
{kind=link}

Picture by rawpixel.com on Freepik
It doesn’t matter what enterprise you’re in, understanding the right way to analyze knowledge is extra essential than ever within the data-driven period. Knowledge evaluation would allow companies to remain aggressive and supply the flexibility to make higher selections.
The significance of knowledge evaluation drives each particular person to know the right way to carry out knowledge evaluation. Nonetheless, generally it takes an excessive amount of time to conduct knowledge evaluation. That’s why we may depend on ChatGPT to create a whole report from our knowledge file.
This text will discover 5 easy steps to create full analytical studies out of your CSV file. These 5 steps embody:
Step 1: Importing the CSV File
Step 2: Knowledge Abstract and Preprocessing
Step 3: Knowledge Evaluation
Step 4: Knowledge Visualization
Step 5: Report Era
As a prerequisite, this text assumes that the reader has subscribed to ChatGPT Plus. With that in thoughts, let’s get began.
Step one is to organize the CSV file that you just need to analyze and create a report. This file may come from any reliable supply, however this text would use the Telecom Churn dataset from Kaggle.
Guarantee the info is structured, organized, and has a transparent header. In case you have a sure goal that you just need to analyze, then don’t overlook to incorporate that knowledge within the file. In our instance, we’d attempt to carry out an evaluation for the churn column.
With the info prepared, connect them to the ChatGPT and let the mannequin do their work.
The following step is to get the info abstract from our CSV file and preprocess them. Enter the next immediate when you add the info.
Present the info abstract to this file and carry out applicable knowledge processing for the dataset.
The above immediate supplies the next outcomes:
This is the abstract of your dataset:
Variety of Rows: 3333
Variety of Columns: 11
Column Names:
Churn
AccountWeeks
ContractRenewal
DataPlan
DataUsage
CustServCalls
DayMins
DayCalls
MonthlyCharge
OverageFee
RoamMins
Knowledge Varieties:
Integer: Churn, AccountWeeks, ContractRenewal, DataPlan, CustServCalls, DayCalls
Float: DataUsage, DayMins, MonthlyCharge, OverageFee, RoamMins
Lacking Values: There aren’t any lacking values in any of the columns.
ChatGPT clearly may learn the info nicely and was in a position to present the given dataset. The following result’s the info preprocessing from the ChatGPT.
Since there aren’t any lacking values within the dataset, the principle focus of knowledge cleansing and preprocessing will likely be on:
- Checking for any outliers or anomalies within the knowledge.
- Normalizing or standardizing the info if required, particularly for columns with steady numerical values.
