
{kind=link}
Picture by Creator
On this submit, we are going to discover the brand new state-of-the-art open-source mannequin known as Mixtral 8x7b. We may even discover ways to entry it utilizing the LLaMA C++ library and the way to run giant language fashions on decreased computing and reminiscence.
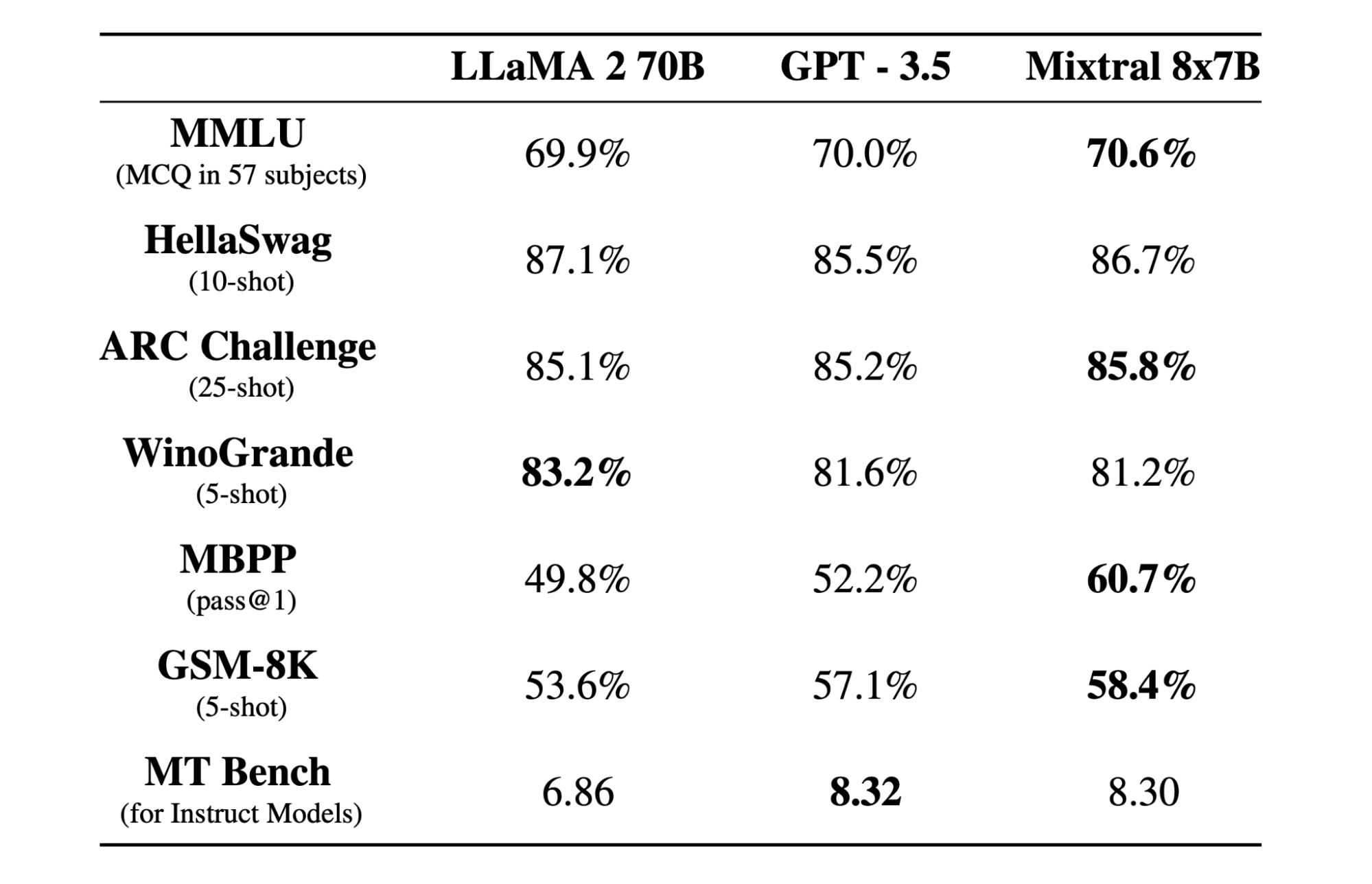
Mixtral 8x7b is a high-quality sparse combination of specialists (SMoE) mannequin with open weights, created by Mistral AI. It’s licensed beneath Apache 2.0 and outperforms Llama 2 70B on most benchmarks whereas having 6x sooner inference. Mixtral matches or beats GPT3.5 on most traditional benchmarks and is the very best open-weight mannequin relating to price/efficiency.
