
{kind=link}
Reinforcement studying is a department of machine studying that offers with an agent studying—by means of expertise—the way to work together with a fancy surroundings.
From AI brokers that play and surpass human efficiency in advanced board video games similar to chess and Go to autonomous navigation, reinforcement studying has a set of fascinating and various purposes.
Exceptional breakthroughs within the area of reinforcement studying embody DeepMind’s agent AlphaGo Zero that may defeat even human champions within the sport of Go and AlphaFold that may predict advanced 3D protein construction.
This information will introduce you to the reinforcement studying paradigm. We’ll take a easy but motivating real-world instance to grasp the reinforcement studying framework.
Let’s begin by defining the elements of a reinforcement studying framework.
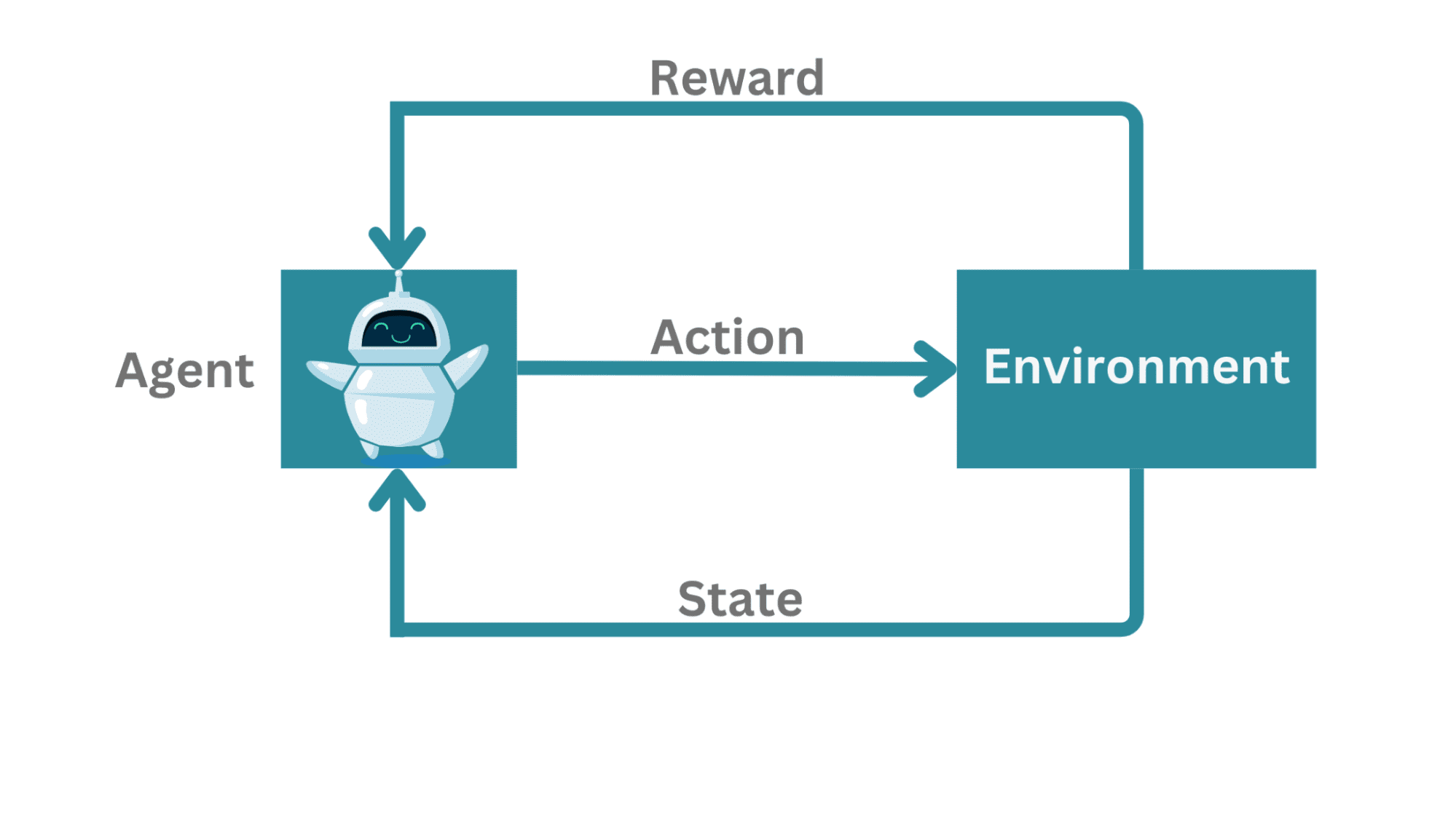
Reinforcement Studying Framework | Picture by Creator
In a typical reinforcement studying framework:
- There may be an agent studying to work together with the surroundings.