- Changing categorical knowledge right into a format appropriate for evaluation, if essential.
Let’s proceed with these steps.
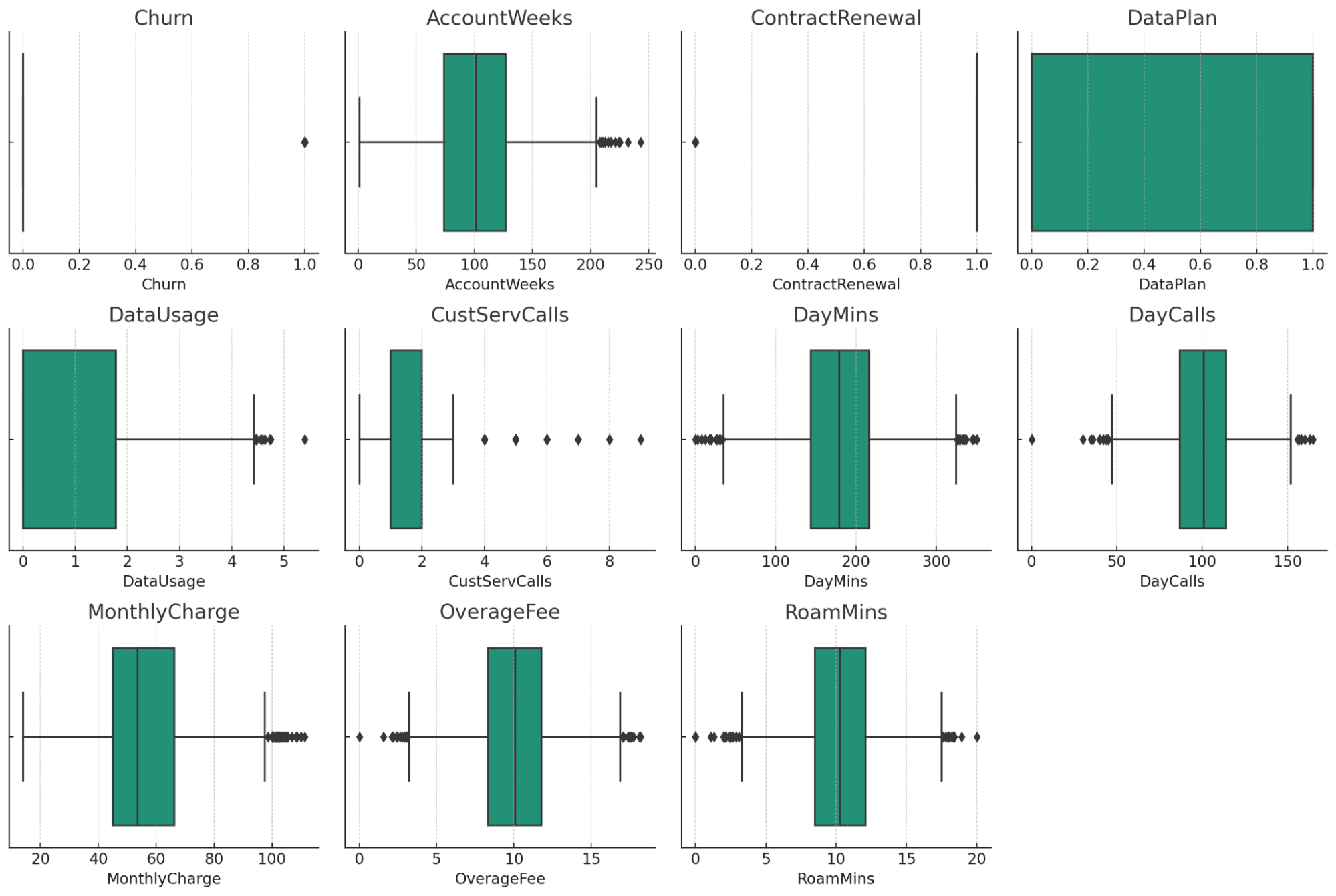
The boxplots present a visible overview of potential outliers in every numerical column of your dataset. Listed below are some observations:
- AccountWeeks, CustServCalls, DayCalls: These columns present a reasonably regular distribution with just a few outliers.
- DataUsage, DayMins, MonthlyCharge, OverageFee, RoamMins: These columns additionally present some outliers, however they appear to be inside an inexpensive vary, contemplating the character of the info.
- Churn, ContractRenewal, DataPlan: Being categorical/binary knowledge, these columns do not present conventional outliers.
Given this info, the following steps in knowledge cleansing and preprocessing may embody:
- Dealing with Outliers: We will determine whether or not to take away, cap, or in any other case deal with outliers primarily based in your particular analytical wants and area data.
- Knowledge Transformation: If wanted, we are able to normalize or standardize columns like DayMins, MonthlyCharge, and so forth., particularly for those who plan to make use of algorithms which might be delicate to the size of knowledge.
- Categorical Knowledge Encoding: Convert categorical knowledge right into a format appropriate for evaluation, if any such transformation is required.
You’ll be able to let the ChatGPT carry out further steps for the info cleansing and preprocessing or let or not it’s as it’s. For this instance, we’d proceed to the following steps.
Subsequent, we’d carry out knowledge evaluation with ChatGPT. The information evaluation is relying on what you need to obtain. In our case, we need to carry out knowledge evaluation from the Churn POV.
We use the next immediate to execute the info evaluation with ChatGPT for the above case.
Please carry out the info evaluation primarily based on the info above with respect to the churn knowledge.
The information evaluation will be seen within the following outcome.
To carry out knowledge evaluation with respect to the churn knowledge, we’ll give attention to understanding how various factors relate to buyer churn. Churn, being a binary variable (0 for no churn, 1 for churn), is often analyzed by way of classification strategies and by inspecting relationships with different variables. This is the plan:
- Correlation Evaluation: To begin, we’ll take a look at how every numerical characteristic correlates with churn. This provides us an preliminary understanding of which elements could be extra intently associated to churn.
- Statistical Assessments: For categorical variables like ContractRenewal and DataPlan, we are able to use statistical exams to see if there are vital variations in churn charges throughout totally different classes.
