
{kind=link}
Brief for Reasoning and Performing, this paper introduces a brand new idea that improves the efficiency of LLMs and likewise offers us with extra explainability and interpretability.
The objective of AGI might be one of the crucial necessary targets for human civilization to attain. Think about creating synthetic intelligence that would generalize to many issues. There are lots of interpretations of what an AGI is, and when do we are saying that we now have achieved it?
Probably the most promising technique for AGI within the final many years was the reinforcement studying path, extra particularly what DeepMind was capable of obtain arduous duties, AlphaGo, AlphaStar and so many breakthroughs…
Nonetheless, ReAct outperforms imitation and reinforcement studying strategies by an absolute success charge of 34% and 10% respectively, whereas being prompted with just one or two in-context examples.
With this sort of consequence (in fact, offered there is no such thing as a knowledge leakage and we will belief the analysis strategies offered within the paper), we will not ignore LLMs’ potential to motive and divide complicated duties into logical steps.
This paper begins with the concept that LLMs up to now are spectacular in language understanding, they’ve been used to generate CoT (Chain of thought) to resolve some issues, and so they have been additionally used for appearing and plan technology.
Though these two have been studied individually, the paper goals to mix each reasoning and appearing in an interleaved method to reinforce LLM’s efficiency.
The rationale behind this concept is that if you concentrate on the way you, as a human, behave to be able to execute some activity.
Step one is that you simply’ll use “interior Speech” otherwise you’ll write down or talk with your self in some way, saying “How do I execute activity X? to do activity X I must first do step 1 after which do step2 and so forth”
Extra concretely, in the event you have been to prepare dinner up a dish within the kitchen, you can ReAct one thing like this:
“Now that all the pieces is reduce, I ought to warmth up the pot of water”), to deal with exceptions or modify the plan in keeping with the state of affairs (“I don’t have salt, so let me use soy sauce and pepper as a substitute”), and to comprehend when exterior info is required (“how do I put together dough? Let me search on the Web”).
You too can act (open a cookbook to learn the recipe, open the fridge, test elements) to assist the reasoning and reply questions (“What dish can I make proper now?”).
This mix of each reasoning and appearing is what makes people study and obtain duties even beneath beforehand unseen circumstances or when confronted with info uncertainties.
Earlier works demonstrated the capabilities of LLMs to motive, for instance, Chain of Thought Prompting demonstrated that the mannequin might provide you with plans to reply questions in arithmetic, frequent sense, and symbolic reasoning.
Nonetheless, the mannequin right here remains to be a “static black field” as a result of it makes use of its inner language illustration to reply these questions, and this illustration could not all the time be correct or up-to-date which ends up in reality hallucination (coming with details from its personal creativeness) or error propagation (one error within the chain of ideas propagates to a mistaken reply).
With out the power to take some form of motion and replace its information, the mannequin is restricted.
There have additionally been research that employed LLMs to do actions primarily based on language, these research often absorb multimodal inputs (audio, textual content, and pictures), convert them to textual content, use the mannequin to generate in-domain actions, after which use a controller to do these actions.
With out the power to plan some steps and motive about what to do, the mannequin will merely output the mistaken actions.
The proposal of this paper is to mix each strategies talked about above. ReAct prompts LLMs to generate each verbal reasoning traces and actions pertaining to a activity in an interleaved method, which permits the mannequin to carry out dynamic reasoning to create, keep, and modify high-level plans for appearing (motive to behave), whereas additionally interacting with exterior environments (e.g., Wikipedia) to include extra info into reasoning (act to motive).
That is proven within the determine beneath:
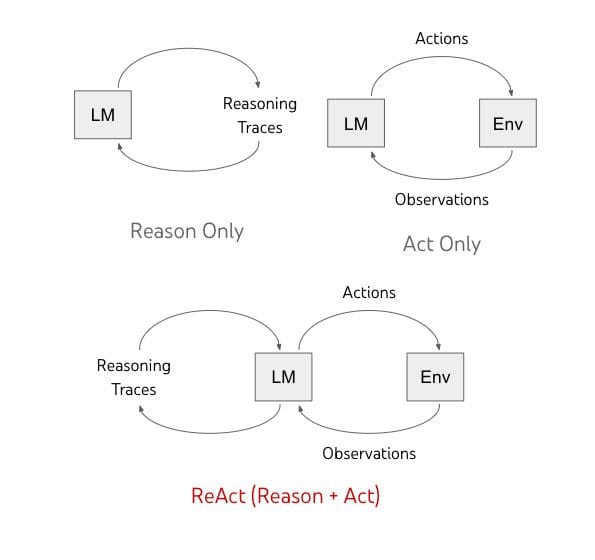
Distinction between Purpose, Act and ReAct (Photograph taken from the paper)
So to be able to make the reasoning prompting higher, they design an motion house, which suggests three actions that the mannequin is allowed to make use of when answering questions.
