


{kind=link}
Introduction
Massive Language Fashions (LLMs) have gained a whole lot of consideration lately and achieved spectacular ends in varied NLP duties. Constructing on this momentum, it’s essential to dive deeper into particular purposes of LLMs, corresponding to their utilization within the process of few-shot Named Entity Recognition (NER). This leads us to the main target of our ongoing exploration — a comparative evaluation of LLMs’ efficiency in few-shot NER. We are attempting to grasp:
- Do LLMs outperform supervised strategies in few-shot NER?
- Which LLMs are presently probably the most performant?
- How else can LLMs be utilized in Few-Shot NER?
Try our earlier weblog submit on what NER is and present state-of-the-art (SOTA) few-shot NER strategies.
On this weblog submit, we proceed our dialogue to search out out whether or not LLMs reign supreme in few-shot NER. To do that, we’ll be a couple of lately launched papers that deal with every of the questions above. Latest analysis signifies that when there’s a wealth of labeled examples for a sure entity sort, LLMs nonetheless lag behind supervised strategies for that exact entity sort. But, for many entity varieties there’s a scarcity of annotated information. Novel entity varieties are frequently arising, and creating annotated examples is a expensive and prolonged course of, significantly in high-value fields like biomedicine the place specialised information is critical for annotation. As such, few-shot NER stays a related and vital process.
How do LLMs stack up in opposition to supervised strategies?
To search out out, let’s check out GPT-NER by Shuhe Wang et al. which was printed in April 2023. The authors proposed to remodel the NER sequence labeling process (assigning courses to tokens) right into a technology process (producing textual content), which ought to make it simpler to cope with for LLMs, and GPT fashions. The determine beneath is an instance of how the prompts are constructed to acquire labels when the mannequin is given an instruction together with a couple of examples.