Picture from Mixtral of specialists
Mixtral 8x7B makes use of a decoder-only sparse mixture-of-experts community. This entails a feedforward block deciding on from 8 teams of parameters, with a router community selecting two of those teams for every token, combining their outputs additively. This technique enhances the mannequin’s parameter depend whereas managing price and latency, making it as environment friendly as a 12.9B mannequin, regardless of having 46.7B whole parameters.
Mixtral 8x7B mannequin excels in dealing with a large context of 32k tokens and helps a number of languages, together with English, French, Italian, German, and Spanish. It demonstrates sturdy efficiency in code technology and could be fine-tuned into an instruction-following mannequin, attaining excessive scores on benchmarks like MT-Bench.
LLaMA.cpp is a C/C++ library that gives a high-performance interface for big language fashions (LLMs) based mostly on Fb’s LLM structure. It’s a light-weight and environment friendly library that can be utilized for a wide range of duties, together with textual content technology, translation, and query answering. LLaMA.cpp helps a variety of LLMs, together with LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B, and GPT4ALL. It’s appropriate with all working methods and may operate on each CPUs and GPUs.
On this part, we shall be working the llama.cpp internet software on Colab. By writing just a few traces of code, it is possible for you to to expertise the brand new state-of-the-art mannequin efficiency in your PC or on Google Colab.
Getting Began
First, we are going to obtain the llama.cpp GitHub repository utilizing the command line under:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.git
After that, we are going to change listing into the repository and set up the llama.cpp utilizing the `make` command. We’re putting in the llama.cpp for the NVidia GPU with CUDA put in.
%cd llama.cpp
!make LLAMA_CUBLAS=1
Obtain the Mannequin
We are able to obtain the mannequin from the Hugging Face Hub by deciding on the suitable model of the `.gguf` mannequin file. Extra info on varied variations could be present in TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
Picture from TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
You need to use the command `wget` to obtain the mannequin within the present listing.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/predominant/mixtral-8x7b-instruct-v0.1.Q2_K.gguf
Exterior Deal with for LLaMA Server
After we run the LLaMA server it would give us a localhost IP which is ineffective for us on Colab. We want the connection to the localhost proxy through the use of the Colab kernel proxy port.
After working the code under, you’ll get the worldwide hyperlink. We are going to use this hyperlink to entry our webapp later.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/
Working the Server
To run the LLaMA C++ server, you want to present the server command with the situation of the mannequin file and the proper port quantity. It is necessary to be sure that the port quantity matches the one we initiated within the earlier step for the proxy port.
