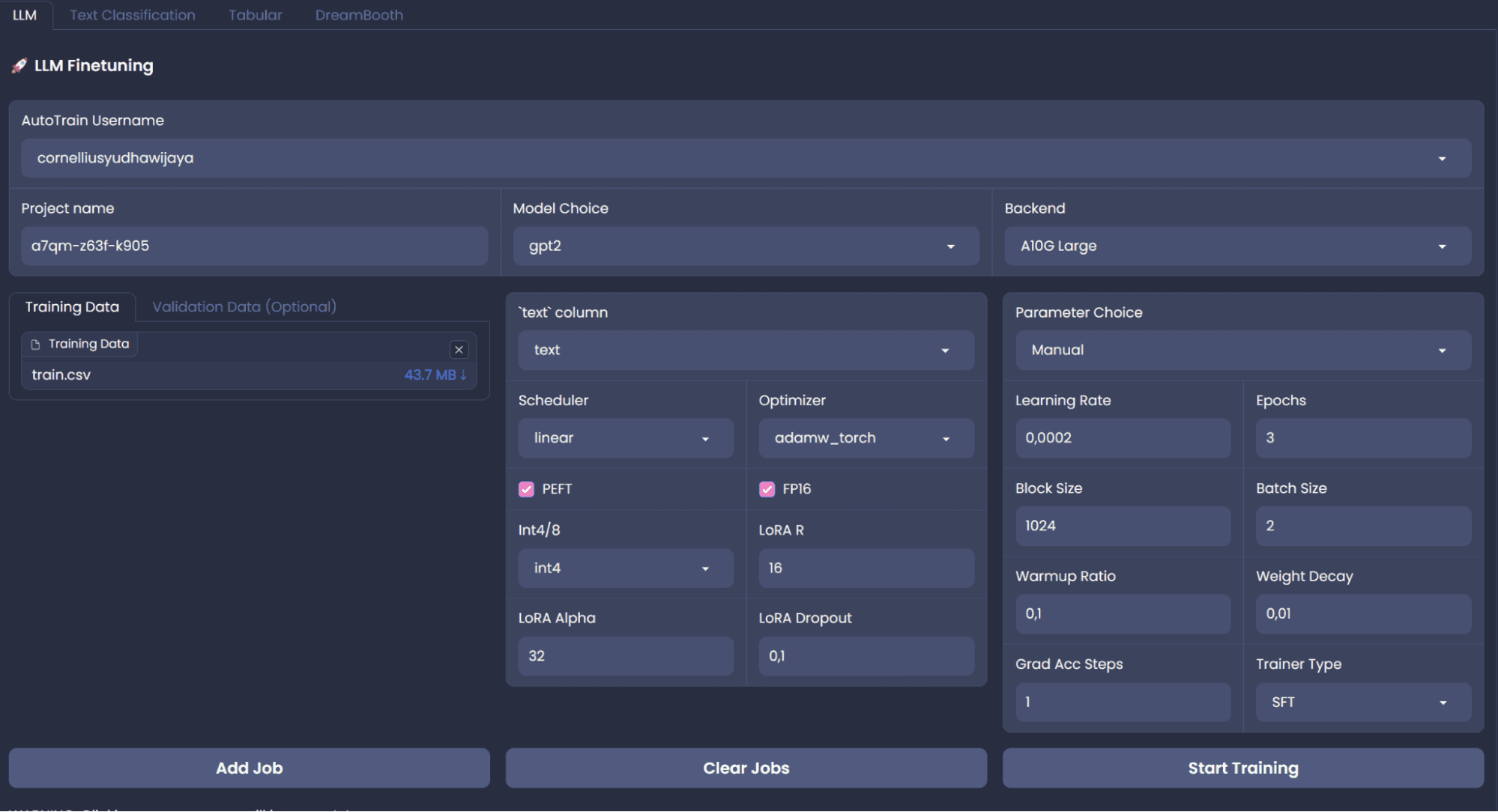
Picture by Writer
To fine-tune the LLM with Python API, we have to set up the Python bundle, which you’ll run utilizing the next code.
pip set up -U autotrain-advanced
Additionally, we might use the Alpaca pattern dataset from HuggingFace, which required datasets bundle to accumulate.
Then, use the next code to accumulate the information we’d like.
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("tatsu-lab/alpaca")
practice = dataset['train']
Moreover, we might save the information within the CSV format as we would want them for our fine-tuning.
practice.to_csv('practice.csv', index = False)
With the atmosphere and the dataset prepared, let’s attempt to use HuggingFace AutoTrain to fine-tune our LLM.
I might adapt the fine-tuning course of from the AutoTrain instance, which we will discover right here. To begin the method, we put the information we might use to fine-tune within the folder known as knowledge.

Picture by Writer
For this tutorial, I attempt to pattern solely 100 row knowledge so our coaching course of might be way more swifter. After we’ve our knowledge prepared, we might use our Jupyter Pocket book to fine-tune our mannequin. Ensure the information include ‘textual content’ column because the AutoTrain would learn from that column solely.
First, let’s run the AutoTrain setup utilizing the next command.
