

{kind=link}
At its core, LangChain is an modern framework tailor-made for crafting purposes that leverage the capabilities of language fashions. It is a toolkit designed for builders to create purposes which can be context-aware and able to refined reasoning.
This implies LangChain purposes can perceive the context, reminiscent of immediate directions or content material grounding responses and use language fashions for complicated reasoning duties, like deciding learn how to reply or what actions to take. LangChain represents a unified method to growing clever purposes, simplifying the journey from idea to execution with its various parts.
Understanding LangChain
LangChain is way more than only a framework; it is a full-fledged ecosystem comprising a number of integral components.
- Firstly, there are the LangChain Libraries, out there in each Python and JavaScript. These libraries are the spine of LangChain, providing interfaces and integrations for numerous parts. They supply a primary runtime for combining these parts into cohesive chains and brokers, together with ready-made implementations for speedy use.
- Subsequent, we now have LangChain Templates. These are a group of deployable reference architectures tailor-made for a wide selection of duties. Whether or not you are constructing a chatbot or a fancy analytical instrument, these templates supply a strong start line.
- LangServe steps in as a flexible library for deploying LangChain chains as REST APIs. This instrument is important for turning your LangChain tasks into accessible and scalable net companies.
- Lastly, LangSmith serves as a developer platform. It is designed to debug, check, consider, and monitor chains constructed on any LLM framework. The seamless integration with LangChain makes it an indispensable instrument for builders aiming to refine and excellent their purposes.
Collectively, these parts empower you to develop, productionize, and deploy purposes with ease. With LangChain, you begin by writing your purposes utilizing the libraries, referencing templates for steerage. LangSmith then helps you in inspecting, testing, and monitoring your chains, making certain that your purposes are always enhancing and prepared for deployment. Lastly, with LangServe, you may simply remodel any chain into an API, making deployment a breeze.
Within the subsequent sections, we’ll delve deeper into learn how to arrange LangChain and start your journey in creating clever, language model-powered purposes.
Automate guide duties and workflows with our AI-driven workflow builder, designed by Nanonets for you and your groups.
Set up and Setup
Are you able to dive into the world of LangChain? Setting it up is easy, and this information will stroll you thru the method step-by-step.
Step one in your LangChain journey is to put in it. You are able to do this simply utilizing pip or conda. Run the next command in your terminal:
pip set up langchain
For many who desire the most recent options and are snug with a bit extra journey, you may set up LangChain straight from the supply. Clone the repository and navigate to the langchain/libs/langchain listing. Then, run:
pip set up -e .
For experimental options, contemplate putting in langchain-experimental. It is a package deal that incorporates cutting-edge code and is meant for analysis and experimental functions. Set up it utilizing:
pip set up langchain-experimental
LangChain CLI is a helpful instrument for working with LangChain templates and LangServe tasks. To put in the LangChain CLI, use:
pip set up langchain-cli
LangServe is important for deploying your LangChain chains as a REST API. It will get put in alongside the LangChain CLI.
LangChain typically requires integrations with mannequin suppliers, knowledge shops, APIs, and many others. For this instance, we’ll use OpenAI’s mannequin APIs. Set up the OpenAI Python package deal utilizing:
pip set up openai
To entry the API, set your OpenAI API key as an surroundings variable:
export OPENAI_API_KEY="your_api_key"
Alternatively, go the important thing straight in your python surroundings:
import os
os.environ['OPENAI_API_KEY'] = 'your_api_key'
LangChain permits for the creation of language mannequin purposes by way of modules. These modules can both stand alone or be composed for complicated use circumstances. These modules are –
- Mannequin I/O: Facilitates interplay with numerous language fashions, dealing with their inputs and outputs effectively.
- Retrieval: Permits entry to and interplay with application-specific knowledge, essential for dynamic knowledge utilization.
- Brokers: Empower purposes to pick applicable instruments based mostly on high-level directives, enhancing decision-making capabilities.
- Chains: Gives pre-defined, reusable compositions that function constructing blocks for software growth.
- Reminiscence: Maintains software state throughout a number of chain executions, important for context-aware interactions.
Every module targets particular growth wants, making LangChain a complete toolkit for creating superior language mannequin purposes.
Together with the above parts, we even have LangChain Expression Language (LCEL), which is a declarative approach to simply compose modules collectively, and this allows the chaining of parts utilizing a common Runnable interface.
