

{kind=link}
Synthetic Intelligence has been witnessing monumental progress in bridging the hole between the capabilities of people and machines. Researchers and fans alike, work on quite a few points of the sphere to make superb issues occur. One in every of many such areas is the area of Pc Imaginative and prescient.
The agenda for this subject is to allow machines to view the world as people do, understand it in an analogous method, and even use the data for a large number of duties akin to Picture & Video recognition, Picture Evaluation & Classification, Media Recreation, Suggestion Methods, Pure Language Processing, and many others. The developments in Pc Imaginative and prescient with Deep Studying have been constructed and perfected with time, primarily over one explicit algorithm — a Convolutional Neural Community.
Introduction

A CNN sequence to categorise handwritten digits
A Convolutional Neural Community (ConvNet/CNN) is a Deep Studying algorithm that may soak up an enter picture, assign significance (learnable weights and biases) to numerous points/objects within the picture, and have the ability to differentiate one from the opposite. The pre-processing required in a ConvNet is way decrease as in comparison with different classification algorithms. Whereas in primitive strategies filters are hand-engineered, with sufficient coaching, ConvNets have the flexibility to study these filters/traits.
The structure of a ConvNet is analogous to that of the connectivity sample of Neurons within the Human Mind and was impressed by the group of the Visible Cortex. Particular person neurons reply to stimuli solely in a restricted area of the visible subject referred to as the Receptive Area. A group of such fields overlap to cowl your complete visible space.
Why ConvNets over Feed-Ahead Neural Nets?
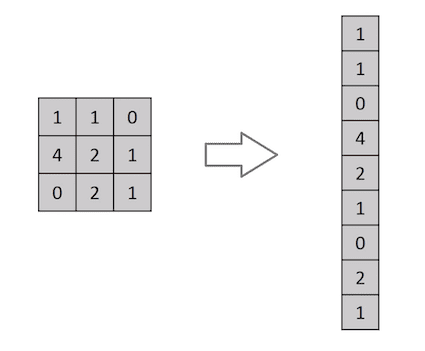
Flattening of a 3×3 picture matrix right into a 9×1 vector
A picture is nothing however a matrix of pixel values, proper? So why not simply flatten the picture (e.g. 3×3 picture matrix right into a 9×1 vector) and feed it to a Multi-Degree Perceptron for classification functions? Uh.. not likely.
In circumstances of extraordinarily primary binary pictures, the tactic may present a median precision rating whereas performing prediction of courses however would have little to no accuracy on the subject of advanced pictures having pixel dependencies all through.
A ConvNet is ready to efficiently seize the Spatial and Temporal dependencies in a picture by means of the appliance of related filters. The structure performs a greater becoming to the picture dataset as a result of discount within the variety of parameters concerned and the reusability of weights. In different phrases, the community will be skilled to know the sophistication of the picture higher.
Enter Picture
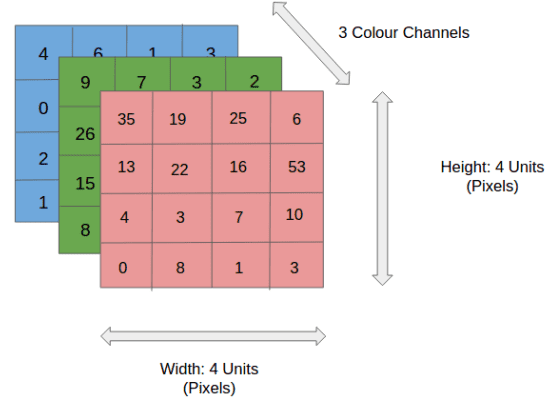
4x4x3 RGB Picture
Within the determine, we have now an RGB picture that has been separated by its three shade planes — Purple, Inexperienced, and Blue. There are a variety of such shade areas wherein pictures exist — Grayscale, RGB, HSV, CMYK, and many others.
You may think about how computationally intensive issues would get as soon as the photographs attain dimensions, say 8K (7680×4320). The position of ConvNet is to cut back the photographs right into a type that’s simpler to course of, with out shedding options which can be crucial for getting a superb prediction. That is vital after we are to design an structure that’s not solely good at studying options but in addition scalable to huge datasets.
