
{kind=link}

Picture by Creator
In right now’s data-driven world, knowledge evaluation and insights assist you get essentially the most out of it and assist you make higher selections. From an organization’s perspective, it offers a Aggressive Benefit and personaliz?s the entire course of.
This tutorial will discover essentially the most potent Python library pandas, and we are going to focus on an important capabilities of this library which can be vital for knowledge evaluation. Rookies also can comply with this tutorial attributable to its simplicity and effectivity. When you don’t have python put in in your system, you should use Google Colaboratory.
You’ll be able to obtain the dataset from that hyperlink.
import pandas as pd
df = pd.read_csv("kaggle_sales_data.csv", encoding="Latin-1") # Load the information
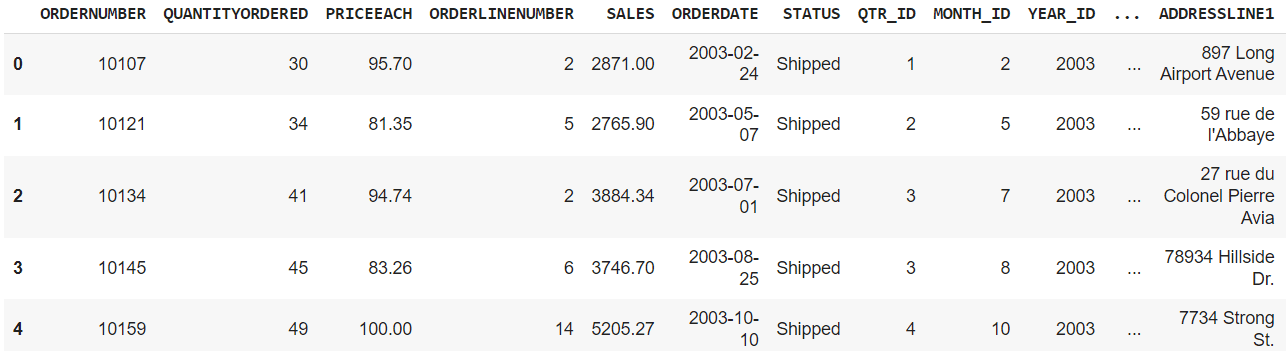
df.head() # Present first 5 rows
Output:
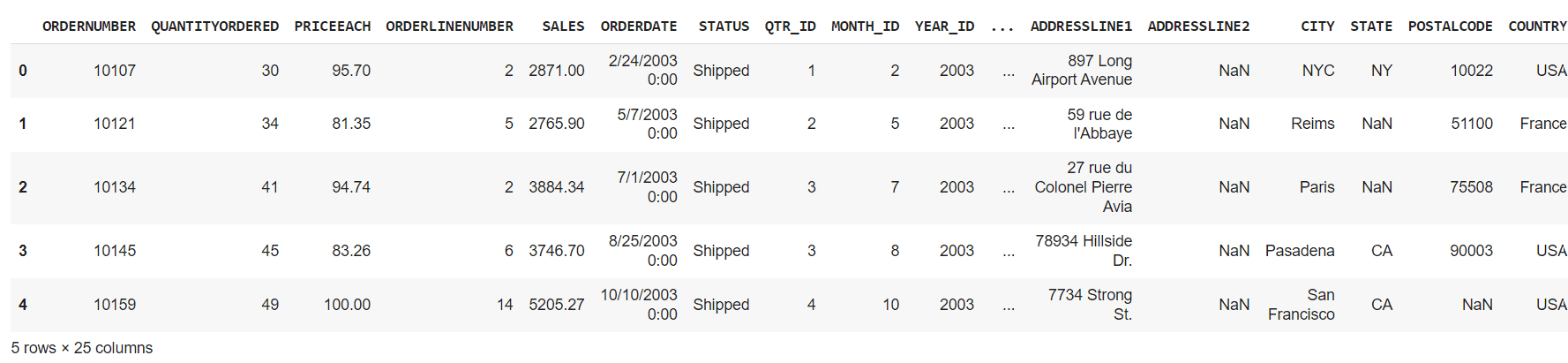
On this part, we are going to focus on numerous capabilities that assist you to get extra about your knowledge. Like viewing it or getting the imply, common, min/max, or getting details about the dataframe.
1. Information Viewing
-
df.head(): It shows the primary 5 rows of the pattern knowledge
-
df.tail(): It shows the final 5 rows of the pattern knowledge

-
df.pattern(n): It shows the random n variety of rows within the pattern knowledge
-
df.form: It shows the pattern knowledge’s rows and columns (dimensions).