%cd /content material/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
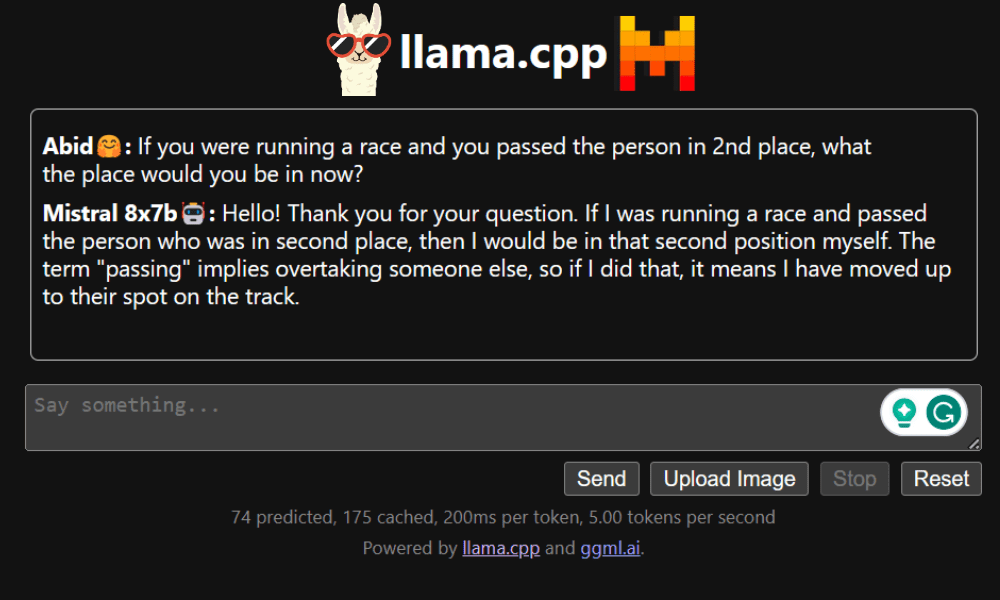
The chat webapp could be accessed by clicking on the proxy port hyperlink within the earlier step for the reason that server isn’t working domestically.
LLaMA C++ Webapp
Earlier than we start utilizing the chatbot, we have to customise it. Substitute “LLaMA” together with your mannequin title within the immediate part. Moreover, modify the person title and bot title to tell apart between the generated responses.
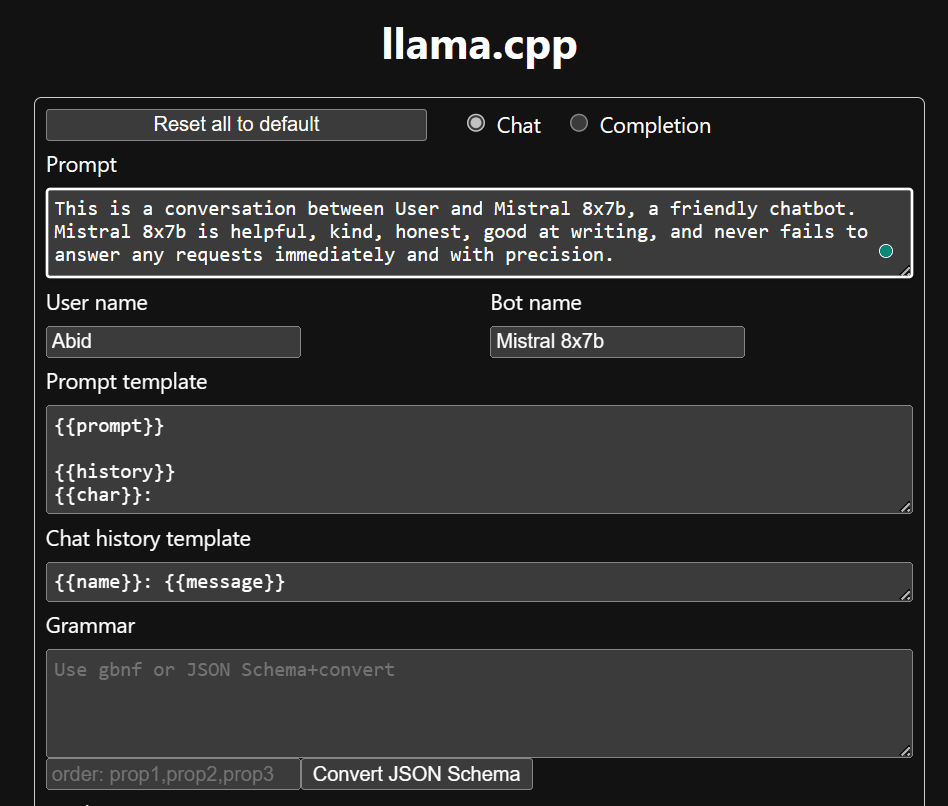
Begin chatting by scrolling down and typing within the chat part. Be at liberty to ask technical questions that different open supply fashions have did not reply correctly.