LCEL appears one thing like this –
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser
# Instance chain
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
Now that we now have lined the fundamentals, we’ll proceed on to:
- Dig deeper into every Langchain module intimately.
- Learn to use LangChain Expression Language.
- Discover frequent use circumstances and implement them.
- Deploy an end-to-end software with LangServe.
- Take a look at LangSmith for debugging, testing, and monitoring.
Let’s get began!
Module I : Mannequin I/O
In LangChain, the core ingredient of any software revolves across the language mannequin. This module offers the important constructing blocks to interface successfully with any language mannequin, making certain seamless integration and communication.
Key Elements of Mannequin I/O
- LLMs and Chat Fashions (used interchangeably):
- LLMs:
- Definition: Pure textual content completion fashions.
- Enter/Output: Take a textual content string as enter and return a textual content string as output.
- Chat Fashions
- LLMs:
- Definition: Fashions that use a language mannequin as a base however differ in enter and output codecs.
- Enter/Output: Settle for a listing of chat messages as enter and return a Chat Message.
- Prompts: Templatize, dynamically choose, and handle mannequin inputs. Permits for the creation of versatile and context-specific prompts that information the language mannequin’s responses.
- Output Parsers: Extract and format info from mannequin outputs. Helpful for changing the uncooked output of language fashions into structured knowledge or particular codecs wanted by the appliance.
LLMs
LangChain’s integration with Massive Language Fashions (LLMs) like OpenAI, Cohere, and Hugging Face is a elementary facet of its performance. LangChain itself doesn’t host LLMs however affords a uniform interface to work together with numerous LLMs.
This part offers an outline of utilizing the OpenAI LLM wrapper in LangChain, relevant to different LLM sorts as nicely. Now we have already put in this within the “Getting Began” part. Allow us to initialize the LLM.
from langchain.llms import OpenAI
llm = OpenAI()
- LLMs implement the Runnable interface, the fundamental constructing block of the LangChain Expression Language (LCEL). This implies they assist
invoke,ainvoke,stream,astream,batch,abatch,astream_logcalls. - LLMs settle for strings as inputs, or objects which could be coerced to string prompts, together with
Checklist[BaseMessage]andPromptValue. (extra on these later)
Allow us to have a look at some examples.
response = llm.invoke("Checklist the seven wonders of the world.")
print(response)

You’ll be able to alternatively name the stream methodology to stream the textual content response.
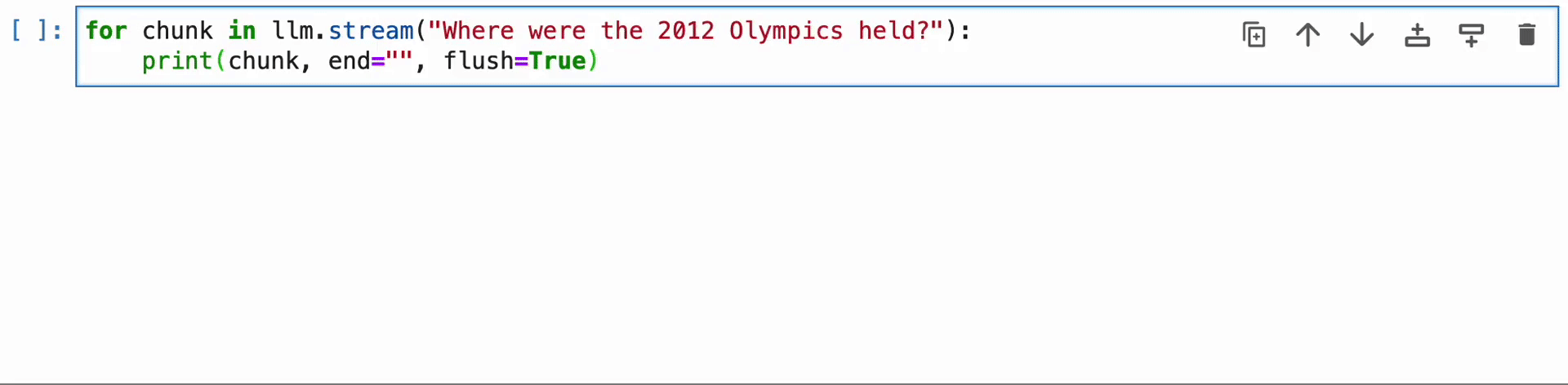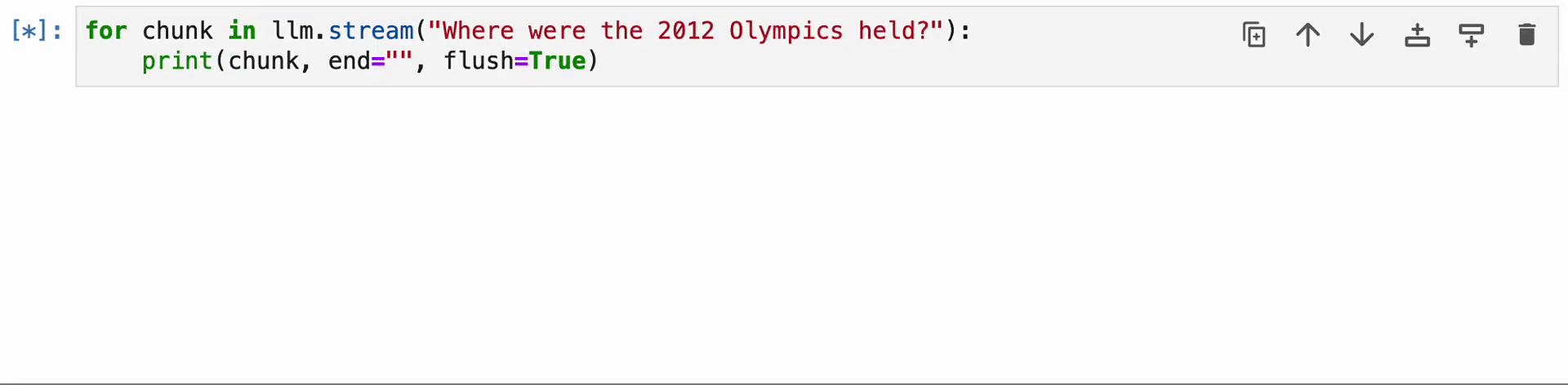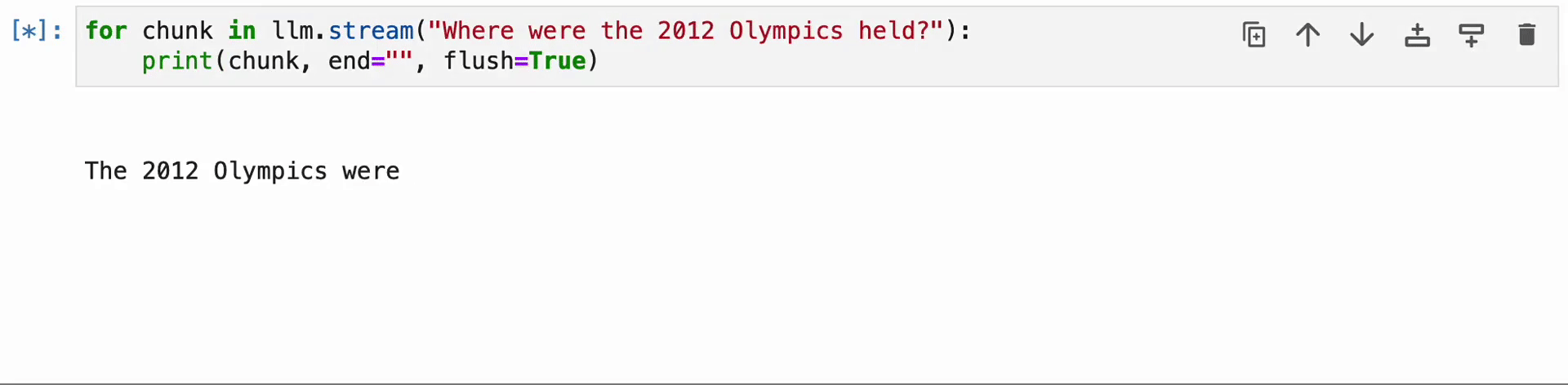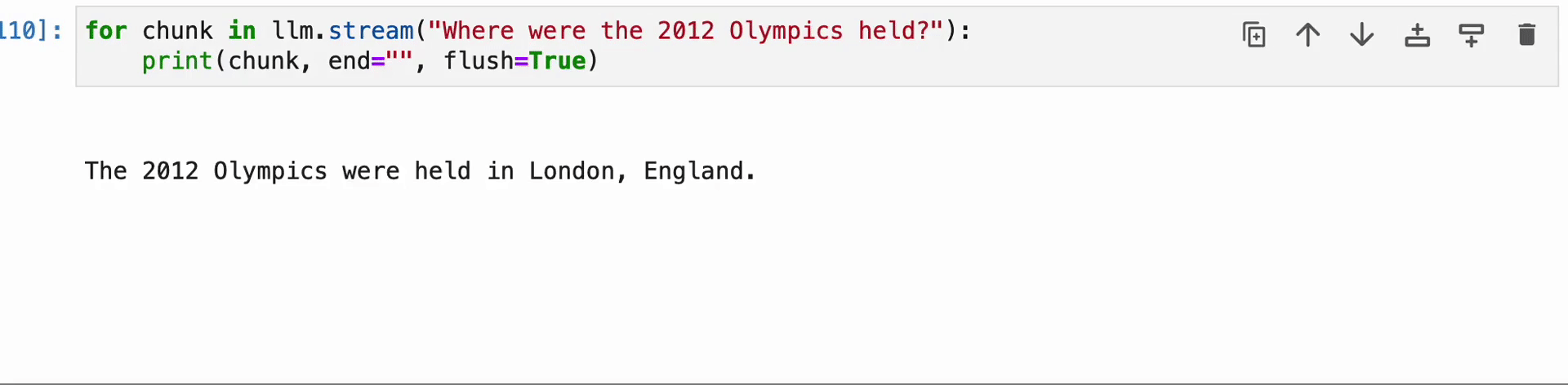
for chunk in llm.stream("The place had been the 2012 Olympics held?"):