Subsequent, we would supply an data required for AutoTrain to run. For the next one is the details about the challenge title and the pre-trained mannequin you need. You may solely select the mannequin that was obtainable within the HuggingFace.
project_name="my_autotrain_llm"
model_name="tiiuae/falcon-7b"
Then we might add HF data, if you’d like push your mannequin to teh repository or utilizing a personal mannequin.
push_to_hub = False
hf_token = "YOUR HF TOKEN"
repo_id = "username/repo_name"
Lastly, we might provoke the mannequin parameter data within the variables under. You may change them as you prefer to see if the result’s good or not.
learning_rate = 2e-4
num_epochs = 4
batch_size = 1
block_size = 1024
coach = "sft"
warmup_ratio = 0.1
weight_decay = 0.01
gradient_accumulation = 4
use_fp16 = True
use_peft = True
use_int4 = True
lora_r = 16
lora_alpha = 32
lora_dropout = 0.045
With all the data is prepared, we might arrange the atmosphere to just accept all the data we’ve arrange beforehand.
import os
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["PUSH_TO_HUB"] = str(push_to_hub)
os.environ["HF_TOKEN"] = hf_token
os.environ["REPO_ID"] = repo_id
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["GRADIENT_ACCUMULATION"] = str(gradient_accumulation)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["USE_PEFT"] = str(use_peft)
os.environ["USE_INT4"] = str(use_int4)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)
To run the AutoTrain in our pocket book, we might use the next command.
!autotrain llm
--train
--model ${MODEL_NAME}
--project-name ${PROJECT_NAME}
--data-path knowledge/
--text-column textual content
--lr ${LEARNING_RATE}
--batch-size ${BATCH_SIZE}
--epochs ${NUM_EPOCHS}
--block-size ${BLOCK_SIZE}
--warmup-ratio ${WARMUP_RATIO}
--lora-r ${LORA_R}
--lora-alpha ${LORA_ALPHA}
--lora-dropout ${LORA_DROPOUT}
--weight-decay ${WEIGHT_DECAY}
--gradient-accumulation ${GRADIENT_ACCUMULATION}
$( [[ "$USE_FP16" == "True" ]] && echo "--fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--use-int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )
In the event you run the AutoTrain efficiently, it’s best to discover the next folder in your listing with all of the mannequin and tokenizer producer by AutoTrain.
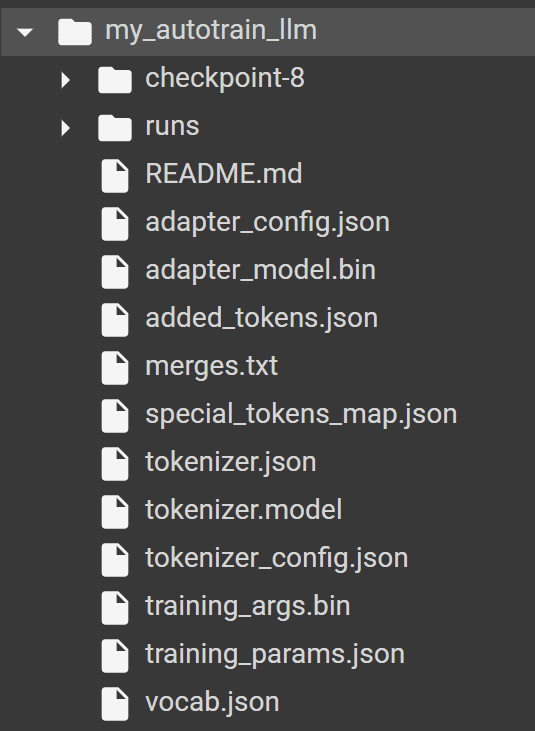
Picture by Writer
To check the mannequin, we might use the HuggingFace transformers bundle with the next code.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_path = "my_autotrain_llm"
tokenizer = AutoTokenizer.from_pretrained(model_path)
mannequin = AutoModelForCausalLM.from_pretrained(model_path)
Then, we will attempt to consider our mannequin based mostly on the coaching enter we’ve given. For instance, we use the “Well being advantages of normal train” because the enter.
input_text = "Well being advantages of normal train"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = mannequin.generate(input_ids)
predicted_text = tokenizer.decode(output[0], skip_special_tokens=False)
print(predicted_text)

The result’s definitely nonetheless could possibly be higher, however no less than it’s nearer to the pattern knowledge we’ve offered. We will attempt to taking part in round with the pre-trained mannequin and the parameter to enhance the fine-tuning.
There are few finest practices that you just may wish to know to enhance the fine-tuning course of, together with:
- Put together our dataset with the standard matching the consultant job,
- Research the pre-trained mannequin that we used,
- Use an acceptable regularization methods to keep away from overfitting,
- Attempting out the educational price from smaller and step by step develop into greater,
- Use fewer epoch because the coaching as LLM often be taught the brand new knowledge fairly quick,
- Don’t ignore the computational value, as it could develop into greater with greater knowledge, parameter, and mannequin,
- Be sure to comply with the moral consideration concerning the information you employ.
Advantageous-tuning our Giant Language Mannequin is helpful to our enterprise course of, particularly if there are specific necessities that we required. With the HuggingFace AutoTrain, we will enhance up our coaching course of and simply utilizing the obtainable pre-trained mannequin to fine-tune the mannequin.
Cornellius Yudha Wijaya is an information science assistant supervisor and knowledge author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Knowledge suggestions through social media and writing media.