

{kind=link}
Transformer fashions are essential in machine studying for language and imaginative and prescient processing duties. Transformers, famend for his or her effectiveness in sequential knowledge dealing with, play a pivotal position in pure language processing and pc imaginative and prescient. They’re designed to course of enter knowledge in parallel, making them extremely environment friendly for giant datasets. Regardless, conventional Transformer architectures should enhance their capability to handle long-term dependencies inside sequences, a essential side for understanding context in language and pictures.
The central problem addressed within the present examine is the environment friendly and efficient modeling of long-term dependencies in sequential knowledge. Whereas adept at dealing with shorter sequences, conventional transformer fashions need assistance capturing in depth contextual relationships, primarily on account of computational and reminiscence constraints. This limitation turns into pronounced in duties requiring understanding long-range dependencies, reminiscent of in complicated sentence constructions in language modeling or detailed picture recognition in imaginative and prescient duties, the place the context might span throughout a variety of enter knowledge.
Current strategies to mitigate these limitations embody varied memory-based approaches and specialised consideration mechanisms. Nevertheless, these options typically enhance computational complexity or fail to seize sparse, long-range dependencies adequately. Strategies like reminiscence caching and selective consideration have been employed, however they both enhance the mannequin’s complexity or want to increase the mannequin’s receptive subject sufficiently. The present panorama of options underscores the necessity for a simpler technique to boost Transformers’ capability to course of lengthy sequences with out prohibitive computational prices.
Researchers from The Chinese language College of Hong Kong, The College of Hong Kong, and Tencent Inc. suggest an revolutionary method known as Cached Transformers, augmented with a Gated Recurrent Cache (GRC). This novel element is designed to boost Transformers’ functionality to deal with long-term relationships in knowledge. The GRC is a dynamic reminiscence system that effectively shops and updates token embeddings primarily based on their relevance and historic significance. This technique permits the Transformer to course of the present enter and draw on a wealthy, contextually related historical past, thereby considerably increasing its understanding of long-range dependencies.
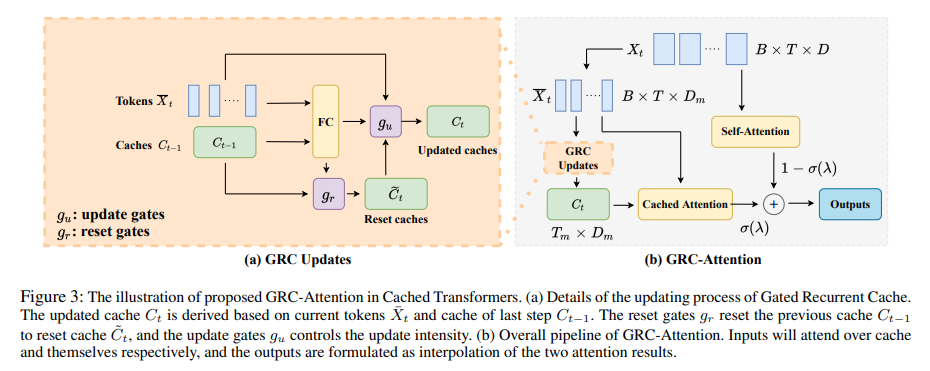
The GRC is a key innovation that dynamically updates a token embedding cache to symbolize historic knowledge effectively. This adaptive caching mechanism allows the Transformer mannequin to take care of a mixture of present and amassed data, considerably extending its capability to course of long-range dependencies. The GRC maintains a stability between the necessity to retailer related historic knowledge and the computational effectivity, thereby addressing the standard Transformer fashions’ limitations in dealing with lengthy sequential knowledge.
Integrating Cached Transformers with GRC demonstrates notable enhancements in language and imaginative and prescient duties. As an example, in language modeling, the improved Transformer fashions outfitted with GRC outperform conventional fashions, reaching decrease perplexity and better accuracy in complicated duties like machine translation. This enchancment is attributed to the GRC’s environment friendly dealing with of long-range dependencies, offering a extra complete context for every enter sequence. Such developments point out a big step ahead within the capabilities of Transformer fashions.
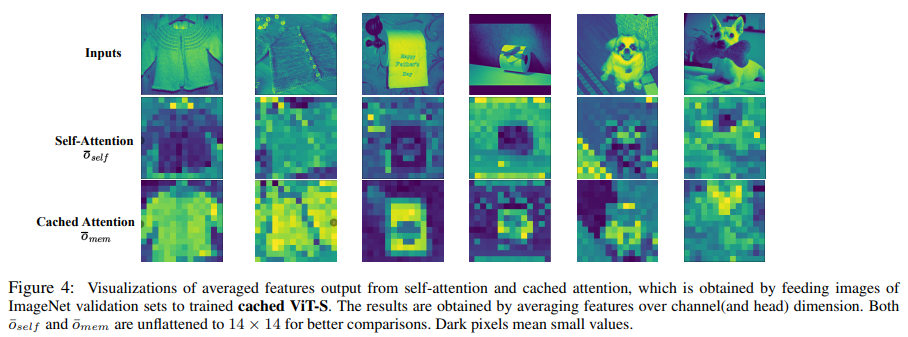
In conclusion, the analysis will be summarized within the following factors:
- The issue of modeling long-term dependencies in sequential knowledge is successfully tackled by Cached Transformers with GRC.
- The GRC mechanism considerably enhances the Transformers’ capability to grasp and course of prolonged sequences, thus bettering efficiency in each language and imaginative and prescient duties.
- This development represents a notable leap in machine studying, notably in how Transformer fashions deal with context and dependencies over lengthy knowledge sequences, setting a brand new normal for future developments within the subject.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to hitch our 35k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and E-mail E-newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
In case you like our work, you’ll love our publication..
Howdy, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m keen about expertise and wish to create new merchandise that make a distinction.