

{kind=link}
Because the adage “a picture is value a thousand phrases” suggests, including photos as a second modality to 3D manufacturing offers substantial benefits over methods that solely use textual content. Photographs primarily present detailed, wealthy visible info that language could solely partially or not describe. A picture, for instance, could clearly and instantly specific minor traits like textures, colours, and spatial connections, however a phrase description could need assistance to completely symbolize the identical stage of element or use very lengthy explanations. As a result of the system can immediately reference precise visible cues as an alternative of deciphering written descriptions, which might fluctuate extensively in complexity and subjectivity, this visible specificity helps generate extra correct and detailed 3D fashions.
Moreover, customers could clarify their supposed outcomes extra merely and immediately after they make the most of visuals, particularly for people who discover it troublesome to specific their visions in phrases. This multimodal technique could serve a broader vary of inventive and sensible purposes, which mixes the contextual depth of textual content with the richness of visible information to supply a extra dependable, user-friendly, and efficient 3D manufacturing course of. Whereas helpful, utilizing photographs as a substitute modality for 3D object improvement additionally presents a number of difficulties. In distinction to textual content, photos have many further components, comparable to colour, texture, and spatial connections, making them harder to research and perceive accurately utilizing a single encoder like CLIP.
Moreover, a substantial variation in gentle, kind, or self-occlusion of the article would possibly lead to a view synthesis that could possibly be extra exact and constant, which might present incomplete or hazy 3D fashions. Superior, computationally demanding strategies are required to successfully decode visible info and assure constant look throughout many views as a result of complexity of picture processing. Researchers have remodeled 2D merchandise photos into 3D fashions utilizing numerous diffusion mannequin methodologies, comparable to Zero123 and different latest efforts. One downside of image-only methods is that, whereas the artificial views appear nice, the reconstructed fashions generally want extra geometric correctness and complex texturing, particularly relating to the article’s rear views. The primary reason behind this drawback is massive geometric discrepancies between the produced or synthesized views.
Because of this, non-matching pixels are averaged within the last 3D mannequin throughout reconstruction, leading to blurry textures and rounded geometry. In essence, image-conditioned 3D technology is an optimization drawback with extra restrictive restrictions in comparison with text-conditioned technology. As a result of a restricted amount of 3D information is out there, optimizing 3D fashions with exact options turns into harder as a result of the optimization course of tends to stray from the coaching distributions. As an example, if the coaching dataset comprises a variety of horse types, making a horse simply from textual content descriptions could lead to detailed fashions. Nonetheless, the novel-view texture creation could readily diverge from the taught distributions when a picture specifies particular fur options, shapes, and textures.
To sort out these points, the analysis staff from ByteDance supplies ImageDream on this work. The analysis staff proposes a multilevel image-prompt controller that may be simply included into the present structure whereas contemplating canonical digital camera coordination throughout numerous object situations. Specifically, in accordance with canonical digital camera coordination, the produced image should depict the article’s centered entrance view whereas utilizing the default digital camera settings (identification rotation and 0 translation). This makes the method of translating variations within the enter image to 3 dimensions less complicated. By offering hierarchical management, the multilevel controller streamlines the data switch course of by directing the diffusion mannequin from the image enter to each architectural block.
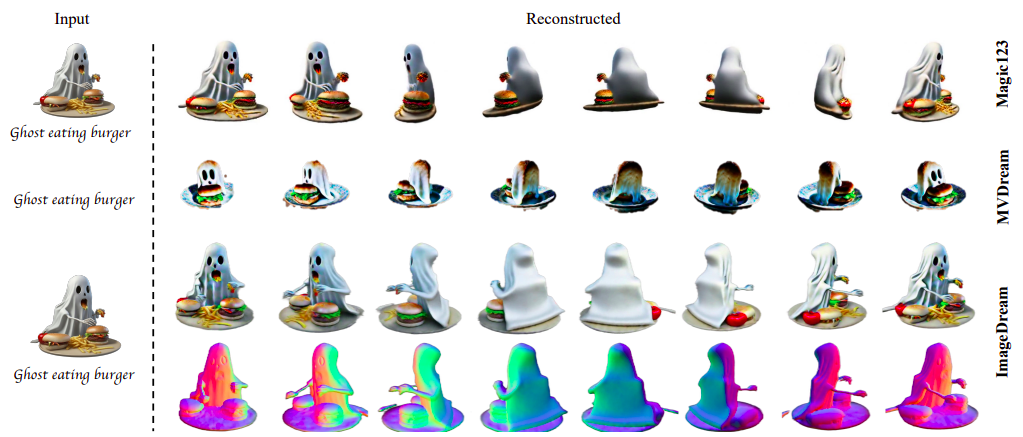
In comparison with strictly text-conditioned fashions like MVDream, ImageDream excels in producing objects with the suitable geometry from a given picture, as seen in Fig. 1. This permits customers to make use of well-developed picture technology fashions for improved image-text alignment. Concerning geometry and texture high quality, ImageDream outperforms present state-of-the-art (SoTA) zero-shot single-image 3D mannequin mills like Magic123. ImageDream outperforms earlier SoTA strategies, as proven by their thorough analysis within the experimental half, which incorporates quantitative assessments and qualitative comparisons by means of consumer checks.
Take a look at the Paper and Venture. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to affix our 33k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and Electronic mail E-newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Should you like our work, you’ll love our e-newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at the moment pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is obsessed with constructing options round it. He loves to attach with individuals and collaborate on attention-grabbing initiatives.