
{kind=link}
Picture by Writer
Over the previous few years, Giant Language Fashions?—?or LLMs for associates?—?have taken the world of synthetic intelligence by storm.
With the groundbreaking launch of OpenAI’s GPT-3 in 2020, we’ve witnessed a gentle surge within the reputation of LLMs, which has solely intensified with latest developments within the discipline.
These highly effective AI fashions have opened up new potentialities for pure language processing functions, enabling builders to create extra subtle, human-like interactions.
Isn’t it?
Nevertheless, when coping with this AI know-how it’s onerous to scale and generate dependable algorithms.
Amidst this quickly evolving panorama, LangChain has emerged as a flexible framework designed to assist builders harness the complete potential of LLMs for a variety of functions. One of the crucial vital use circumstances is to cope with massive quantities of textual content information.
Let’s dive in and begin harnessing the facility of LLMs in the present day!
LangChain can be utilized in chatbots, question-answering techniques, summarization instruments, and past. Nevertheless, probably the most helpful – and used – functions of LangChain is coping with textual content.
Right this moment’s world is flooded with information. And probably the most infamous sorts is textual content information.
All web sites and apps are being bombed with tons and tons of phrases each single day. No human can course of this quantity of data…
However can computer systems?
LLM methods along with LangChain are an effective way to cut back the quantity of textual content whereas sustaining a very powerful elements of the message. This is the reason in the present day we are going to cowl two fundamental — however actually helpful — use circumstances of LangChain to cope with textual content.
- Summarization: Categorical a very powerful details a few physique of textual content or chat interplay. It could possibly cut back the quantity of knowledge whereas sustaining a very powerful elements.
- Extraction: Pull structured information from a physique of textual content or some consumer question. It could possibly detect and extract key phrases throughout the textual content.
Whether or not you’re new to the world of LLMs or seeking to take your language technology tasks to the subsequent degree, this information will give you priceless insights and hands-on examples to unlock the complete potential of LangChain to cope with textual content.
⚠️ If you wish to have some fundamental grasp, you possibly can go examine 👇🏻
LangChain 101: Construct Your Personal GPT-Powered Functions — KDnuggets
All the time keep in mind that for working with OpenAI and GPT fashions, we have to have the OpenAI library put in on our native laptop and have an energetic OpenAI key. In the event you have no idea how to do this, you possibly can go examine right here.
ChatGPT along with LangChain can summarize info rapidly and in a really dependable approach.
LLM summarization methods are an effective way to cut back the quantity of textual content whereas sustaining a very powerful elements of the message. This is the reason LLMs will be the most effective ally to any digital firm that should course of and analyze massive volumes of textual content information.
To carry out the next examples, the next libraries are required:
# LangChain & LLM
from langchain.llms import OpenAI
from langchain import PromptTemplate
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
#Wikipedia API
import wikipediaapi
1.1. Quick textual content summarization
For summaries of brief texts, the strategy is easy, the truth is, you don’t have to do something fancy apart from easy prompting with directions.
Which mainly means producing a template with an enter variable.
I do know you could be questioning… what is strictly a immediate template?
A immediate template refers to a reproducible method to generate a immediate. It comprises a textual content string – a template – that may absorb a set of parameters from the tip consumer and generates a immediate.
A immediate template comprises:
- directions to the language mannequin – that permit us to standardize some steps for our LLM.
- an enter variable – that enables us to use the earlier directions to any enter textual content.
Let’s see this in a easy instance. I can standardize a immediate that generates a reputation of a model that produces a selected product.

Screenshot of my Jupyter Pocket book.
As you possibly can observe within the earlier instance, the magic of LangChain is that we will outline a standardized immediate with a altering enter variable.
- The directions to generate a reputation for a model stay at all times the identical.
- The product variable works as an enter that may be modified.
This enables us to outline versatile prompts that can be utilized in several situations.
So now that we all know what a immediate template is…
Let’s think about we need to outline a immediate that summarizes any textual content utilizing tremendous easy-to-understand vocabulary. We will outline a immediate template with some particular directions and a textual content variable that adjustments relying on the enter variable we outline.