Convolution Layer — The Kernel

Convoluting a 5x5x1 picture with a 3x3x1 kernel to get a 3x3x1 convolved characteristic
Picture Dimensions = 5 (Top) x 5 (Breadth) x 1 (Variety of channels, eg. RGB)
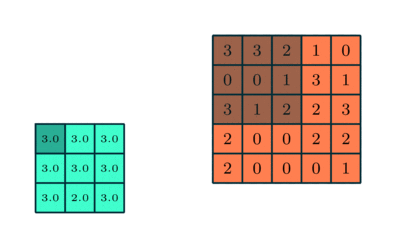
Within the above demonstration, the inexperienced part resembles our 5x5x1 enter picture, I. The factor concerned within the convolution operation within the first a part of a Convolutional Layer known as the Kernel/Filter, Ok, represented in shade yellow. We’ve chosen Ok as a 3x3x1 matrix.
Kernel/Filter, Ok =
1 0 1
0 1 0
1 0 1
The Kernel shifts 9 instances due to Stride Size = 1 (Non-Strided), each time performing an elementwise multiplication operation (Hadamard Product) between Ok and the portion P of the picture over which the kernel is hovering.
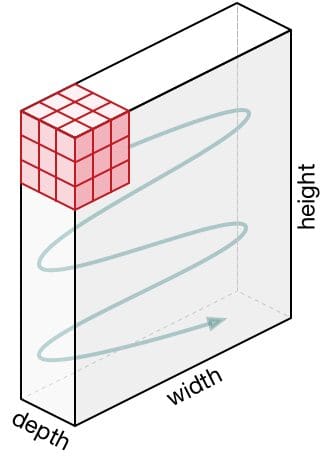
Motion of the Kernel
The filter strikes to the best with a sure Stride Worth until it parses the whole width. Shifting on, it hops all the way down to the start (left) of the picture with the identical Stride Worth and repeats the method till your complete picture is traversed.
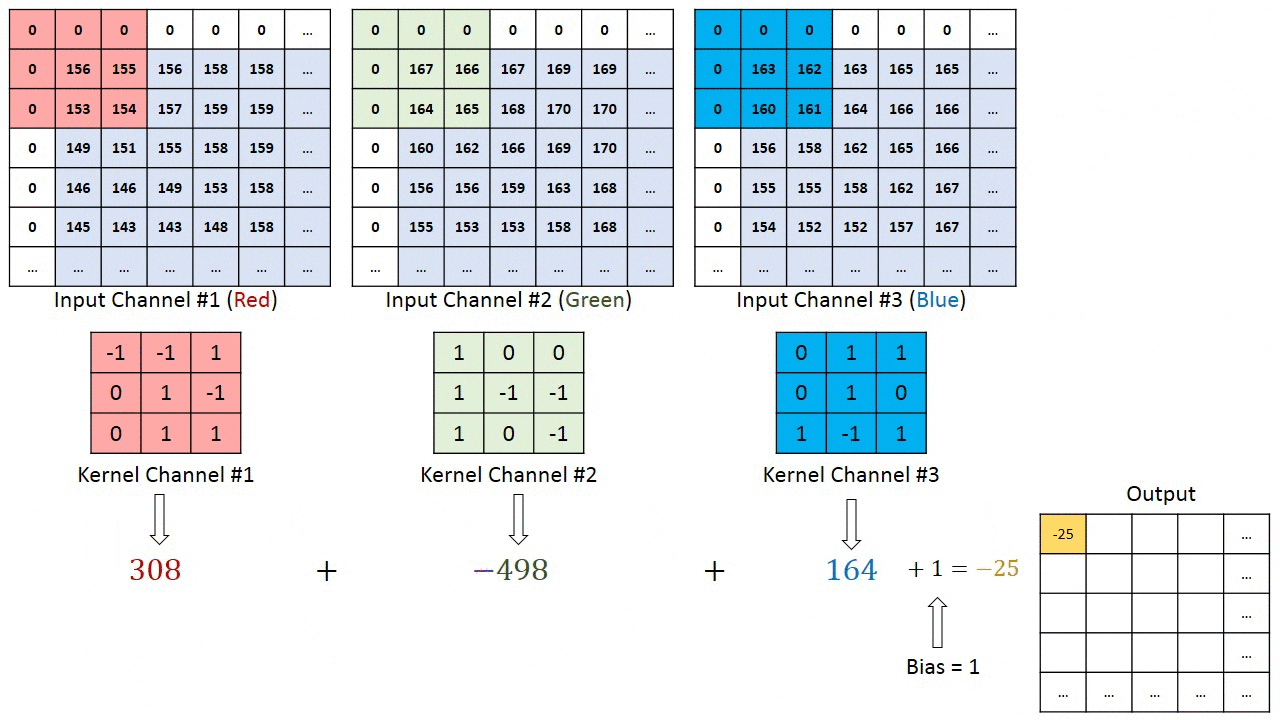
Convolution operation on a MxNx3 picture matrix with a 3x3x3 Kernel
Within the case of pictures with a number of channels (e.g. RGB), the Kernel has the identical depth as that of the enter picture. Matrix Multiplication is carried out between Kn and In stack ([K1, I1]; [K2, I2]; [K3, I3]) and all the outcomes are summed with the bias to offer us a squashed one-depth channel Convoluted Characteristic Output.

Convolution Operation with Stride Size = 2
The target of the Convolution Operation is to extract the high-level options akin to edges, from the enter picture. ConvNets needn’t be restricted to just one Convolutional Layer. Conventionally, the primary ConvLayer is accountable for capturing the Low-Degree options akin to edges, shade, gradient orientation, and many others. With added layers, the structure adapts to the Excessive-Degree options as nicely, giving us a community that has a healthful understanding of pictures within the dataset, much like how we might.