GPT-NER Immediate building instance (Shuhe Wang et al.)
To remodel the duty into one thing extra simply digestible for LLMs, the authors add particular symbols marking the areas of the named entities: for instance, France turns into @@France##. After seeing a couple of examples of this, the mannequin then has to mark the entities in its solutions in the identical approach. On this setting, just one sort of entity (e.g. location or particular person) is detected utilizing one immediate. If a number of entity varieties must be detected, the mannequin needs to be queried a number of instances.
The authors used GPT-3 and carried out experiments over 4 completely different NER datasets. Unsurprisingly, supervised fashions proceed to outperform GPT-NER in totally supervised baselines, as LLMs are often seen as generalists. LLMs additionally endure from hallucination, a phenomenon the place LLMs generate textual content that isn’t actual, or is inaccurate or nonsensical. The authors claimed that, of their case, the mannequin tended to over-confidently mark non-entity phrases as named entities. To counteract the problem of hallucination, the authors suggest a self-verification technique: when the mannequin says one thing is an entity, it’s then requested a sure/no query to confirm whether or not the extracted entity belongs to the desired sort. Utilizing this self-verification technique additional improves the mannequin’s efficiency however doesn’t but bridge the hole in efficiency when in comparison with supervised strategies.
An interesting level from this paper is that GPT-NER displays spectacular proficiency in low-resource and few-shot NER setups. The determine beneath exhibits the efficiency of the supervised mannequin is way beneath GPT-3 when the coaching set could be very small.
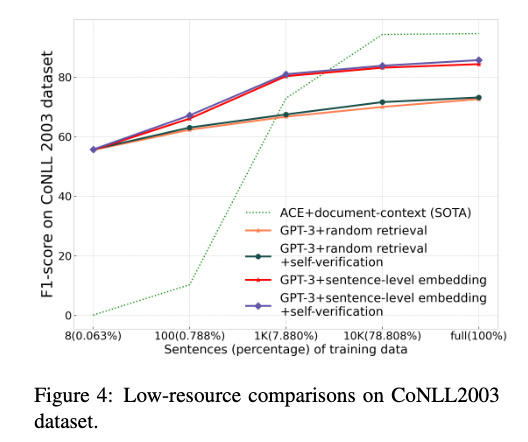
GPT-NER vs supervised strategies in a low-resource setting on a dataset (Shuhe Wang et al.)
That appears to be very promising. Does this imply the reply ends right here? By no means. Particulars within the paper reveal a couple of issues concerning the GPT-NER methodology that may not appear apparent at first look.
A number of particulars within the paper give attention to tips on how to choose the few examples from the coaching dataset to provide inside the LLM immediate (the authors name these “few-shot demonstration examples”). The principle distinction between this and a real few-shot setting is that the latter solely has a couple of coaching examples obtainable whereas the previous has much more, i.e. we aren’t spoiled with alternative in a real few-shot setting. As well as, one of the best demonstration instance retrieval technique makes use of a fine-tuned NER mannequin. All this means that an apple-to-apple comparability must be made however was not completed on this paper. A benchmark must be created the place one of the best few-shot technique and pure-LLM strategies are in contrast utilizing the identical (few) coaching examples utilizing datasets like Few-NERD.
That being mentioned, it’s nonetheless fascinating that LLM-based strategies like GPT-NER can obtain virtually comparable efficiency in opposition to SOTA NER strategies.
Which LLMs are greatest in Few-Shot NER?
On account of their recognition, OpenAI’s GPT collection fashions, such because the GPT-3 collection (davinci, text-davinci-001), have been the primary focus for preliminary research. In a paper titled “A Complete Functionality Evaluation of GPT-3 and GPT-3.5 Collection Fashions“ that was first printed in March 2023, Ye et al. claimed that whereas GPT-3 and ChatGPT obtain one of the best efficiency over 6 completely different NER datasets among the many OpenAI GPT collection fashions within the zero-shot setting, efficiency varies within the few-shot setting (1-shot and 3-shot), i.e. there isn’t a clear winner.
How else can LLMs be utilized in Few-Shot NER (or associated duties)?
In earlier research, quite a lot of prompting strategies have been offered. Nonetheless, Zhou et al. put forth a novel method the place they utilized the strategy of focused distilling. As an alternative of merely making use of an LLM as is to the NER process by way of prompting, they practice a smaller mannequin, known as a pupil, that goals to copy the capabilities of a generalist language mannequin on a particular process (on this case, named entity recognition).
A pupil mannequin is created in two primary steps. First, they take samples of a giant textual content dataset and use ChatGPT to search out named entities in these samples and establish their varieties. Then these routinely annotated information are used as directions to fine-tune a smaller, open-source LLM. The authors identify this technique “mission-focused instruction tuning”. This manner, the smaller mannequin learns to copy the capabilities of the stronger mannequin which has extra parameters. The brand new mannequin solely must carry out effectively on a particular class of duties, so it may well really outperform the mannequin it discovered from.

Prompting an LLM to generate entity mentions and their varieties (Zhou et al.)
This system enabled Zhou et al. to considerably outperform ChatGPT and some different LLMs in NER.
As an alternative of few-shot NER, the authors targeted on open-domain NER, which is a sub-task of NER that works throughout all kinds of domains. This route of analysis has confirmed to be an fascinating exploration of the purposes of GPT fashions and instruction tuning. The paper’s experiments present promising outcomes, indicating they might probably revolutionize the way in which we method NER duties and improve the techniques’ effectivity and precision.
On the similar time, there have been efforts targeted on utilizing open-source LLMs, which supply extra transparency and choices for experimentation. For instance, Li et al. have lately proposed to leverage the inner representations inside a big language mannequin (particularly, LLaMA-2) and supervised fine-tuning to create higher NER and textual content classification fashions. The authors declare to realize state-of-the-art outcomes on the CoNLL-2003 and OntoNotes datasets. Such extensions and modifications are solely potential with open-source fashions, and it’s a promising signal that they’ve been getting extra consideration and may be prolonged to few-shot NER sooner or later.
All in all
Few-Shot NER utilizing LLMs continues to be a comparatively unexplored area. There are a number of developments and open-ended questions on this area. For example, ChatGPT continues to be generally used, however given the emergence of different proprietary and open-source LLMs, this might shift sooner or later. The solutions to those questions won’t simply form the way forward for NER, but additionally have a substantial influence on the broader area of machine studying.
Check out one of many LLMs on the Clarifai platform immediately. We even have a full weblog submit on tips on how to Examine Prime LLMs with LLM Batteground. Can’t discover what you want? Seek the advice of our docs web page or ship us a message in our Group Discord channel.