- The agent can measure its state, take actions, and infrequently will get a reward.
Sensible examples of this setting: the agent can play towards an opponent (say, a sport of chess) or attempt to navigate a fancy surroundings.
As an excellent simplified instance, contemplate a mouse in a maze. Right here, the agent is not taking part in towards an opponent however quite making an attempt to determine a path to the exit. If there are a couple of paths resulting in the exit, we could choose the shortest path out of the maze.

Mouse in a Maze | Picture by Creator
On this instance, the mouse is the agent making an attempt to navigate the surroundings which is the maze. The motion right here is the motion of the mouse inside the maze. When it efficiently navigates the maze to the exit—it will get a piece of cheese as a reward.
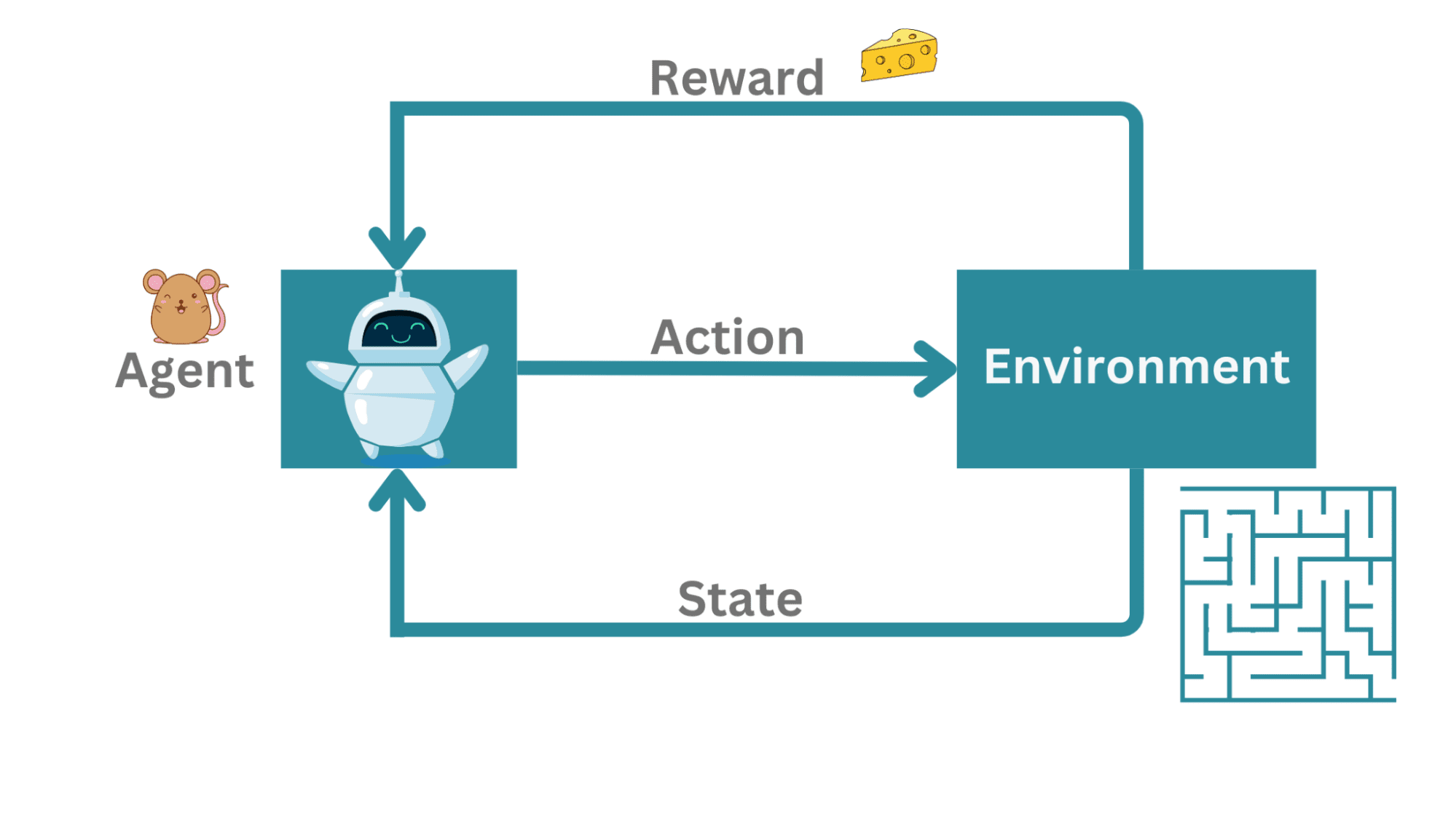
Instance | Picture by Creator
The sequence of actions occurs in discrete time steps (say, t = 1, 2, 3,…). At any time step t, the mouse can solely measure its present state within the maze. It doesn’t know the entire maze but.