There are two forms of outcomes to the operation — one wherein the convolved characteristic is lowered in dimensionality as in comparison with the enter, and the opposite wherein the dimensionality is both elevated or stays the identical. That is performed by making use of Legitimate Padding within the case of the previous, or Similar Padding within the case of the latter.
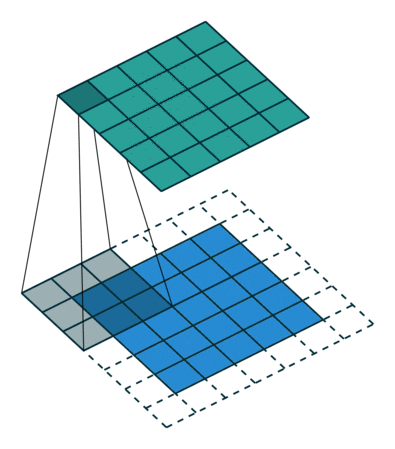
After we increase the 5x5x1 picture right into a 6x6x1 picture after which apply the 3x3x1 kernel over it, we discover that the convolved matrix seems to be of dimensions 5x5x1. Therefore the identify — Similar Padding.
Then again, if we carry out the identical operation with out padding, we’re introduced with a matrix that has dimensions of the Kernel (3x3x1) itself — Legitimate Padding.
The next repository homes many such GIFs which might allow you to get a greater understanding of how Padding and Stride Size work collectively to attain outcomes related to our wants.
[vdumoulin/conv_arithmetic
A technical report on convolution arithmetic in the context of deep learning – vdumoulin/conv_arithmeticgithub.com](https://github.com/vdumoulin/conv_arithmetic)
Pooling Layer
Much like the Convolutional Layer, the Pooling layer is accountable for lowering the spatial measurement of the Convolved Characteristic. That is to lower the computational energy required to course of the info by means of dimensionality discount. Moreover, it’s helpful for extracting dominant options that are rotational and positional invariant, thus sustaining the method of successfully coaching the mannequin.
There are two forms of Pooling: Max Pooling and Common Pooling. Max Pooling returns the most worth from the portion of the picture lined by the Kernel. Then again, Common Pooling returns the common of all of the values from the portion of the picture lined by the Kernel.