# Create our immediate string.
template = """
%INSTRUCTIONS:
Please summarize the next textual content.
All the time use easy-to-understand vocabulary so an elementary faculty scholar can perceive.
%TEXT:
{input_text}
"""
Now we outline the LLM we need to work with - OpenAI’s GPT in my case - and the immediate template.
# The default mannequin is already 'text-davinci-003', however it may be modified.
llm = OpenAI(temperature=0, model_name="text-davinci-003", openai_api_key=openai_api_key)
# Create a LangChain immediate template that we will insert values to later
immediate = PromptTemplate(
input_variables=["input_text"],
template=template,
)
So let’s do this immediate template. Utilizing the wikipedia API, I’m going to get the abstract of the USA nation and additional summarize it in a very easy-to-understand tone.
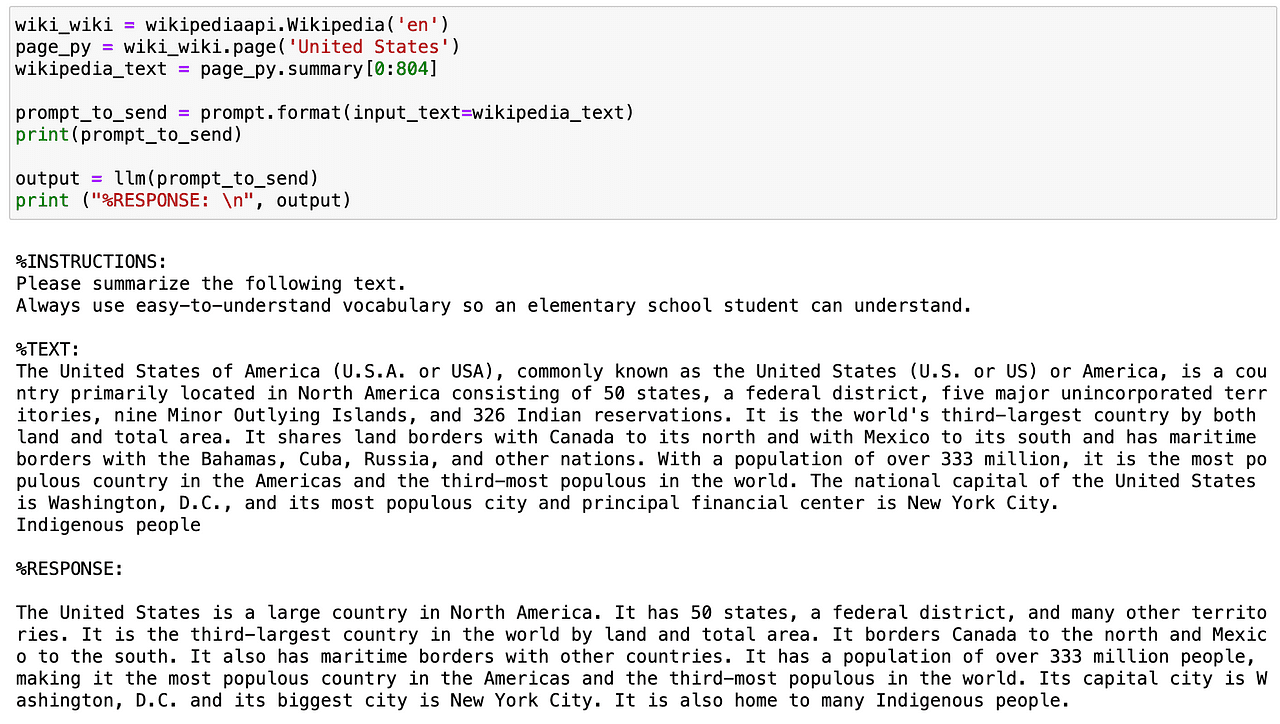
Screenshot of my Jupyter Pocket book.
