

{kind=link}
Microsoft printed a analysis examine that demonstrates how superior prompting strategies could cause a generalist AI like GPT-4 to carry out in addition to or higher than a specialist AI that’s skilled for a selected subject. The researchers found that they may make GPT-4 outperform Google’s specifically skilled Med-PaLM 2 mannequin that was explicitly skilled in that subject.
Superior Prompting Strategies
The outcomes of this analysis confirms insights that superior customers of generative AI have found and are utilizing to generate astonishing pictures or textual content output.
Superior prompting is commonly known as immediate engineering. Whereas some might scoff that prompting could be so profound as to warrant the identify engineering, the very fact is that superior prompting strategies are based mostly on sound ideas and the outcomes of this analysis examine underlines this truth.
For instance, a way utilized by the researchers, Chain of Thought (CoT) reasoning is one which many superior generative AI customers have found and used productively.
Chain of Thought prompting is a technique outlined by Google round Could 2022 that permits AI to divide a job into steps based mostly on reasoning.
I wrote about Google’s analysis paper on Chain of Thought Reasoning which allowed an AI to interrupt a job down into steps, giving it the flexibility to resolve any sort of phrase issues (together with math) and to realize commonsense reasoning.
These principals finally labored their method into how generative AI customers elicited prime quality output, whether or not it was creating pictures or textual content output.
Peter Hatherley (Fb profile), founding father of Authored Intelligence net app suites, praised the utility of chain of thought prompting:
“Chain of thought prompting takes your seed concepts and turns them into one thing extraordinary.”
Peter additionally famous that he incorporates CoT into his customized GPTs to be able to supercharge them.
Chain of Thought (CoT) prompting developed from the invention that asking a generative AI for one thing shouldn’t be sufficient as a result of the output will constantly be lower than splendid.
What CoT prompting does is to stipulate the steps the generative AI must take to be able to get to the specified output.
The breakthrough of the analysis is that utilizing CoT reasoning plus two different strategies allowed them to realize beautiful ranges of high quality past what was identified to be potential.
This system is known as Medprompt.
Medprompt Proves Worth Of Superior Prompting Strategies
The researchers examined their method towards 4 completely different basis fashions:
- Flan-PaLM 540B
- Med-PaLM 2
- GPT-4
- GPT-4 MedPrompt
They used benchmark datasets created for testing medical data. A few of these checks have been for reasoning, some have been questions from medical board exams.
4 Medical Benchmarking Datasets
- MedQA (PDF)
A number of selection query answering dataset - PubMedQA (PDF)
Sure/No/Possibly QA Dataset - MedMCQA (PDF)
Multi-Topic Multi-Alternative Dataset - MMLU (Large Multitask Language Understanding) (PDF)
This dataset consists of 57 duties throughout a number of domains contained inside the subjects of Humanities, Social Science, and STEM (science, know-how, engineering and math).
The researchers solely used the medical associated duties reminiscent of medical data, medical genetics, anatomy, skilled drugs, faculty biology and faculty drugs.
GPT-4 utilizing Medprompt completely bested all of the rivals it was examined towards throughout all 4 medical associated datasets.
Desk Exhibits How Medprompt Outscored Different Basis Fashions
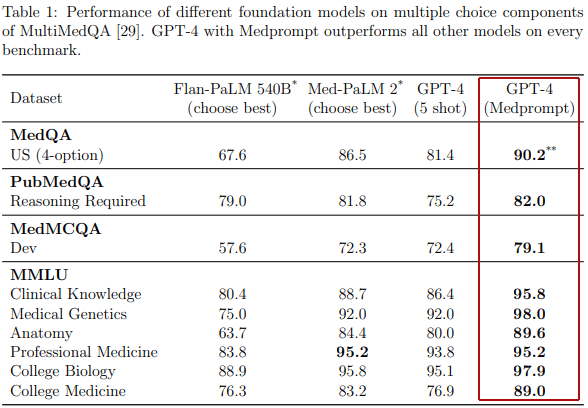
Why Medprompt is Vital
The researchers found that utilizing CoT reasoning, along with different prompting methods, may make a basic basis mannequin like GPT-4 outperform specialist fashions that have been skilled in only one area (space of data).
What makes this analysis particularly related for everybody who makes use of generative AI is that the MedPrompt method can be utilized to elicit prime quality output in any data space of experience, not simply the medical area.
The implications of this breakthrough is that it might not be essential to expend huge quantities of assets coaching a specialist massive language mannequin to be an knowledgeable in a selected space.
One solely wants to use the ideas of Medprompt to be able to acquire excellent generative AI output.
Three Prompting Methods
The researchers described three prompting methods:
- Dynamic few-shot choice
- Self-generated chain of thought
- Alternative shuffle ensembling
Dynamic Few-Shot Choice
Dynamic few-shot choice permits the AI mannequin to pick related examples throughout coaching.
Few-shot studying is a method for the foundational mannequin to study and adapt to particular duties with only a few examples.
On this technique, fashions study from a comparatively small set of examples (versus billions of examples), with the main target that the examples are consultant of a variety of questions related to the data area.
Historically, specialists manually create these examples, but it surely’s difficult to make sure they cowl all prospects. An alternate, referred to as dynamic few-shot studying, makes use of examples which might be just like the duties the mannequin wants to resolve, examples which might be chosen from a bigger coaching dataset.