print(chunk, finish="", flush=True)
Chat Fashions
LangChain’s integration with chat fashions, a specialised variation of language fashions, is important for creating interactive chat purposes. Whereas they make the most of language fashions internally, chat fashions current a definite interface centered round chat messages as inputs and outputs. This part offers an in depth overview of utilizing OpenAI’s chat mannequin in LangChain.
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
Chat fashions in LangChain work with completely different message sorts reminiscent of AIMessage, HumanMessage, SystemMessage, FunctionMessage, and ChatMessage (with an arbitrary function parameter). Typically, HumanMessage, AIMessage, and SystemMessage are essentially the most often used.
Chat fashions primarily settle for Checklist[BaseMessage] as inputs. Strings could be transformed to HumanMessage, and PromptValue can be supported.
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="You are Micheal Jordan."),
HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
response = chat.invoke(messages)
print(response.content material)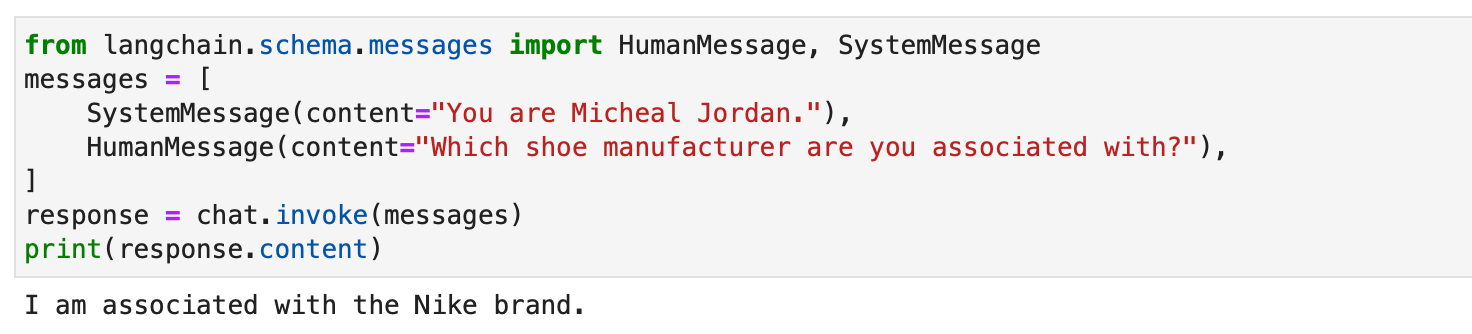
Prompts
Prompts are important in guiding language fashions to generate related and coherent outputs. They’ll vary from easy directions to complicated few-shot examples. In LangChain, dealing with prompts could be a very streamlined course of, due to a number of devoted courses and features.