So the agent (the mouse) measures its state s_t within the surroundings at time step t, takes a sound motion a_t and strikes to state s_(t + 1).
State | Picture by Creator
How Is Reinforcement Studying Completely different?
Discover how the mouse (the agent) has to determine its means out of the maze by means of trial and error. Now if the mouse hits one of many partitions of the maze, it has to attempt to discover its means again and etch a unique path to the exit.
If this have been a supervised studying setting, after each transfer, the agent would get to know whether or not or not that motion—was right—and would result in a reward. Supervised studying is like studying from a trainer.
Whereas a trainer tells you forward of time, a critic at all times tells you—after the efficiency is over— how good or unhealthy your efficiency was. Because of this, reinforcement studying can also be known as studying within the presence of a critic.
Terminal State and Episode
When the mouse has reached the exit, it reaches the terminal state. Which means it can not discover any additional.
And the sequence of actions—from the preliminary state to the terminal state—known as an episode. For any studying downside, we want a number of episodes for the agent to study to navigate. Right here, for our agent (the mouse) to study the sequence of actions that might lead it to the exit, and subsequently, obtain the piece of cheese, we’d want many episodes.
Dense and Sparse Rewards
At any time when the agent takes an accurate motion or a sequence of actions that’s right, it will get a reward. On this case, the mouse receives a bit of cheese as a reward for etching a sound route—by means of the maze(the surroundings)—to the exit.
On this instance, the mouse receives a bit of cheese solely on the very finish—when it reaches the exit.That is an instance of a sparse and delayed reward.
If the rewards are extra frequent, then we can have a dense reward system.
Trying again we have to work out (it’s not trivial) which motion or sequence of actions triggered the agent to get the reward; that is generally known as the credit score task downside.
The surroundings is usually not deterministic however probabilistic and so is the coverage. Given a state s_t, the agent takes an motion and goes to a different state s_(t+1) with a sure likelihood.
The coverage helps outline a mapping from the set of attainable states to the actions. It helps reply questions like:
- What actions to take to maximise the anticipated reward?
- Or higher but: Given a state, what’s the very best motion that the agent can take in order to maximise anticipated reward?
So you may consider the agent as enacting a coverage π:

One other associated and useful idea is the worth operate. The worth operate is given by:

This signifies the worth of being in a state given a coverage π. The amount denotes the anticipated reward sooner or later if the agent begins at state and enacts the coverage π thereafter.
To sum up: the purpose of reinforcement studying is to optimize the coverage in order to maximise the anticipated future rewards. Subsequently, we are able to consider it as an optimization downside to resolve for π.
Low cost Issue
Discover that we’ve got a brand new amount ɣ. What does it stand for? ɣ known as the low cost issue, a amount between 0 and 1. Which means future rewards are discounted (learn: as a result of now could be higher than a lot later).
Going again to the meals loop instance of mouse in a maze: If the mouse is in a position to determine a path to exit A with a small piece of cheese, it may possibly maintain repeating it and amassing the cheese piece. However what if the maze additionally had one other exit B with a much bigger cheese piece (higher reward)?
As long as the mouse retains exploiting this present technique with out exploring new methods, it’s not going to get the a lot higher reward of a much bigger cheese piece at exit B.