Within the Medprompt method, the researchers chosen coaching examples which might be semantically just like a given take a look at case. This dynamic method is extra environment friendly than conventional strategies, because it leverages present coaching information with out requiring in depth updates to the mannequin.
Self-Generated Chain of Thought
The Self-Generated Chain of Thought method makes use of pure language statements to information the AI mannequin with a sequence of reasoning steps, automating the creation of chain-of-thought examples, which frees it from counting on human specialists.
The analysis paper explains:
“Chain-of-thought (CoT) makes use of pure language statements, reminiscent of “Let’s assume step-by-step,” to explicitly encourage the mannequin to generate a sequence of intermediate reasoning steps.
The method has been discovered to considerably enhance the flexibility of basis fashions to carry out complicated reasoning.
Most approaches to chain-of-thought heart on using specialists to manually compose few-shot examples with chains of thought for prompting. Quite than depend on human specialists, we pursued a mechanism to automate the creation of chain-of-thought examples.
We discovered that we may merely ask GPT-4 to generate chain-of-thought for the coaching examples utilizing the next immediate:
Self-generated Chain-of-thought Template## Query: {{query}} {{answer_choices}} ## Reply mannequin generated chain of thought clarification Subsequently, the reply is [final model answer (e.g. A,B,C,D)]"
The researchers realized that this technique may yield unsuitable outcomes (referred to as hallucinated outcomes). They solved this drawback by asking GPT-4 to carry out an extra verification step.
That is how the researchers did it:
“A key problem with this method is that self-generated CoT rationales have an implicit danger of together with hallucinated or incorrect reasoning chains.
We mitigate this concern by having GPT-4 generate each a rationale and an estimation of the most definitely reply to comply with from that reasoning chain.
If this reply doesn’t match the bottom reality label, we discard the pattern solely, underneath the belief that we can not belief the reasoning.
Whereas hallucinated or incorrect reasoning can nonetheless yield the proper closing reply (i.e. false positives), we discovered that this straightforward label-verification step acts as an efficient filter for false negatives.”
Alternative Shuffling Ensemble
An issue with a number of selection query answering is that basis fashions (GPT-4 is a foundational mannequin) can exhibit place bias.
Historically, place bias is a bent that people have for choosing the highest selections in a listing of selections.
For instance, analysis has found that if customers are offered with a listing of search outcomes, most individuals have a tendency to pick from the highest outcomes, even when the outcomes are unsuitable. Surprisingly, basis fashions exhibit the identical habits.
The researchers created a way to fight place bias when the inspiration mannequin is confronted with answering a a number of selection query.
This method will increase the variety of responses by defeating what’s referred to as “grasping decoding,” which is the habits of basis fashions like GPT-4 of selecting the most definitely phrase or phrase in a sequence of phrases or phrases.
In grasping decoding, at every step of producing a sequence of phrases (or within the context of a picture, pixels), the mannequin chooses the likeliest phrase/phrase/pixel (aka token) based mostly on its present context.
The mannequin makes a selection at every step with out consideration of the influence on the general sequence.
Alternative Shuffling Ensemble solves two issues:
- Place bias
- Grasping decoding
This the way it’s defined:
“To scale back this bias, we suggest shuffling the alternatives after which checking consistency of the solutions for the completely different type orders of the a number of selection.
Because of this, we carry out selection shuffle and self-consistency prompting. Self-consistency replaces the naive single-path or grasping decoding with a various set of reasoning paths when prompted a number of instances at some temperature> 0, a setting that introduces a level of randomness in generations.
With selection shuffling, we shuffle the relative order of the reply selections earlier than producing every reasoning path. We then choose probably the most constant reply, i.e., the one that’s least delicate to selection shuffling.
Alternative shuffling has an extra profit of accelerating the variety of every reasoning path past temperature sampling, thereby additionally bettering the standard of the ultimate ensemble.
We additionally apply this system in producing intermediate CoT steps for coaching examples. For every instance, we shuffle the alternatives some variety of instances and generate a CoT for every variant. We solely hold the examples with the proper reply.”
So, by shuffling selections and judging the consistency of solutions, this technique not solely reduces bias but in addition contributes to state-of-the-art efficiency in benchmark datasets, outperforming subtle specifically skilled fashions like Med-PaLM 2.
Cross-Area Success By Immediate Engineering
Lastly, what makes this analysis paper unimaginable is that the wins are relevant not simply to the medical area, the method can be utilized in any sort of data context.
The researchers write:
“We word that, whereas Medprompt achieves file efficiency on medical benchmark datasets, the algorithm is basic objective and isn’t restricted to the medical area or to a number of selection query answering.
We imagine the overall paradigm of mixing clever few-shot exemplar choice, self-generated chain of thought reasoning steps, and majority vote ensembling could be broadly utilized to different drawback domains, together with much less constrained drawback fixing duties.”
This is a crucial achievement as a result of it signifies that the excellent outcomes can be utilized on nearly any subject with out having to undergo the expense and time of intensely coaching a mannequin on particular data domains.
What Medprompt Means For Generative AI
Medprompt has revealed a brand new strategy to elicit enhanced mannequin capabilities, making generative AI extra adaptable and versatile throughout a spread of data domains for lots much less coaching and energy than beforehand understood.
The implications for the way forward for generative AI are profound, to not point out how this will likely affect the talent of immediate engineering.
Learn the brand new analysis paper:
Can Generalist Basis Fashions Outcompete Particular-Goal Tuning? Case Research in Drugs (PDF)
Featured Picture by Shutterstock/Asier Romero