- Visible Evaluation: We’ll create some visualizations to additional discover these relationships. This consists of evaluating churn charges throughout totally different teams and plotting key variables in opposition to churn.
- Abstract Statistics: We’ll present abstract statistics for various teams primarily based on churn standing to see if there are noticeable variations in means or distributions.
Let’s begin with the correlation evaluation after which transfer on to the following steps.
Correlation Evaluation with Churn
The correlation of various variables with churn is as follows (from strongest unfavourable to strongest optimistic correlation):
Destructive Correlation:
- ContractRenewal: Strongest unfavourable correlation. Signifies that prospects who don’t renew their contracts usually tend to churn.
- DataPlan: Prospects with out a knowledge plan are barely extra more likely to churn.
- DataUsage: Larger knowledge utilization barely decreases the chance of churn.
Constructive Correlation:
- AccountWeeks, DayCalls: Very weak optimistic correlation, suggesting minimal influence on churn.
- RoamMins: A slight enhance in churn chance with elevated roaming minutes.
- MonthlyCharge: Barely larger churn charges with elevated month-to-month fees.
- OverageFee: Larger overage charges are reasonably correlated with elevated churn.
- DayMins: Larger every day minutes are reasonably correlated with elevated churn.
- CustServCalls: Sturdy optimistic correlation. Extra customer support calls are related to larger churn charges.
Primarily based on these correlations, evidently elements like contract renewal, customer support calls, every day minutes, and overage charges are extra intently associated to churn. We will additional discover these elements by way of visible evaluation and statistical exams, particularly for categorical variables like ContractRenewal and DataPlan.
Visible Evaluation
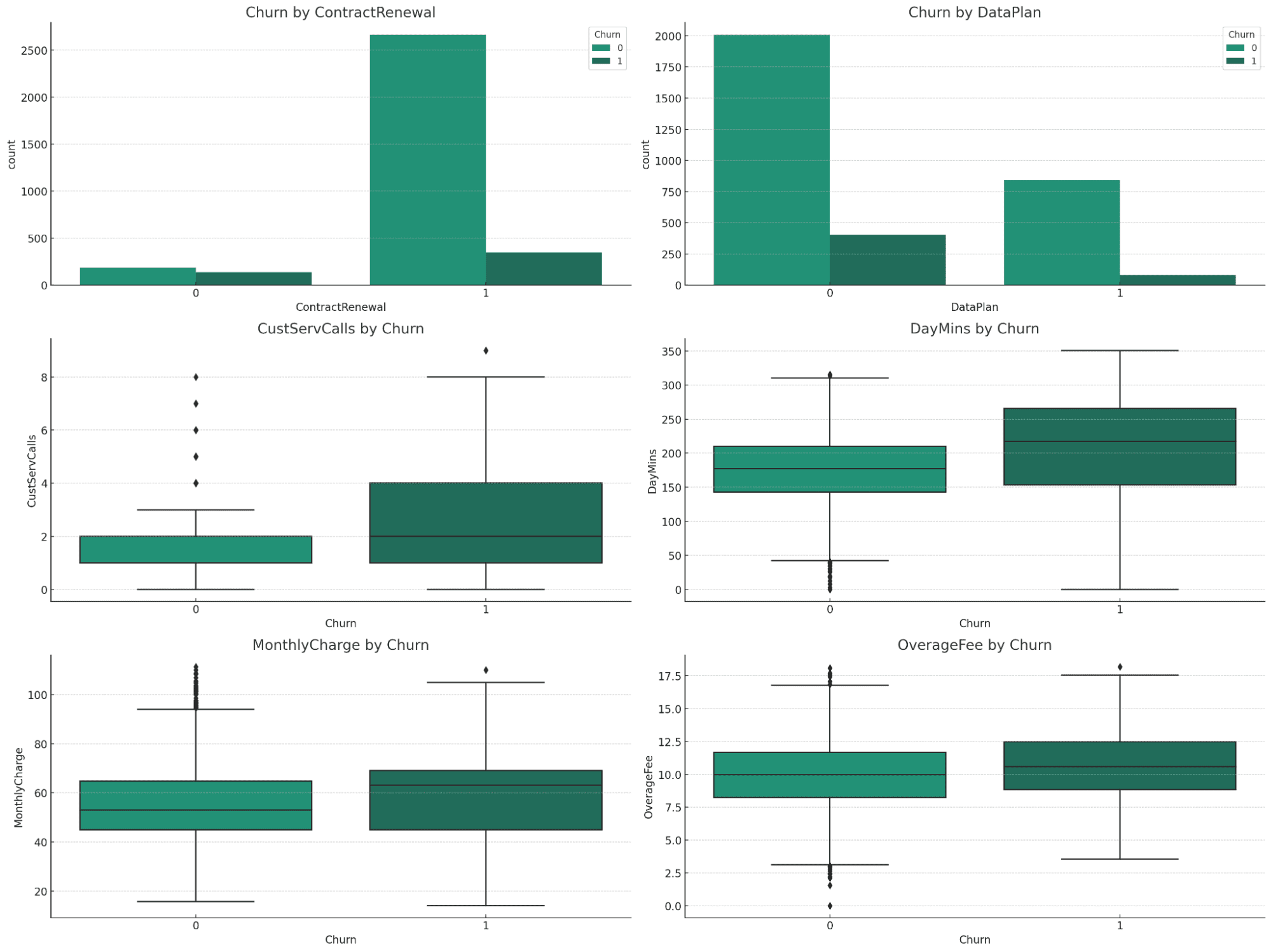
The visualizations provide precious insights into the connection between totally different variables and churn:
Churn by ContractRenewal and DataPlan:
- ContractRenewal: A big distinction in churn charges is clear. Prospects who didn’t renew their contracts present the next charge of churn.
- DataPlan: There’s a noticeable distinction in churn charges primarily based on whether or not prospects have an information plan or not, with these with out a knowledge plan exhibiting larger churn.