It signifies that our dataset has 2823 rows, every containing 25 columns.
2. Statistics
This part incorporates the capabilities that assist you carry out statistics like common, min/max, and quartiles in your knowledge.
-
df.describe(): Get the fundamental statistics of every column of the pattern knowledge
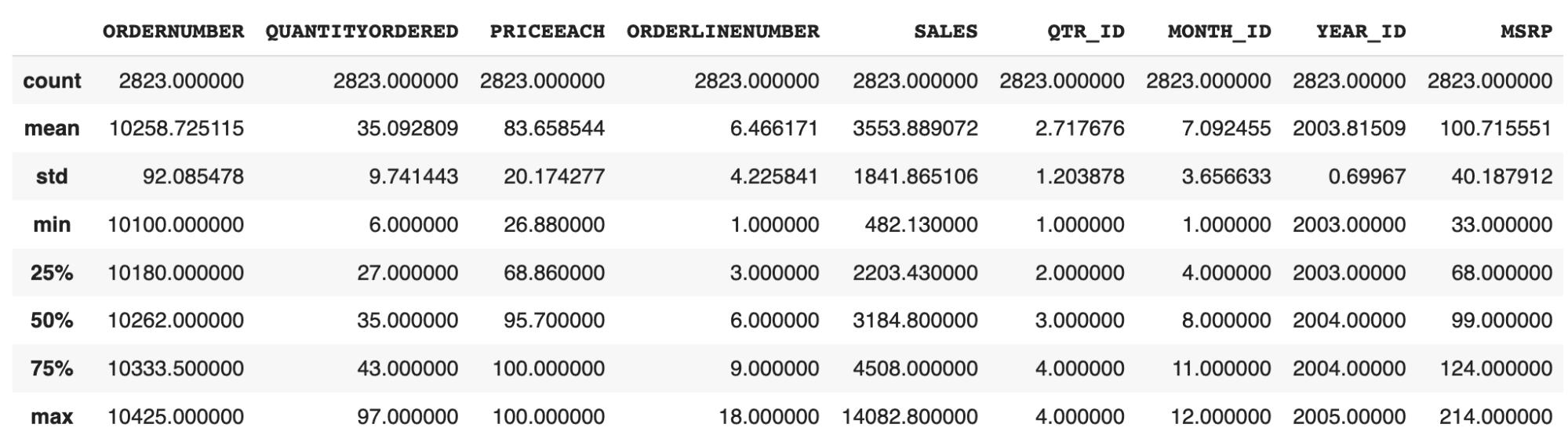
-
df.data(): Get the details about the varied knowledge sorts used and the non-null depend of every column.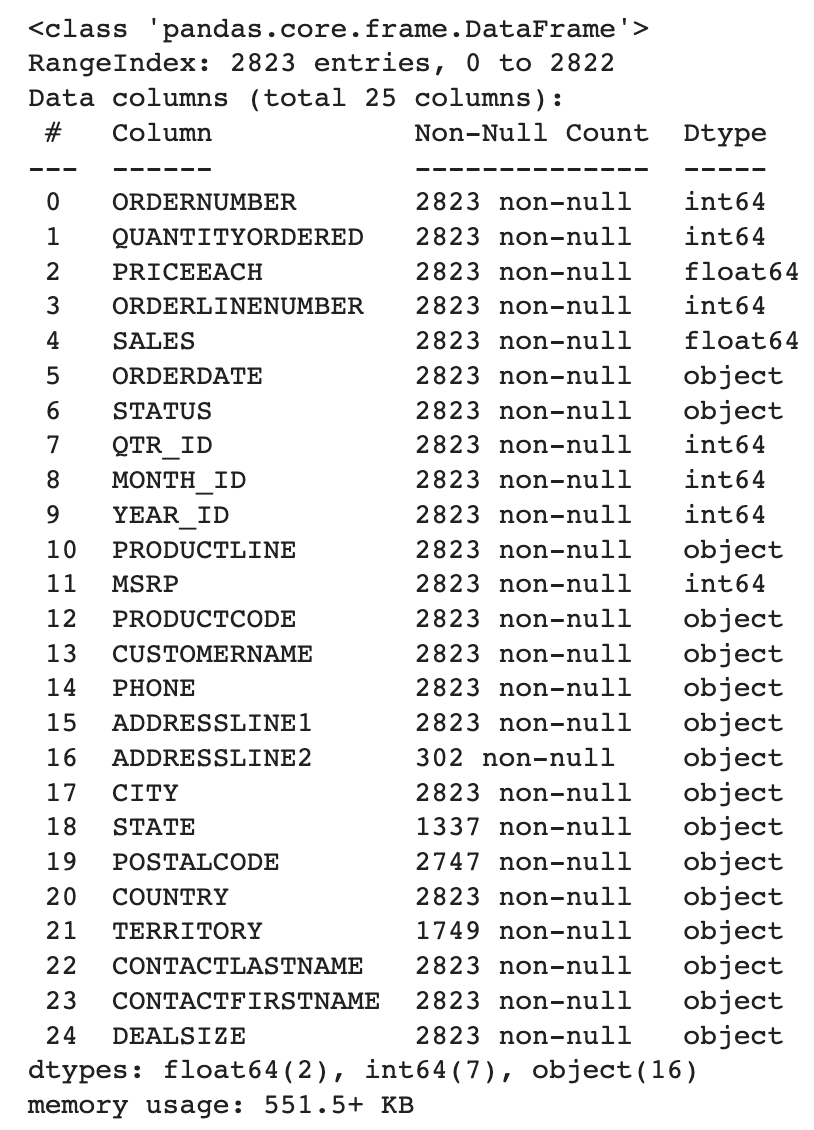
-
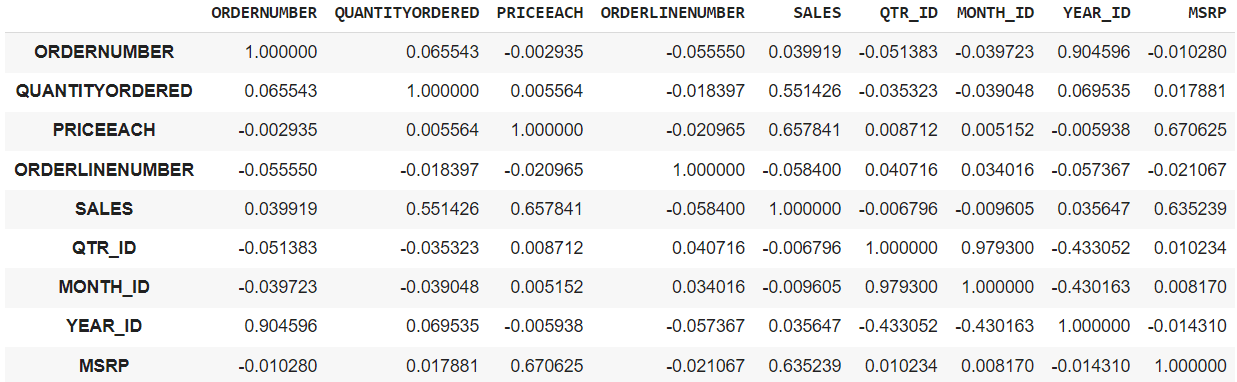
df.corr(): This could provide the correlation matrix between all of the integer columns within the knowledge body.
-
df.memory_usage(): It is going to inform you how a lot reminiscence is being consumed by every column.