So now that we all know tips on how to summarize a brief textual content… can I spice this up a bit?
Certain we will with…
1.2. Lengthy textual content summarization
When coping with lengthy texts, the primary downside is that we can not talk them to our AI mannequin immediately by way of immediate, as they comprise too many tokens.
And now you could be questioning… what’s a token?
Tokens are how the mannequin sees the enter — single characters, phrases, elements of phrases, or segments of textual content. As you possibly can observe, the definition will not be actually exact and it depends upon each mannequin. As an illustration, OpenAI’s GPT 1000 tokens are roughly 750 phrases.
However a very powerful factor to be taught is that our price depends upon the variety of tokens and that we can not ship as many tokens as we would like in a single immediate. To have an extended textual content, we are going to repeat the identical instance as earlier than however utilizing the entire Wikipedia web page textual content.
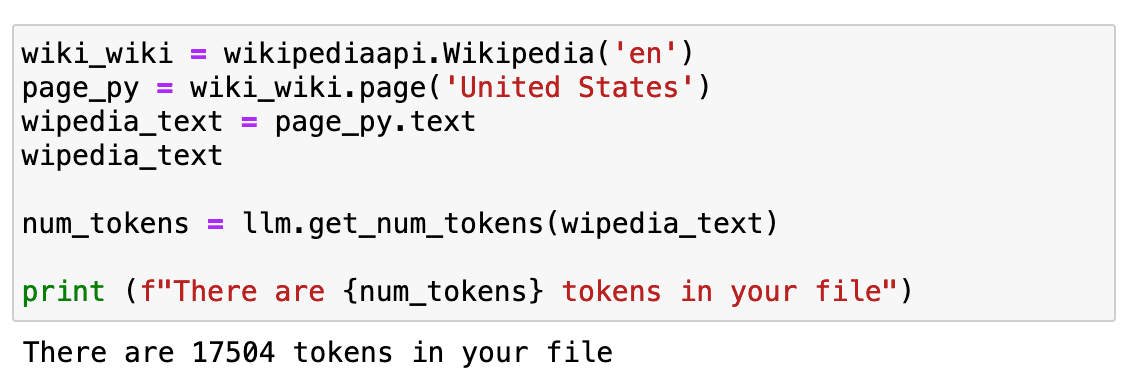
Screenshot of my Jupyter Pocket book.
If we examine how lengthy it’s… it’s round 17K tokens.
Which is quite a bit to be despatched on to our API.
So what now?
First, we’ll want to separate it up. This course of is known as chunking or splitting your textual content into smaller items. I normally use RecursiveCharacterTextSplitter as a result of it’s simple to regulate however there are a bunch you possibly can attempt.
After utilizing it, as an alternative of simply having a single piece of textual content, we get 23 items which facilitate the work of our GPT mannequin.
Subsequent we have to load up a series which can make successive calls to the LLM for us.
LangChain gives the Chain interface for such chained functions. We outline a Chain very generically as a sequence of calls to parts, which might embody different chains. The bottom interface is straightforward:
class Chain(BaseModel, ABC):
"""Base interface that every one chains ought to implement."""
reminiscence: BaseMemory
callbacks: Callbacks
def __call__(
self,
inputs: Any,
return_only_outputs: bool = False,
callbacks: Callbacks = None,
) -> Dict[str, Any]:
...
If you wish to be taught extra about chains, you possibly can go examine immediately within the LangChain documentation.