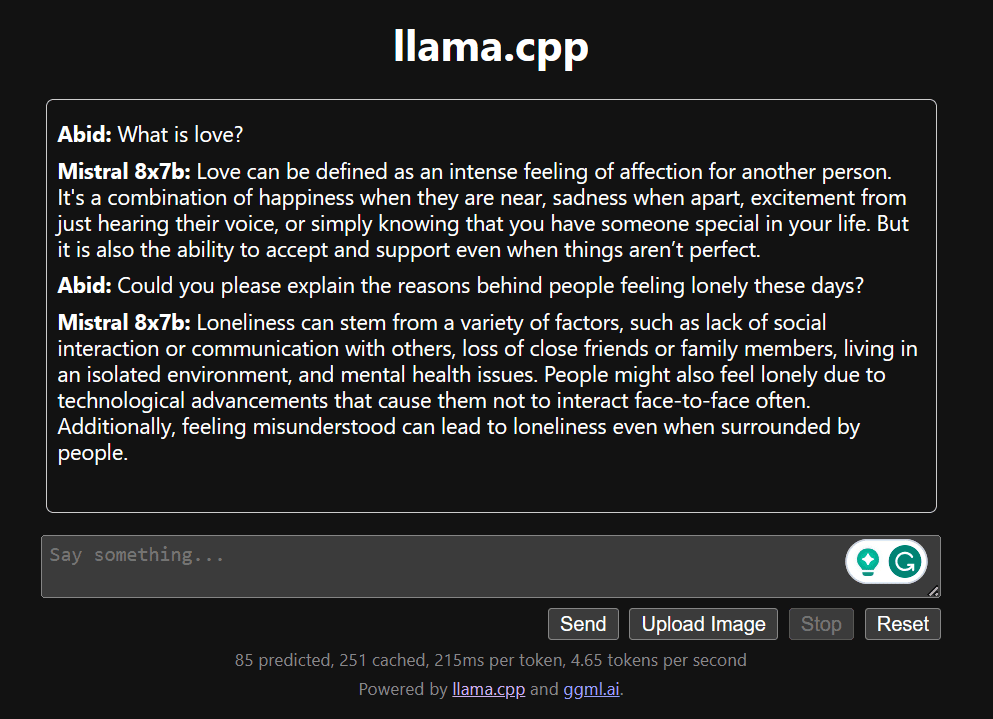
In the event you encounter points with the app, you’ll be able to attempt working it by yourself utilizing my Google Colab: https://colab.analysis.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
This tutorial gives a complete information on the way to run the superior open-source mannequin, Mixtral 8x7b, on Google Colab utilizing the LLaMA C++ library. In comparison with different fashions, Mixtral 8x7b delivers superior efficiency and effectivity, making it a superb resolution for many who wish to experiment with giant language fashions however don’t have intensive computational sources. You possibly can simply run it in your laptop computer or on a free cloud compute. It’s user-friendly, and you may even deploy your chat app for others to make use of and experiment with.
I hope you discovered this straightforward resolution to working the big mannequin useful. I’m all the time on the lookout for easy and higher choices. In case you have a fair higher resolution, please let me know, and I’ll cowl it subsequent time.
Abid Ali Awan (@1abidaliawan) is an authorized knowledge scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and knowledge science applied sciences. Abid holds a Grasp’s diploma in Know-how Administration and a bachelor’s diploma in Telecommunication Engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college kids battling psychological sickness.