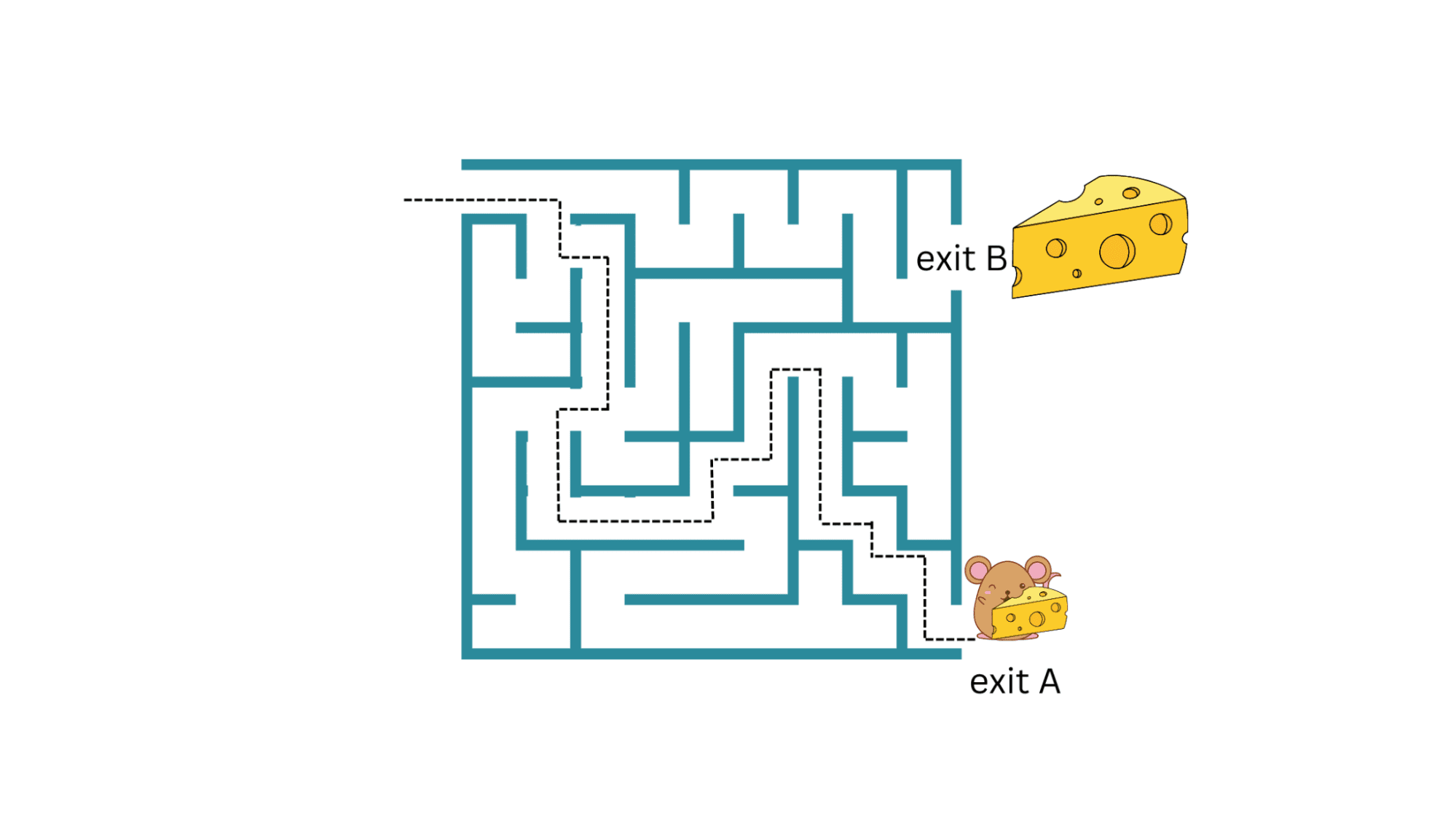
Exploration vs. Exploitation | Picture by Creator
However the uncertainty related to exploring new methods and future rewards is bigger. So how can we exploit and discover? This tradeoff between exploiting the present technique and exploring new ones with doubtlessly higher rewards known as the exploration vs exploitation tradeoff.
One attainable strategy is the ε-greedy search. Given a set of all attainable actions , the ε-greedy search explores one of many attainable actions with the likelihood ε whereas exploiting the present technique with the likelihood 1 – ε.
Let’s summarize what we’ve coated thus far. We realized in regards to the elements of the reinforcement studying framework:
- The agent interacts with the surroundings, will get to measure its present state, takes actions, and receives rewards as constructive reinforcement. The framework is probabilistic.
- We then went over worth features and coverage, and the way the optimization downside usually boils all the way down to discovering the optimum insurance policies that maximize the anticipated future awards.
You’ve now realized simply sufficient to navigate the reinforcement studying panorama. The place to go from right here? We didn’t discuss reinforcement studying algorithms on this information, so you may discover some fundamental algorithms:
- Nonetheless, generally, we could not have the ability to mannequin the surroundings utterly. On this case, you may take a look at model-free algorithms similar to Q-learning which optimizes state-action pairs.
When you’re seeking to additional your understanding of reinforcement studying, David Silver’s reinforcement studying lectures on YouTube and Hugging Face’s Deep Reinforcement Studying Course are some good assets to have a look at.
Bala Priya C is a developer and technical author from India. She likes working on the intersection of math, programming, knowledge science, and content material creation. Her areas of curiosity and experience embody DevOps, knowledge science, and pure language processing. She enjoys studying, writing, coding, and low! At present, she’s engaged on studying and sharing her information with the developer neighborhood by authoring tutorials, how-to guides, opinion items, and extra.