3. Information Choice
You may as well choose the information of any particular row, column, and even a number of columns.
-
df.iloc[row_num]: It is going to choose a specific row based mostly on its index
For ex-,
-
df[col_name]: It is going to choose the actual column
For ex-,
Output:
-
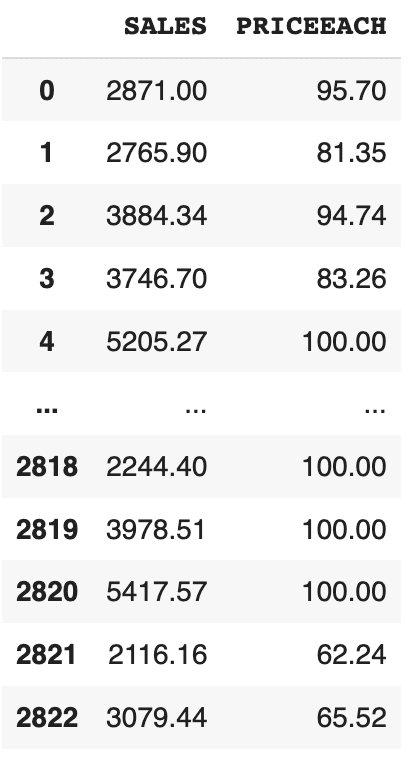
df[[‘col1’, ‘col2’]]: It is going to choose a number of columns given
For ex-,
df[["SALES", "PRICEEACH"]]
Output:
These capabilities are used to deal with the lacking knowledge. Some rows within the knowledge include some null and rubbish values, which might hamper the efficiency of our skilled mannequin. So, it’s at all times higher to right or take away these lacking values.
