

{kind=link}
Within the realm of video technology, diffusion fashions have showcased outstanding developments. Nonetheless, a lingering problem persists—the unsatisfactory temporal consistency and unnatural dynamics in inference outcomes. The examine explores the intricacies of noise initialization in video diffusion fashions, uncovering a vital training-inference hole.
The examine addresses challenges in diffusion-based video technology, figuring out a training-inference hole in noise initialization that hinders temporal consistency and pure dynamics in current fashions. It reveals intrinsic variations in spatial-temporal frequency distribution between the coaching and inference phases. Researchers S-Lab and Nanyang Technological College launched FreeInit, a concise inference sampling technique; it iteratively refines low-frequency elements of preliminary noise throughout inference, successfully bridging the initialization hole.
The examine explores three classes of video technology fashions—GAN-based, transformer-based, and diffusion-based—emphasizing the progress of diffusion fashions in text-to-image and text-to-video technology. Specializing in diffusion-based strategies like VideoCrafter, AnimateDiff, and ModelScope reveals an implicit training-inference hole in noise initialization, impacting inference high quality.
Diffusion fashions, profitable in text-to-image technology, prolong to text-to-video with pretrained picture fashions and temporal layers. Regardless of this, a coaching inference hole in noise initialization hampers efficiency. FreeInit addresses this hole with out additional coaching, enhancing temporal consistency and refining visible look in generated frames. Evaluated on public text-to-video fashions, FreeInit considerably improves technology high quality, marking a key development in overcoming noise initialization challenges in diffusion-based video technology.
FreeInit is a technique addressing the initialization hole in video diffusion fashions by iteratively refining preliminary noise with out extra coaching. Utilized to publicly out there text-to-video fashions, AnimateDiff, ModelScope, and VideoCrafter, FreeInit considerably enhances inference high quality. The examine additionally explores the affect of frequency filters, together with Gaussian Low Move Filter and Butterworth Low Move Filter, on the stability between temporal consistency and visible high quality in generated movies. Analysis metrics embody frame-wise similarity and the DINO metric, using ViT-S16 DINO to evaluate temporal consistency and visible high quality.
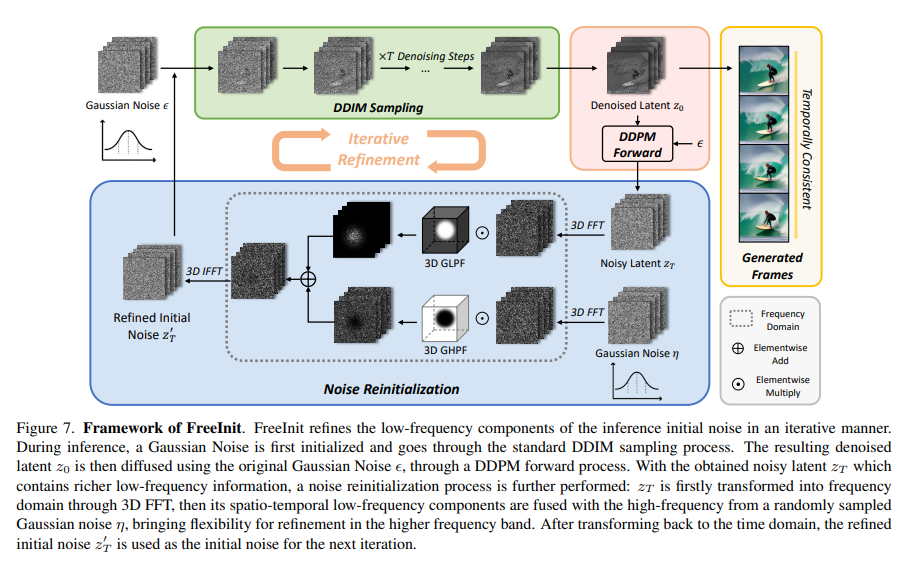
FreeInit markedly enhances temporal consistency in diffusion model-generated movies with out additional coaching. It seamlessly integrates into varied video diffusion fashions at inference, iteratively refining preliminary noise to bridge the training-inference hole. Analysis of text-to-video fashions like AnimateDiff, ModelScope, and VideoCrafter reveals a considerable enchancment in temporal consistency, starting from 2.92 to eight.62. Quantitative assessments on UCF-101 and MSR-VTT datasets reveal FreeInit’s superiority, as indicated by efficiency metrics like DINO rating, surpassing fashions with out noise reinitialization or utilizing completely different frequency filters.

To conclude, the whole examine may be summarized within the following factors:
- The analysis addresses a spot between coaching and inference in video diffusion fashions, which might have an effect on inference high quality.
- The researchers have proposed FreeInit, a concise and training-free sampling technique.
- FreeInit enhances temporal consistency when utilized to a few text-to-video fashions, leading to improved video technology with out extra coaching.
- The examine additionally explores frequency filters reminiscent of GLPF and Butterworth, additional bettering video technology.
- The outcomes present that FreeInit provides a sensible resolution to boost inference high quality in video diffusion fashions.
- FreeInit is straightforward to implement and requires no additional coaching or learnable parameters.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to affix our 34k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and E mail E-newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
In case you like our work, you’ll love our e-newsletter..
Howdy, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at the moment pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m captivated with know-how and wish to create new merchandise that make a distinction.