That is completed by means of a Wikipedia API that gives the next:
- search[entity]: returns the primary 5 sentences from the corresponding entity wiki web page if it exists, or else suggests top-5 related entities from the Wikipedia search engine
- lookup[string], which might return the subsequent sentence within the web page containing the string, simulating Ctrl+F performance on the browser
- end[answer], which might end the present activity with the reply
One thing that isn’t common right here is that there are far more highly effective info retrieval instruments than those talked about above.
The objective behind that is to simulate human habits and the way a human would work together with Wikipedia and motive to search out a solution.
Along with the offered instruments, we have to correctly immediate the LLM, to offer reasoning and correctly chain actions.
To this finish, they use a mixture of ideas that decompose a query like (“I want to look x, discover y, then discover z”), extract info from Wikipedia observations (“x was began in 1844”, “The paragraph doesn’t inform x”), carry out frequent sense (“x is just not y, so z should as a substitute be…”) or arithmetic reasoning (“1844 < 1989”), information search reformulation (“possibly I can search/lookup x as a substitute”), and synthesize the ultimate reply (“…so the reply is x”)
Lastly, the outcomes look one thing like this:

How ReAct works and results in higher outcomes (Photograph taken from the paper)
The datasets chosen for the analysis are the next:
HotPotQA: is a question-answering dataset that requires reasoning over one or two Wikipedia pages.
FEVER: a reality verification benchmark the place every declare is annotated SUPPORTS, REFUTES, or NOT ENOUGH INFO, primarily based on whether or not there exists a Wikipedia passage to confirm the declare.
ALFWorld: Textual content Based mostly sport that features 6 sorts of duties that the agent must carry out to attain a high-level objective.
An instance can be “look at paper beneath desk lamp” by navigating and interacting with a simulated family by way of textual content actions (e.g. go to espresso desk 1, take paper 2, use desk lamp 1)
WebShop: a web based procuring web site surroundings with 1.18M real-world merchandise and 12k human directions with way more selection and complexity.
It requires an agent to buy a product primarily based on person directions. For instance “I’m searching for a nightstand with drawers. It ought to have a nickel end, and be priced decrease than $140”, the agent wants to attain this by means of internet interactions.
So the outcomes present that ReAct all the time outperforms Act, which fits to indicate that the reasoning half is extraordinarily necessary to reinforce the actions.
Alternatively, ReAct outperforms CoT on Fever (60.9 vs. 56.3) and barely lags behind CoT on HotpotQA (27.4 vs. 29.4). So for the FEVER dataset, appearing to get up to date information is exhibiting to provide the wanted enhance to make the fitting SUPPORT or REFUTE resolution.
When evaluating CoT vs ReAct on HotpotQA and why the efficiency is comparable, these are the important thing observations discovered:
- Hallucination is a significant issue for CoT, so with no approach to replace its information, CoT has to think about and hallucinate issues, which is an enormous hurdle.
- Whereas interleaving reasoning, motion, and remark steps enhance ReAct’s groundedness and trustworthiness, such a structural constraint additionally reduces its flexibility in formulating reasoning steps. ReAct could drive the LLM to do actions when simply doing CoT is usually sufficient.
- For ReAct, efficiently retrieving informative information by way of search is crucial. If search retrieves mistaken info than routinely any reasoning primarily based that false info is mistaken, so getting the fitting info is crutial.

ReAct and CoT outcomes on completely different datasets (Photograph taken from the paper)
I hope this text helped you to grasp this paper. You possibly can test it out right here https://arxiv.org/pdf/2210.03629.pdf
Implementations of ReAct exist already right here and right here.
Mohamed Aziz Belaweid is a Machine Studying / Information Engineer at SoundCloud. He’s fascinated about each Analysis and Engineering. He like studying papers and really bringing their innovation to life. He have labored on Language mannequin coaching from scratch to particular domains. Extracting info from textual content utilizing Named Entity Recognition, Multi Modal search programs, Picture classification and detection. Additionally labored in operations facet comparable to mannequin deployment, reproducibility, scaling and inference.
Unique. Reposted with permission.