-
df.isnull(): It will establish the lacking values in your dataframe. -
df.dropna(): It will take away the rows containing lacking values in any column. -
df.fillna(val): It will fill the lacking values withvalgiven within the argument. -
df[‘col’].astype(new_data_type): It could actually convert the information sort of the chosen columns to a unique knowledge sort.
For ex-,
We’re changing the information sort of the SALES column from float to int.

Right here, we are going to use some useful capabilities in knowledge evaluation, like grouping, sorting, and filtering.
- Aggregation Capabilities:
You’ll be able to group a column by its title after which apply some aggregation capabilities like sum, min/max, imply, and many others.
df.groupby("col_name_1").agg({"col_name_2": "sum"})
For ex-,
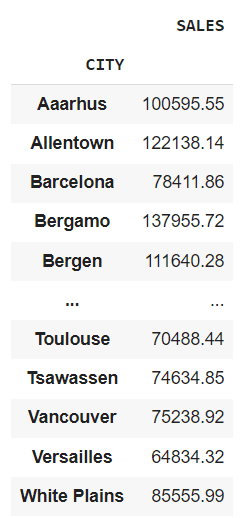
df.groupby("CITY").agg({"SALES": "sum"})
It offers you the whole gross sales of every metropolis.
If you wish to apply a number of aggregations at a single time, you’ll be able to write them like that.
For ex-,
aggregation = df.agg({"SALES": "sum", "QUANTITYORDERED": "imply"})
Output:
SALES 1.003263e+07
QUANTITYORDERED 3.509281e+01
dtype: float64
- Filtering Information:
We are able to filter the information in rows based mostly on a selected worth or a situation.
For ex-,
Shows the rows the place the worth of gross sales is larger than 5000
You may as well filter the dataframe utilizing the question() operate. It is going to additionally generate the same output as above.
For ex,
- Sorting Information:
You’ll be able to type the information based mostly on a selected column, both within the ascending order or within the descending order.
For ex-,
df.sort_values("SALES", ascending=False) # Kinds the information in descending order
- Pivot Tables:
We are able to create pivot tables that summarize the information utilizing particular columns. That is very helpful in analyzing the information while you solely wish to take into account the impact of explicit columns.
For ex-,
pd.pivot_table(df, values="SALES", index="CITY", columns="YEAR_ID", aggfunc="sum")
Let me break this for you.
-
values: It incorporates the column for which you wish to populate the desk’s cells. -
index: The column utilized in it should change into the row index of the pivot desk, and every distinctive class of this column will change into a row within the pivot desk. -
columns: It incorporates the headers of the pivot desk, and every distinctive component will change into the column within the pivot desk. -
aggfunc: This is similar aggregator operate we mentioned earlier.
Output:
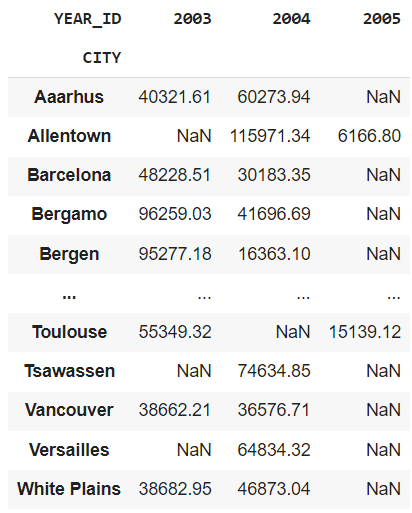
This output reveals a chart which depicts the whole gross sales in a specific metropolis for a selected yr.
6. Combining Information Frames
We are able to mix and merge a number of knowledge frames both horizontally or vertically. It is going to concatenate two knowledge frames and return a single merged knowledge body.
For ex-,
combined_df = pd.concat([df1, df2])
You’ll be able to merge two knowledge frames based mostly on a typical column. It’s helpful while you wish to mix two knowledge frames that share a typical identifier.
For ex,
merged_df = pd.merge(df1, df2, on="common_col")
7. Making use of Customized Capabilities
You’ll be able to apply customized capabilities in line with your wants in both a row or a column.
For ex-,
def cus_fun(x):
return x * 3
df["Sales_Tripled"] = df["SALES"].apply(cus_fun, axis=0)
We now have written a customized operate that can triple the gross sales worth for every row. axis=0 signifies that we wish to apply the customized operate on a column, and axis=1 implies that we wish to apply the operate on a row.
