
{kind=link}
Partnership Publish
If you happen to’re working in python with giant datasets, maybe a number of gigabytes in measurement, you’ll be able to seemingly relate to the frustration of ready hours on your queries to complete as your CPU-based pandas DataFrame struggles to carry out operations. This actual scenario is the place a pandas person ought to take into account leveraging the ability of GPUs for information processing with RAPIDS cuDF.
RAPIDS cuDF, with its pandas-like API, allows information scientists and engineers to rapidly faucet into the immense potential of parallel computing on GPUs–with just some code line modifications.
If you happen to’re unfamiliar with GPU acceleration, this submit is a simple introduction to the RAPIDS ecosystem and showcases the commonest performance of cuDF, the GPU-based pandas DataFrame counterpart.
Need a useful abstract of the following tips? Comply with together with the downloadable cuDF cheat sheet.
Leveraging GPUs with cuDF DataFrame
cuDF is an information science constructing block for the RAPIDS suite of GPU-accelerated libraries. It’s an EDA workhorse you should use to construct permitting information pipelines to course of information and derive new options. As a elementary element inside the RAPIDS suite, cuDF underpins the opposite libraries, solidifying its function as a standard constructing block. Like all parts within the RAPIDS suite, cuDF employs the CUDA backend to energy GPU computations.
Nevertheless, with a simple and acquainted Python interface, cuDF customers needn’t work together immediately with that layer.
How cuDF Can Make Your Information Science Work Sooner
Are you bored with watching the clock whereas your script runs? Whether or not you are dealing with string information or working with time collection, there are lots of methods you should use cuDF to drive your information work ahead.
- Time collection evaluation: Whether or not you are resampling information, extracting options, or conducting advanced computations, cuDF provides a considerable speed-up, probably as much as 880x quicker than pandas for time-series evaluation.
- Actual-time exploratory information evaluation (EDA): Looking via giant datasets could be a chore with conventional instruments, however cuDF’s GPU-accelerated processing energy makes real-time exploration of even the most important information units potential
- Machine studying (ML) information preparation: Pace up information transformation duties and put together your information for generally used ML algorithms, comparable to regression, classification and clustering, with cuDF’s acceleration capabilities. Environment friendly processing means faster mannequin growth and permits you to get in direction of the deployment faster.
- Massive-scale information visualization: Whether or not you are creating warmth maps for geographic information or visualizing advanced monetary traits, builders can deploy information visualization libraries with high-performance and high-FPS information visualization by utilizing cuDF and cuxfilter. This integration permits for real-time interactivity to turn out to be a significant element of your analytics cycle.
- Massive-scale information filtering and transformation: For big datasets exceeding a number of gigabytes, you’ll be able to carry out filtering and transformation duties utilizing cuDF in a fraction of the time it takes with pandas.
- String information processing: Historically, string information processing has been a difficult and sluggish job as a result of advanced nature of textual information. These operations are made easy with GPU-acceleration
- GroupBy operations: GroupBy operations are a staple in information evaluation however might be resource-intensive. cuDF hastens these duties considerably, permitting you to achieve insights quicker when splitting and aggregating your information

Acquainted interface for GPU processing
The core premise of RAPIDS is to supply a well-recognized person expertise to well-liked information science instruments in order that the ability of NVIDIA GPUs is definitely accessible for all practitioners. Whether or not you’re performing ETL, constructing ML fashions, or processing graphs, if you realize pandas, NumPy, scikit-learn or NetworkX, you’ll really feel at dwelling when utilizing RAPIDS.
Switching from CPU to GPU Information Science stack has by no means been simpler: with as little change as importing cuDF as a substitute of pandas, you’ll be able to harness the big energy of NVIDIA GPUs, dashing up the workloads 10-100x (on the low finish), and having fun with extra productiveness — all whereas utilizing your favourite instruments.
Verify the pattern code beneath that presents how acquainted cuDF API is to anybody utilizing pandas.
import pandas as pd
import cudf
df_cpu = pd.read_csv('/information/pattern.csv')
df_gpu = cudf.read_csv('/information/pattern.csv')
Loading information out of your favourite information sources
Studying and writing capabilities of cuDF have grown considerably for the reason that first launch of RAPIDS in October 2018. The information might be native to a machine, saved in an on-prem cluster, or within the cloud. cuDF makes use of fsspec library to summary many of the file-system associated duties so you’ll be able to give attention to what issues essentially the most: creating options and constructing your mannequin.
Because of fsspec studying information from both native or cloud file system requires solely offering credentials to the latter. The instance beneath reads the identical file from two totally different places,
import cudf
df_local = cudf.read_csv('/information/pattern.csv')
df_remote = cudf.read_csv(
's3://<bucket>/pattern.csv'
, storage_options = {'anon': True})
cuDF helps a number of file codecs: text-based codecs like CSV/TSV or JSON, columnar-oriented codecs like Parquet or ORC, or row-oriented codecs like Avro. When it comes to file system help, cuDF can learn information from native file system, cloud suppliers like AWS S3, Google GS, or Azure Blob/Information Lake, on- or off-prem Hadoop Recordsdata Methods, and likewise immediately from HTTP or (S)FTP net servers, Dropbox or Google Drive, or Jupyter File System.
