
{kind=link}

Picture by Freepik
In machine studying duties, classification is a supervised studying technique to foretell the label given the enter knowledge. For instance, we wish to predict if somebody is within the gross sales providing utilizing their historic options. By coaching the machine studying mannequin utilizing accessible coaching knowledge, we are able to carry out the classification duties to incoming knowledge.
We regularly encounter basic classification duties resembling binary classification (two labels) and multiclass classification (greater than two labels). On this case, we might practice the classifier, and the mannequin would attempt to predict one of many labels from all of the accessible labels. The dataset used for the classification is much like the picture beneath.
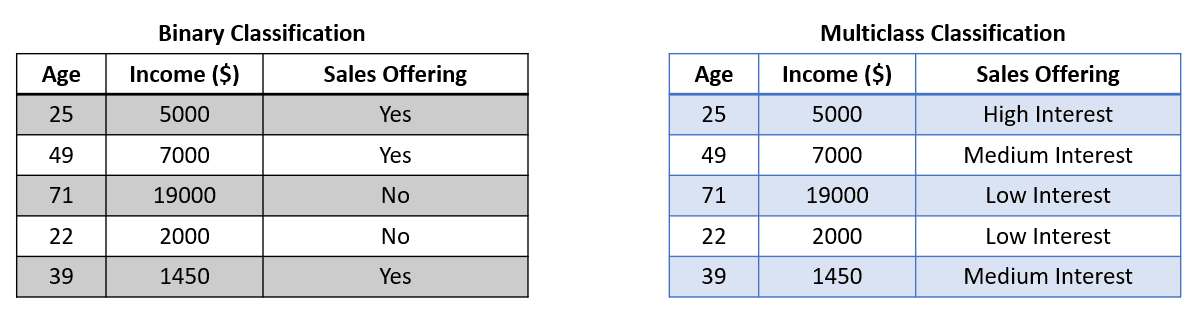
The picture above exhibits that the goal (Gross sales Providing) comprises two labels in Binary Classification and three within the Multiclass Classification. The mannequin would practice from the accessible options after which output one label solely.
Multilabel Classification is totally different from Binary or Multiclass Classification. In Multilabel Classification, we don’t attempt to predict solely with one output label. As a substitute, Multilabel Classification would attempt to predict knowledge with as many labels as attainable that apply to the enter knowledge. The output could possibly be from no label to the utmost variety of accessible labels.
Multilabel Classification is commonly used within the textual content knowledge classification activity. For instance, right here is an instance dataset for Multilabel Classification.
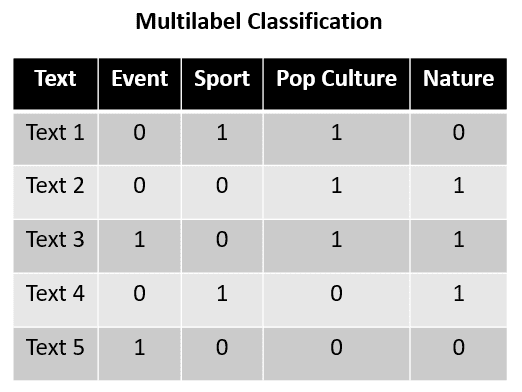
Within the instance above, think about Textual content 1 to Textual content 5 is a sentence that may be categorized into 4 classes: Occasion, Sport, Pop Tradition, and Nature. With the coaching knowledge above, the Multilabel Classification activity predicts which label applies to the given sentence. Every class isn’t towards the opposite as they aren’t mutually unique; every label may be thought of unbiased.
For extra element, we are able to see that Textual content 1 labels Sport and Pop Tradition, whereas Textual content 2 labels Pop Tradition and Nature. This exhibits that every label was mutually unique, and Multilabel Classification can have prediction output as not one of the labels or all of the labels concurrently.
With that introduction, let’s attempt to construct Multiclass Classifier with Scikit-Study.
This tutorial will use the publicly accessible Biomedical PubMed Multilabel Classification dataset from Kaggle. The dataset would include numerous options, however we might solely use the abstractText characteristic with their MeSH classification (A: Anatomy, B: Organism, C: Illnesses, and many others.). The pattern knowledge is proven within the picture beneath.
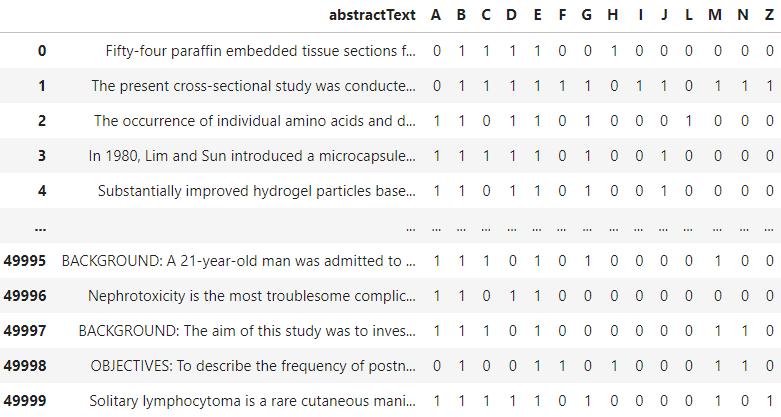
The above dataset exhibits that every paper may be categorized into multiple class, the circumstances for Multilabel Classification. With this dataset, we are able to construct Multilabel Classifier with Scikit-Study. Let’s put together the dataset earlier than we practice the mannequin.