Within the earlier technique you need to write a separate operate after which to name it from the apply() technique. Lambda operate lets you use the customized operate contained in the apply() technique itself. Let’s see how we are able to try this.
df["Sales_Tripled"] = df["SALES"].apply(lambda x: x * 3)
Applymap:
We are able to additionally apply a customized operate to each component of the dataframe in a single line of code. However some extent to recollect is that it’s relevant to all the weather within the dataframe.
For ex-,
df = df.applymap(lambda x: str(x))
It is going to convert the information sort to a string of all the weather within the dataframe.
8. Time Sequence Evaluation
In arithmetic, time sequence evaluation means analyzing the information collected over a selected time interval, and pandas have capabilities to carry out such a evaluation.
Conversion to DateTime Object Mannequin:
We are able to convert the date column right into a datetime format for simpler knowledge manipulation.
For ex-,
df["ORDERDATE"] = pd.to_datetime(df["ORDERDATE"])
Output:
Calculate Rolling Common:
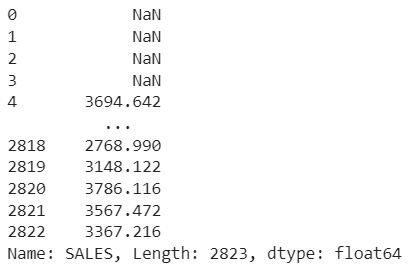
Utilizing this technique, we are able to create a rolling window to view knowledge. We are able to specify a rolling window of any measurement. If the window measurement is 5, then it means a 5-day knowledge window at the moment. It could actually assist you take away fluctuations in your knowledge and assist establish patterns over time.
For ex-
rolling_avg = df["SALES"].rolling(window=5).imply()
Output:
9. Cross Tabulation
We are able to carry out cross-tabulation between two columns of a desk. It’s usually a frequency desk that reveals the frequency of occurrences of varied classes. It could actually assist you to know the distribution of classes throughout completely different areas.
For ex-,
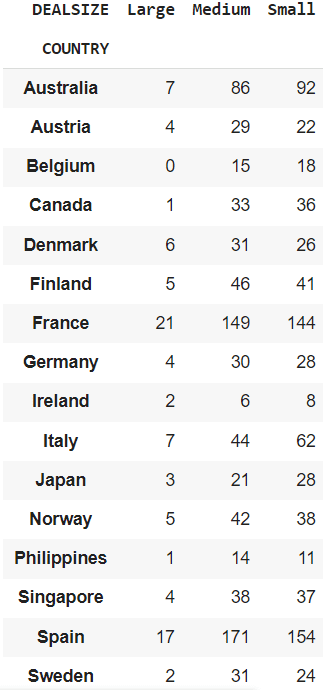
Getting a cross-tabulation between the COUNTRY and DEALSIZE.
cross_tab = pd.crosstab(df["COUNTRY"], df["DEALSIZE"])
It could actually present you the order measurement (‘DEALSIZE’) ordered by completely different nations.
10. Dealing with Outliers
Outliers in knowledge signifies that a specific level goes far past the common vary. Let’s perceive it by way of an instance. Suppose you’ve gotten 5 factors, say 3, 5, 6, 46, 8. Then we are able to clearly say that the quantity 46 is an outlier as a result of it’s far past the common of the remainder of the factors. These outliers can result in unsuitable statistics and needs to be faraway from the dataset.
Right here pandas come to the rescue to search out these potential outliers. We are able to use a way known as Interquartile Vary(IQR), which is a typical technique for locating and dealing with these outliers. You may as well examine this technique in order for you info on it. You’ll be able to learn extra about them right here.
Let’s see how we are able to try this utilizing pandas.
Q1 = df["SALES"].quantile(0.25)
Q3 = df["SALES"].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df["SALES"] < lower_bound) | (df["SALES"] > upper_bound)]
Q1 is the primary quartile representing the twenty fifth percentile of the information and Q3 is the third quartile representing the seventy fifth percentile of the information.
lower_bound variable shops the decrease certain that’s used for locating potential outliers. Its worth is about to 1.5 occasions the IQR under Q1. Equally, upper_bound calculates the higher certain, 1.5 occasions the IQR above Q3.
After which, you filter out the outliers which can be lower than the decrease or better than the higher certain.
Python pandas library allows us to carry out superior knowledge evaluation and manipulations. These are just a few of them. You’ll find some extra instruments in this pandas documentation. One vital factor to recollect is that the number of methods could be particular which caters to your wants and the dataset you’re utilizing.
Aryan Garg is a B.Tech. Electrical Engineering scholar, presently within the remaining yr of his undergrad. His curiosity lies within the discipline of Internet Growth and Machine Studying. He have pursued this curiosity and am wanting to work extra in these instructions.