Numerical Variables (CustServCalls, DayMins, MonthlyCharge, OverageFee) by Churn:
- CustServCalls: Prospects with larger numbers of customer support calls are likely to churn extra.
- DayMins: Larger every day minutes are related to a larger chance of churn.
- MonthlyCharge: Larger month-to-month fees correlate with an elevated churn charge.
- OverageFee: Larger overage charges are additionally related to elevated churn.
Conclusions from the Evaluation
- Contract renewal standing and the presence of an information plan are vital elements in buyer churn.
- Excessive utilization (by way of day minutes) and excessive fees (month-to-month fees and overage charges) are related to larger churn charges.
- The next variety of customer support calls is a powerful indicator of potential churn.
Subsequent Steps
Primarily based on these insights, focused methods will be developed to scale back churn, corresponding to bettering customer support, revising pricing methods, or providing incentives for contract renewal and knowledge plan subscriptions.
With a single immediate, we are able to see how nicely ChatGPT may give us the whole knowledge evaluation and give you perception from the info. You’ll be able to tweak the evaluation goals and begin from there.
The information visualization is a supportive exercise to enhance the info evaluation and general report. By having the visualization, we are able to have a extra complete report to know our knowledge.
Utilizing the next immediate, we are able to carry out the info visualization with ChatGPT.
Please carry out knowledge visualization from the info evaluation to elucidate the info higher.
To boost the understanding of the info evaluation outcomes, I will create a collection of visualizations that clearly depict the important thing findings associated to buyer churn. These visualizations will embody:
- Bar Plots for Categorical Variables:
- Evaluating churn charges for patrons with and with out contract renewal.
- Evaluating churn charges for patrons with and with out a knowledge plan.
- Field Plots for Key Numerical Variables:
- Buyer Service Calls vs Churn.
- Every day Minutes vs Churn.
- Month-to-month Fees vs Churn.
- Overage Charges vs Churn.
- Heatmap of Correlation:
To visualise the correlation of all variables with churn.