Max Pooling additionally performs as a Noise Suppressant. It discards the noisy activations altogether and likewise performs de-noising together with dimensionality discount. Then again, Common Pooling merely performs dimensionality discount as a noise-suppressing mechanism. Therefore, we will say that Max Pooling performs so much higher than Common Pooling.
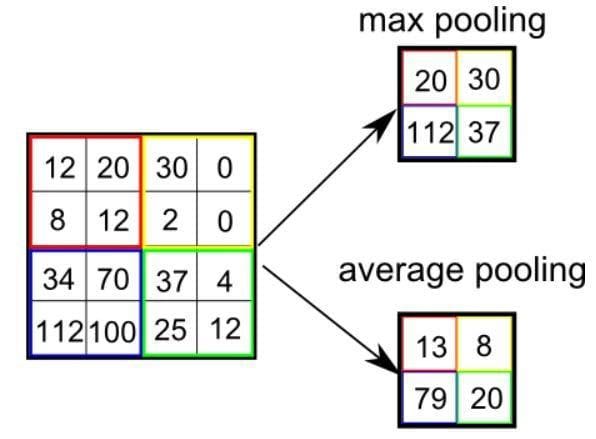
Forms of Pooling
The Convolutional Layer and the Pooling Layer, collectively type the i-th layer of a Convolutional Neural Community. Relying on the complexities within the pictures, the variety of such layers could also be elevated for capturing low-level particulars even additional, however at the price of extra computational energy.
After going by means of the above course of, we have now efficiently enabled the mannequin to know the options. Shifting on, we’re going to flatten the ultimate output and feed it to a daily Neural Community for classification functions.
Classification — Totally Related Layer (FC Layer)
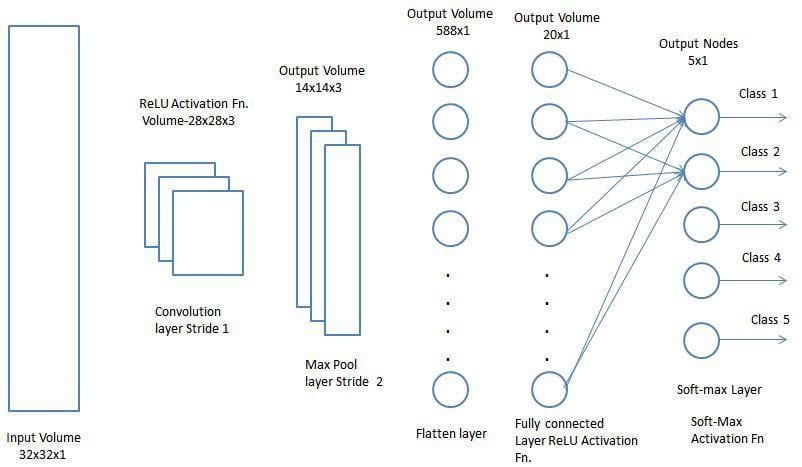
Including a Totally-Related layer is a (normally) low-cost approach of studying non-linear combos of the high-level options as represented by the output of the convolutional layer. The Totally-Related layer is studying a presumably non-linear perform in that area.
Now that we have now transformed our enter picture into an acceptable type for our Multi-Degree Perceptron, we will flatten the picture right into a column vector. The flattened output is fed to a feed-forward neural community and backpropagation is utilized to each iteration of coaching. Over a sequence of epochs, the mannequin is ready to distinguish between dominating and sure low-level options in pictures and classify them utilizing the Softmax Classification method.
There are numerous architectures of CNNs obtainable which have been key in constructing algorithms which energy and shall energy AI as an entire within the foreseeable future. A few of them have been listed beneath:
- LeNet
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
Sumit Saha is an information scientist and machine studying engineer at the moment engaged on constructing AI-driven merchandise. He’s passionate concerning the purposes of AI for social good, particularly within the area of drugs and healthcare. Often I do some technical running a blog too.
Unique. Reposted with permission.