import pandas as pd
from sklearn.feature_extraction.textual content import TfidfVectorizer
df = pd.read_csv('PubMed Multi Label Textual content Classification Dataset Processed.csv')
df = df.drop(['Title', 'meshMajor', 'pmid', 'meshid', 'meshroot'], axis =1)
X = df["abstractText"]
y = np.asarray(df[df.columns[1:]])
vectorizer = TfidfVectorizer(max_features=2500, max_df=0.9)
vectorizer.match(X)
Within the code above, we remodel the textual content knowledge into TF-IDF illustration so our Scikit-Study mannequin can settle for the coaching knowledge. Additionally, I’m skipping the preprocessing knowledge steps, resembling stopword removing, to simplify the tutorial.
After knowledge transformation, we cut up the dataset into coaching and check datasets.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=101)
X_train_tfidf = vectorizer.remodel(X_train)
X_test_tfidf = vectorizer.remodel(X_test)
After all of the preparation, we might begin coaching our Multilabel Classifier. In Scikit-Study, we might use the MultiOutputClassifier object to coach the Multilabel Classifier mannequin. The technique behind this mannequin is to coach one classifier per label. Principally, every label has its personal classifier.
We’d use Logistic Regression on this pattern, and MultiOutputClassifier would lengthen them into all labels.
from sklearn.multioutput import MultiOutputClassifier
from sklearn.linear_model import LogisticRegression
clf = MultiOutputClassifier(LogisticRegression()).match(X_train_tfidf, y_train)
We will change the mannequin and tweak the mannequin parameter that handed into the MultiOutputClasiffier, so handle based on your necessities. After the coaching, let’s use the mannequin to foretell the check knowledge.
prediction = clf.predict(X_test_tfidf)
prediction
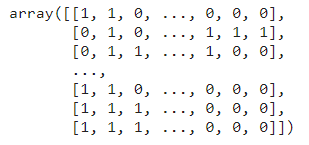
The prediction result’s an array of labels for every MeSH class. Every row represents the sentence, and every column represents the label.
Lastly, we have to consider our Multilabel Classifier. We will use the accuracy metrics to guage the mannequin.
from sklearn.metrics import accuracy_score
print('Accuracy Rating: ', accuracy_score(y_test, prediction))
Accuracy Rating: 0.145
The accuracy rating result’s 0.145, which exhibits that the mannequin solely may predict the precise label mixture lower than 14.5% of the time. Nonetheless, the accuracy rating comprises weaknesses for a multilabel prediction analysis. The accuracy rating would want every sentence to have all of the label presence within the precise place, or it will be thought of unsuitable.
For instance, the first-row prediction solely differs by one label between the prediction and check knowledge.
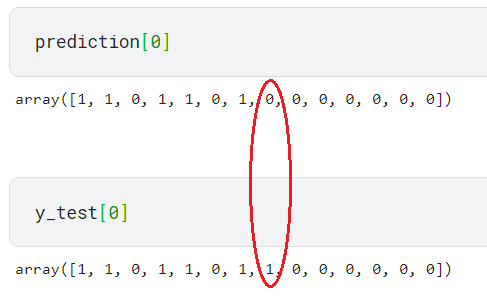
It will be thought of a unsuitable prediction for the accuracy rating because the label mixture differs. That’s the reason our mannequin has a low metric rating.
To mitigate this downside, we should consider the label prediction somewhat than their label mixture. On this case, we are able to depend on Hamming Loss analysis metric. Hamming Loss is calculated by taking a fraction of the unsuitable prediction with the full variety of labels. As a result of Hamming Loss is a loss operate, the decrease the rating is, the higher (0 signifies no unsuitable prediction and 1 signifies all of the prediction is unsuitable).
from sklearn.metrics import hamming_loss
print('Hamming Loss: ', spherical(hamming_loss(y_test, prediction),2))
Hamming Loss: 0.13
Our Multilabel Classifier Hamming Loss mannequin is 0.13, which signifies that our mannequin would have a unsuitable prediction 13% of the time independently. This implies every label prediction is perhaps unsuitable 13% of the time.
Multilabel Classification is a machine-learning activity the place the output could possibly be no label or all of the attainable labels given the enter knowledge. It’s totally different from binary or multiclass classification, the place the label output is mutually unique.
Utilizing Scikit-Study MultiOutputClassifier, we may develop Multilabel Classifier the place we practice a classifier to every label. For the mannequin analysis, it’s higher to make use of Hamming Loss metric because the Accuracy rating won’t give the entire image appropriately.
Cornellius Yudha Wijaya is a knowledge science assistant supervisor and knowledge author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Information suggestions through social media and writing media.