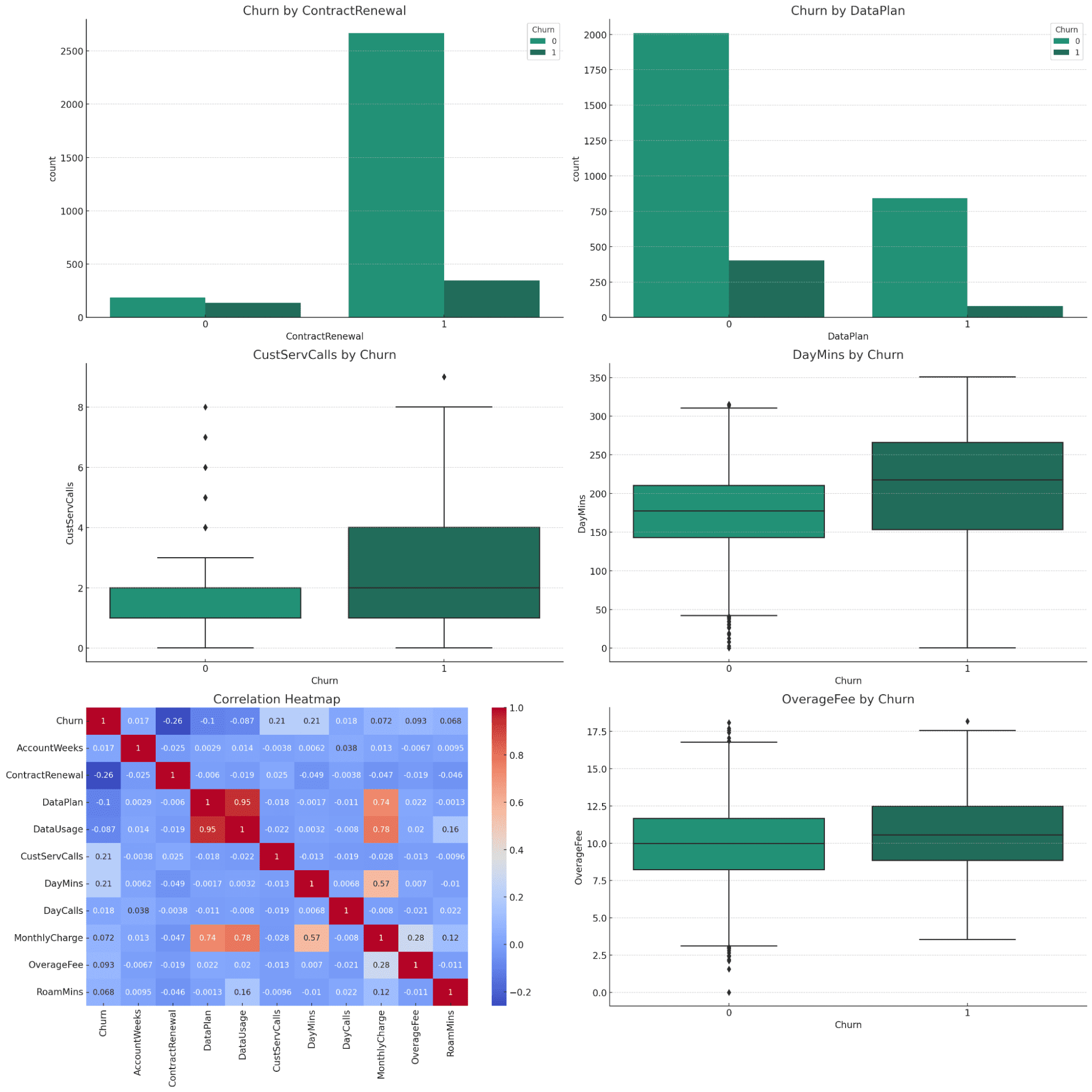
The visualization would present all of the essential plots that encapsulate the entire dataset. We will ask for extra detailed descriptions for every plot, which you’ll be able to strive independently.
The final step is to generate the report primarily based on the earlier steps. Sadly, ChatGPT may not seize all the outline and perception from the info evaluation, however we are able to nonetheless have the straightforward model of the report.
Use the next immediate to generate a PDF report primarily based on the earlier evaluation.
Please present me with the pdf report from step one to the final step.
You’re going to get the PDF hyperlink outcome along with your earlier evaluation lined. Attempt to iterate the steps for those who really feel the result’s insufficient or if there are belongings you need to change.
Knowledge evaluation is an exercise that everybody ought to know because it’s probably the most required abilities within the present period. Nonetheless, studying about performing knowledge evaluation may take a very long time. With ChatGPT, we are able to reduce all that exercise time.
On this article, we have now mentioned the right way to generate a whole analytical report from CSV recordsdata in 5 steps. ChatGPT supplies customers with end-to-end knowledge evaluation exercise, from importing the file to producing the report.
Cornellius Yudha Wijaya is an information science assistant supervisor and knowledge author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Knowledge ideas by way of social media and writing media.