

{kind=link}
Knowledge could also be considered as having a construction in varied areas that explains how its elements match collectively to type a higher entire. Relying on the exercise, this construction is often latent and adjustments. Contemplate Determine 1 for illustrations of distinct buildings in pure language. Collectively, the phrases make up a sequence. There’s a part-of-speech tag utilized to every phrase in a sequence. These tags are interconnected, producing the red-hued linear chain. By segmenting the sentence, which is depicted with bubbles, the phrases within the sentence could also be put collectively into tiny, disjointed, contiguous clusters. A extra thorough examination of language would reveal that teams could also be made recursively, making a syntactic tree construction. Buildings can join two languages as nicely.
An alignment, as an example, in the identical image can hyperlink a Japanese translation to an English supply. These grammatical constructs are common. In biology, comparable buildings may be discovered. Tree-based fashions of RNA seize the hierarchical side of the protein folding course of, whereas monotone alignment is used to match the nucleotides in RNA sequences. Genomic information can also be cut up into contiguous teams. Most present deep-learning fashions make no specific try to signify the intermediate construction and as a substitute search to foretell output variables straight from the enter. These fashions may gain advantage from specific modeling of construction in a number of methods. Utilizing the suitable inductive biases might facilitate improved generalization. This might improve downstream efficiency along with pattern effectivity.

Express construction modeling can incorporate a problem-specific set of restrictions or strategies. The judgments made by the mannequin are additionally extra simply comprehensible due to the discrete construction. Lastly, there are events when the construction is the results of studying itself. As an illustration, they might remember that the information is defined by a hidden construction of a sure form, however they should know extra about it. For modeling sequences, auto-regressive fashions are the predominant method. In some conditions, non-sequential buildings may be linearized and proxied by a sequential construction. These fashions are robust as a result of they don’t depend on unbiased assumptions and may be skilled utilizing a lot information. Whereas figuring out the best construction or marginalizing over hidden variables are widespread inference points, sampling from auto-regressive fashions is commonly not tractable.
Utilizing auto-regressive fashions in large-scale fashions is difficult as a result of they demand biassed or high-variance approximations, that are steadily computationally expensive. Fashions over issue graphs that factorize the identical method because the goal construction are a substitute for auto-regressive fashions. These fashions can exactly and effectively calculate all attention-grabbing inference points by using specialised strategies. Though every construction requires a singular technique, every inference job doesn’t require a specialised algorithm (argmax, sampling, marginals, entropy, and many others.). To extract a number of numbers from only one perform for every construction sort, SynJax employs automated differentiation, as they shall exhibit later.
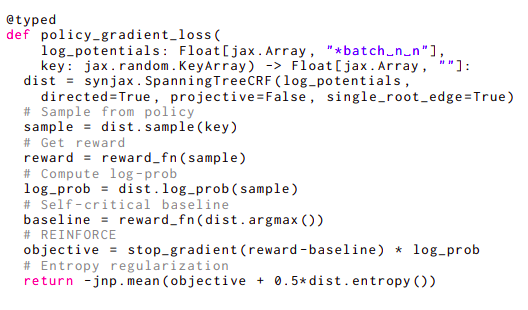
The dearth of sensible libraries that might provide accelerator-friendly implementations of construction elements has slowed analysis into structured distributions for deep understanding, particularly since these elements rely upon algorithms that steadily don’t map straight onto obtainable deep studying primitives, not like Transformer fashions. Researchers from Google Deepmind provide simple-to-use structural primitives that mix inside the JAX machine studying framework, serving to SynJax resolve the problem. Contemplate the instance in Determine 2 to exhibit how easy SynJax is to make use of. This code implements a coverage gradient loss that necessitates computing a number of parameters, together with sampling, argmax, entropy, and log likelihood, every of which requires a separate method.
The construction is a nonprojective directed spanning tree with a single root edge restriction on this code line. Because of this, SynJax will make use of dist.pattern() Wilson’s sampling method for single-root timber, dist.entropy (), and Tarjan’s most spanning tree algorithm for single-root edge timber. Single-root edge timber can use the Matrix-Tree Theorem. Just one flag must be modified for SynJax to make use of solely completely different algorithms which can be appropriate for that construction—Kuhlmann’s algorithm for argmax and varied iterations of Eisner’s algorithm for different portions—in the event that they solely wish to barely alter the kind of timber by mandating that the timber adhere to the projectivity constraint as customers. As a result of SynJax takes care of every little thing associated to such algorithms, the person could think about the modeling side of their problem with out implementing them and even understanding how they work.
Take a look at the Paper and Github. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t neglect to hitch our 28k+ ML SubReddit, 40k+ Fb Neighborhood, Discord Channel, and Electronic mail E-newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Know-how(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is keen about constructing options round it. He loves to attach with folks and collaborate on attention-grabbing initiatives.