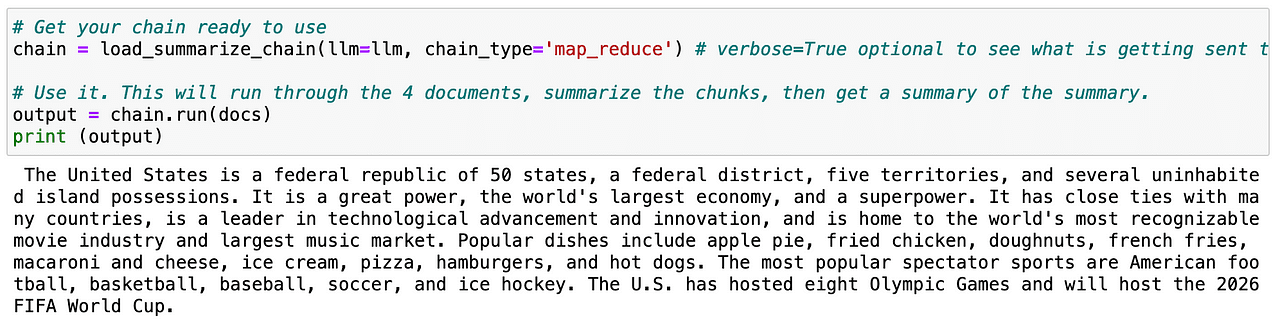
So if we repeat once more the identical process with the splitted textual content – known as docs – the LLM can simply generate a abstract of the entire web page.

Screenshot of my Jupyter Pocket book.
Helpful proper?
So now that we all know tips on how to summarize textual content, we will transfer to the second use case!
Extraction is the method of parsing information from a bit of textual content. That is generally used with output parsing to construction our information.
Extracting key information is de facto helpful with a purpose to determine and parse key phrases inside a textual content. Widespread use circumstances are extracting a structured row from a sentence to insert right into a database or extracting a number of rows from a protracted doc to insert right into a database.
Let’s think about we’re working a digital e-commerce firm and we have to course of all critiques which are said on our web site.
I might go learn all of them one after the other… which might be loopy.
Or I can merely EXTRACT the knowledge that I want from every of them and analyze all the information.
Sounds simple… proper?
Let’s begin with a fairly easy instance. First, we have to import the next libraries:
# To assist assemble our Chat Messages
from langchain.schema import HumanMessage
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
# We can be utilizing a chat mannequin, defaults to gpt-3.5-turbo
from langchain.chat_models import ChatOpenAI
# To parse outputs and get structured information again
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
chat_model = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", openai_api_key=openai_api_key)
2.1. Extracting particular phrases
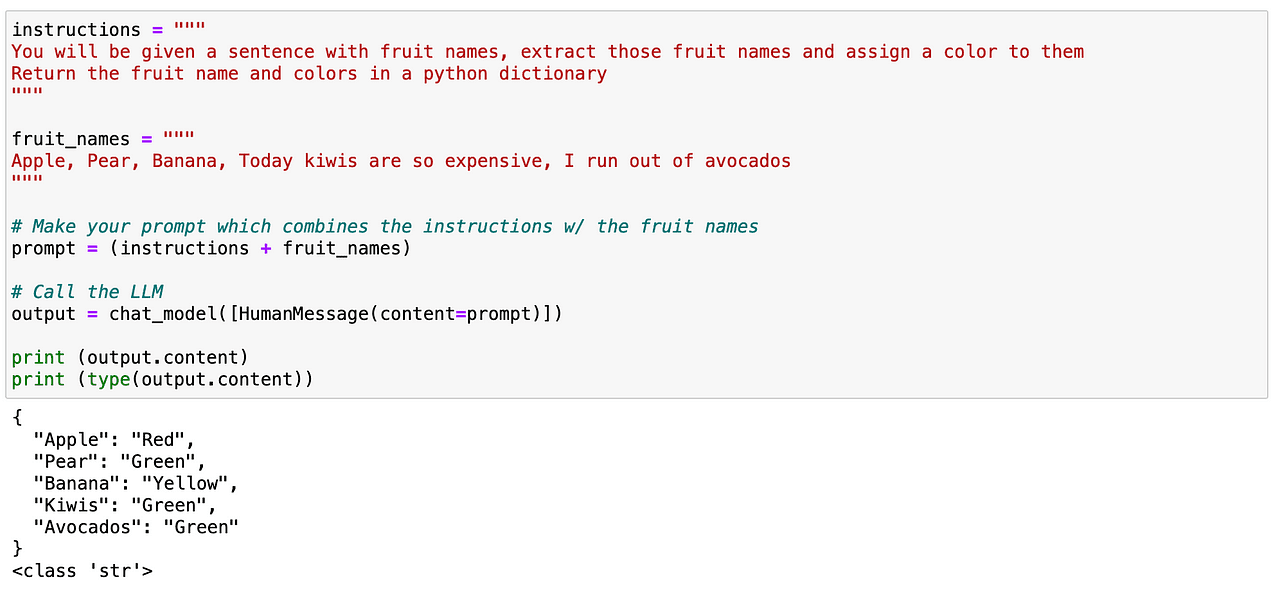
I can attempt to search for particular phrases inside some textual content. On this case, I need to parse all fruits which are contained inside a textual content. Once more, it’s fairly simple as earlier than. We will simply outline a immediate giving clear directions to our LLM stating that identifies all fruits contained in a textual content and provides again a JSON-like construction containing such fruits and their corresponding colours.
