

{kind=link}
Object segmentation throughout photos and movies is a posh but pivotal activity. Historically, this area has witnessed a siloed development, with totally different duties similar to referring picture segmentation (RIS), few-shot picture segmentation (FSS), referring video object segmentation (RVOS), and video object segmentation (VOS) evolving independently. This disjointed improvement resulted in inefficiencies and an incapacity to leverage multi-task studying advantages successfully.
On the coronary heart of object segmentation challenges lies exactly figuring out and delineating objects. This turns into exponentially advanced in dynamic video contexts or includes deciphering objects primarily based on linguistic descriptions. For example, RIS usually requires the fusion of imaginative and prescient and language, demanding deep cross-modal integration. Then again, FSS emphasizes correlation-based strategies for dense semantic correspondence. Video segmentation duties have traditionally relied on space-time reminiscence networks for pixel-level matching. This divergence in methodologies led to specialised, task-specific fashions that consumed appreciable computational assets and wanted a unified strategy for multi-task studying.
Researchers from The College of Hong Kong, ByteDance, Dalian College of Know-how, and Shanghai AI Laboratory launched UniRef++, a revolutionary strategy to bridging these gaps. UniRef++ is a unified structure designed to seamlessly combine 4 vital object segmentation duties. Its innovation lies within the UniFusion module, a multiway-fusion mechanism that handles duties primarily based on their particular references. This module’s functionality to fuse info from visible and linguistic references is very essential for duties like RVOS, which require understanding language descriptions and monitoring objects throughout movies.
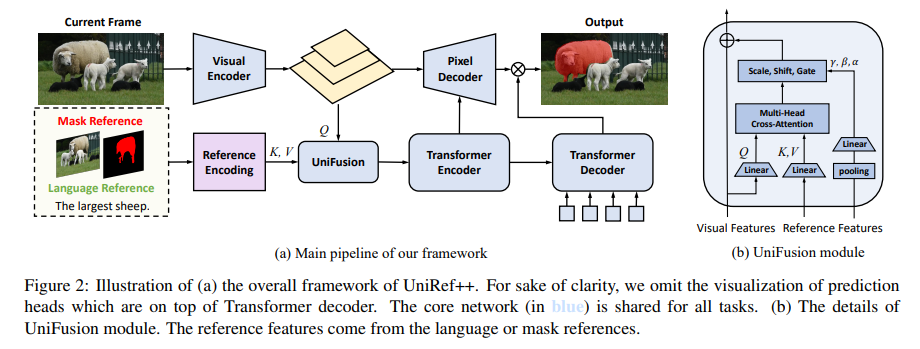
Not like different benchmarks, UniRef++ could also be collaboratively taught throughout a variety of actions, permitting it to soak up broad info that can be utilized for quite a lot of jobs. This technique works, as demonstrated by aggressive outcomes in FSS and VOS and superior efficiency in RIS and RVOS duties. UniRef++’s flexibility permits it to execute quite a few features at runtime with simply the proper references specified. This gives a versatile strategy that easily transitions between verbal and visible references.

The implementation of UniRef++ within the area of object segmentation is not only an incremental enchancment however a paradigm shift. Its unified structure addresses the longstanding inefficiencies of task-specific fashions and lays the groundwork for more practical multi-task studying in picture and video object segmentation. The mannequin’s capability to amalgamate varied duties beneath a single framework, transitioning seamlessly between linguistic and visible references, is exemplary. It units a brand new normal within the area, providing insights and instructions for future analysis and improvement.
Try the Paper and Code. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to hitch our 35k+ ML SubReddit, 41k+ Fb Group, Discord Channel, LinkedIn Group, and Electronic mail Publication, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Should you like our work, you’ll love our e-newsletter..
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is enthusiastic about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.