Creating and saving DataFrames with ease
Studying information shouldn’t be the one strategy to create cuDF DataFrames. In truth, there are at the least 4 methods to take action:
From a listing of values you’ll be able to create DataFrame with one column,
cudf.DataFrame([1,2,3,4], columns=['foo'])
Passing a dictionary if you wish to create a DataFrame with a number of columns,
cudf.DataFrame({
'foo': [1,2,3,4]
, 'bar': ['a','b','c',None]
})
Creating an empty DataFrame and assigning to columns,
df_sample = cudf.DataFrame()
df_sample['foo'] = [1,2,3,4]
df_sample['bar'] = ['a','b','c',None]
Passing a listing of tuples,
cudf.DataFrame([
(1, 'a')
, (2, 'b')
, (3, 'c')
, (4, None)
], columns=['ints', 'strings'])
It’s also possible to convert to and from different reminiscence representations:
- From an inside GPU matrix represented as an DeviceNDArray,
- By means of DLPack reminiscence objects used to share tensors between deep studying frameworks and Apache Arrow format that facilitates a way more handy approach of manipulating reminiscence objects from varied programming languages,
- To changing to and from pandas DataFrames and Collection.
As well as, cuDF helps saving the info saved in a DataFrame into a number of codecs and file programs. In truth, cuDF can retailer information in all of the codecs it will probably learn.
All of those capabilities make it potential to stand up and working rapidly it doesn’t matter what your job is or the place your information lives.
Extracting, remodeling, and summarizing information
The basic information science job, and the one that each one information scientists complain about, is cleansing, featurizing and getting acquainted with the dataset. We spend 80% of our time doing that. Why does it take a lot time?
One of many causes is as a result of the questions we ask the dataset take too lengthy to reply. Anybody who has tried to learn and course of a 2GB dataset on a CPU is aware of what we’re speaking about.
Moreover, since we’re human and we make errors, rerunning a pipeline would possibly rapidly flip right into a full day train. This leads to misplaced productiveness and, seemingly, a espresso habit if we check out the chart beneath.
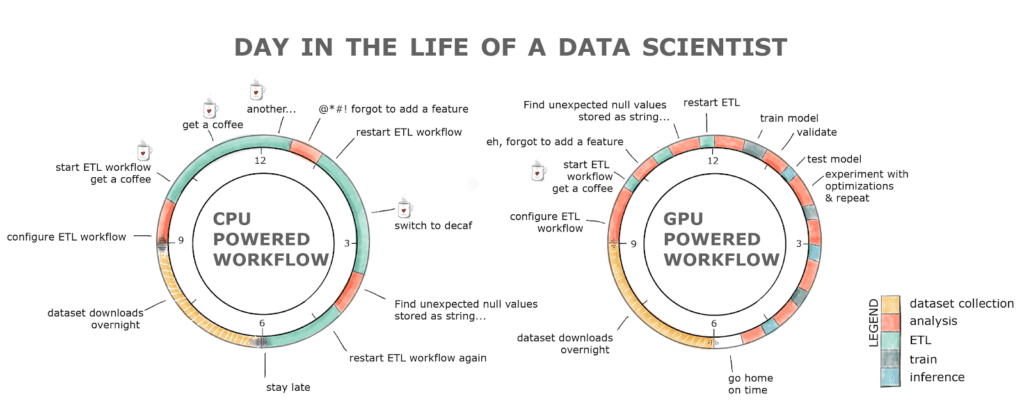
Determine 1. Typical workday for a developer utilizing a GPU- vs. CPU-powered workflow
RAPIDS with the GPU-powered workflow alleviates all these hurdles. The ETL stage is often anyplace between 8-20x quicker, so loading that 2GB dataset takes seconds in comparison with minutes on a CPU, cleansing and remodeling the info can be orders of magnitude quicker! All this with a well-recognized interface and minimal code modifications.
Working with strings and dates on GPUs
Not more than 5 years in the past working with strings and dates on GPUs was thought of nearly unattainable and past the attain of low-level programming languages like CUDA. In any case, GPUs had been designed to course of graphics, that’s, to govern giant arrays and matrices of ints and floats, not strings or dates.
RAPIDS permits you to not solely learn strings into the GPU reminiscence, but additionally extract options, course of, and manipulate them. In case you are acquainted with Regex then extracting helpful data from a doc on a GPU is now a trivial job because of cuDF. For instance, if you wish to discover and extract all of the phrases in your doc that match the [a-z]*movement sample (like, informationmovement, workmovement, or movement) all you have to do is,
df['string'].str.findall('([a-z]*movement)')
Extracting helpful options from dates or querying the info for a selected time frame has turn out to be simpler and quicker because of RAPIDS as nicely.
dt_to = dt.datetime.strptime("2020-10-03", "%Y-%m-%d")
df.question('dttm <= @dt_to')
Empowering Pandas Customers with GPU-acceleration
The transition from a CPU to a GPU information science stack is easy with RAPIDS. Importing cuDF as a substitute of pandas is a small change that may ship immense advantages. Whether or not you are engaged on an area GPU field or scaling as much as full-fledged information facilities, the GPU-accelerated energy of RAPIDS supplies 10-100x pace enhancements (on the low finish). This not solely results in elevated productiveness but additionally permits for environment friendly utilization of your favourite instruments, even in essentially the most demanding, large-scale situations.
RAPIDS has actually revolutionized the panorama of information processing, enabling information scientists to finish duties in minutes that after took hours and even days, resulting in elevated productiveness and decrease general prices.
To get began on making use of these strategies to your dataset, learn the accelerated information analytics collection on NVIDIA Technical Weblog.
Editor’s Observe: This submit was up to date with permission and initially tailored from the NVIDIA Technical Weblog.