Screenshot of my Jupyter Pocket book.
And as we will see earlier than, it really works completely!
So now… let’s play just a little bit extra with it. Whereas this labored this time, it’s not a long run dependable methodology for extra superior use circumstances. And that is the place a implausible LangChain idea comes into play…
2.2. Utilizing LangChain’s Response Schema
LangChain’s response schema will do two most important issues for us:
- Generate a immediate with bonafide format directions. That is nice as a result of I don’t want to fret in regards to the immediate engineering facet, I’ll go away that as much as LangChain!
- Learn the output from the LLM and switch it into a correct python object for me. Which implies, at all times generate a given construction that’s helpful and that my system can parse.
And to take action, I simply have to outline what response I besides from the mannequin.
So let’s think about I need to decide the merchandise and types that customers are stating of their feedback. I might simply carry out as earlier than with a easy immediate – make the most of LangChain to generate a extra dependable methodology.
So first I have to outline a response_schema the place I outline each key phrase I need to parse with a reputation and an outline.
# The schema I need out
response_schemas = [
ResponseSchema(name="product", description="The name of the product to be bought"),
ResponseSchema(name="brand", description= "The brand of the product.")
]
After which I generate an output_parser object that takes as an enter my response_schema.
# The parser that may search for the LLM output in my schema and return it again to me
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
After defining our parser, we generate the format of our instruction utilizing the .get_format_instructions() command from LangChain and outline the ultimate immediate utilizing the ChatPromptTemplate. And now it’s as simple as utilizing this output_parser object with any enter question I can consider, and it’ll mechanically generate an output with my desired key phrases.
Screenshot of my Jupyter Pocket book.
As you possibly can observe within the instance under, with the enter of “I run out of Yogurt Danone, No-brand Oat Milk and people vegan bugers made by Heura”, the LLM provides me the next output:

Screenshot of my Jupyter Pocket book.
LangChain is a flexible Python library that helps builders harness the complete potential of LLMs, particularly for coping with massive quantities of textual content information. It excels at two most important use circumstances for coping with textual content. LLMs allow builders to create extra subtle and human-like interactions in pure language processing functions.
- Summarization: LangChain can rapidly and reliably summarize info, decreasing the quantity of textual content whereas preserving a very powerful elements of the message.
- Extraction: The library can parse information from a bit of textual content, permitting for structured output and enabling duties like inserting information right into a database or making API calls primarily based on extracted parameters.
- LangChain facilitates immediate engineering, which is an important method for maximizing the efficiency of AI fashions like ChatGPT. With immediate engineering, builders can design standardized prompts that may be reused throughout totally different use circumstances, making the AI software extra versatile and efficient.
Total, LangChain serves as a strong device to reinforce AI utilization, particularly when coping with textual content information, and immediate engineering is a key ability for successfully leveraging AI fashions like ChatGPT in numerous functions.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is presently working within the Information Science discipline utilized to human mobility. He’s a part-time content material creator targeted on information science and know-how. You possibly can contact him on LinkedIn, Twitter or Medium.