LangChain’s PromptTemplate class is a flexible instrument for creating string prompts. It makes use of Python’s str.format syntax, permitting for dynamic immediate technology. You’ll be able to outline a template with placeholders and fill them with particular values as wanted.
from langchain.prompts import PromptTemplate
# Easy immediate with placeholders
prompt_template = PromptTemplate.from_template(
"Inform me a {adjective} joke about {content material}."
)
# Filling placeholders to create a immediate
filled_prompt = prompt_template.format(adjective="humorous", content material="robots")
print(filled_prompt)For chat fashions, prompts are extra structured, involving messages with particular roles. LangChain affords ChatPromptTemplate for this objective.
from langchain.prompts import ChatPromptTemplate
# Defining a chat immediate with numerous roles
chat_template = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
]
)
# Formatting the chat immediate
formatted_messages = chat_template.format_messages(title="Bob", user_input="What's your title?")
for message in formatted_messages:
print(message)
This method permits for the creation of interactive, partaking chatbots with dynamic responses.
Each PromptTemplate and ChatPromptTemplate combine seamlessly with the LangChain Expression Language (LCEL), enabling them to be a part of bigger, complicated workflows. We’ll talk about extra on this later.
Customized immediate templates are generally important for duties requiring distinctive formatting or particular directions. Making a customized immediate template entails defining enter variables and a customized formatting methodology. This flexibility permits LangChain to cater to a wide selection of application-specific necessities. Learn extra right here.
LangChain additionally helps few-shot prompting, enabling the mannequin to be taught from examples. This characteristic is important for duties requiring contextual understanding or particular patterns. Few-shot immediate templates could be constructed from a set of examples or by using an Instance Selector object. Learn extra right here.
Output Parsers
Output parsers play an important function in Langchain, enabling customers to construction the responses generated by language fashions. On this part, we’ll discover the idea of output parsers and supply code examples utilizing Langchain’s PydanticOutputParser, SimpleJsonOutputParser, CommaSeparatedListOutputParser, DatetimeOutputParser, and XMLOutputParser.
PydanticOutputParser
Langchain offers the PydanticOutputParser for parsing responses into Pydantic knowledge constructions. Under is a step-by-step instance of learn how to use it:
from typing import Checklist
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Subject, validator
# Initialize the language mannequin
mannequin = OpenAI(model_name="text-davinci-003", temperature=0.0)
# Outline your required knowledge construction utilizing Pydantic
class Joke(BaseModel):
setup: str = Subject(description="query to arrange a joke")
punchline: str = Subject(description="reply to resolve the joke")
@validator("setup")
def question_ends_with_question_mark(cls, area):
if area[-1] != "?":
increase ValueError("Badly fashioned query!")
return area
# Arrange a PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Joke)
# Create a immediate with format directions
immediate = PromptTemplate(
template="Reply the person question.n{format_instructions}n{question}n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Outline a question to immediate the language mannequin
question = "Inform me a joke."
# Mix immediate, mannequin, and parser to get structured output
prompt_and_model = immediate | mannequin
output = prompt_and_model.invoke({"question": question})
# Parse the output utilizing the parser
parsed_result = parser.invoke(output)
# The result's a structured object
print(parsed_result)
The output can be:

SimpleJsonOutputParser
Langchain’s SimpleJsonOutputParser is used whenever you wish to parse JSON-like outputs. Here is an instance:
from langchain.output_parsers.json import SimpleJsonOutputParser
# Create a JSON immediate
json_prompt = PromptTemplate.from_template(
"Return a JSON object with `birthdate` and `birthplace` key that solutions the next query: {query}"
)
# Initialize the JSON parser
json_parser = SimpleJsonOutputParser()
# Create a series with the immediate, mannequin, and parser
json_chain = json_prompt | mannequin | json_parser
# Stream by way of the outcomes
result_list = listing(json_chain.stream({"query": "When and the place was Elon Musk born?"}))
# The result's a listing of JSON-like dictionaries
print(result_list)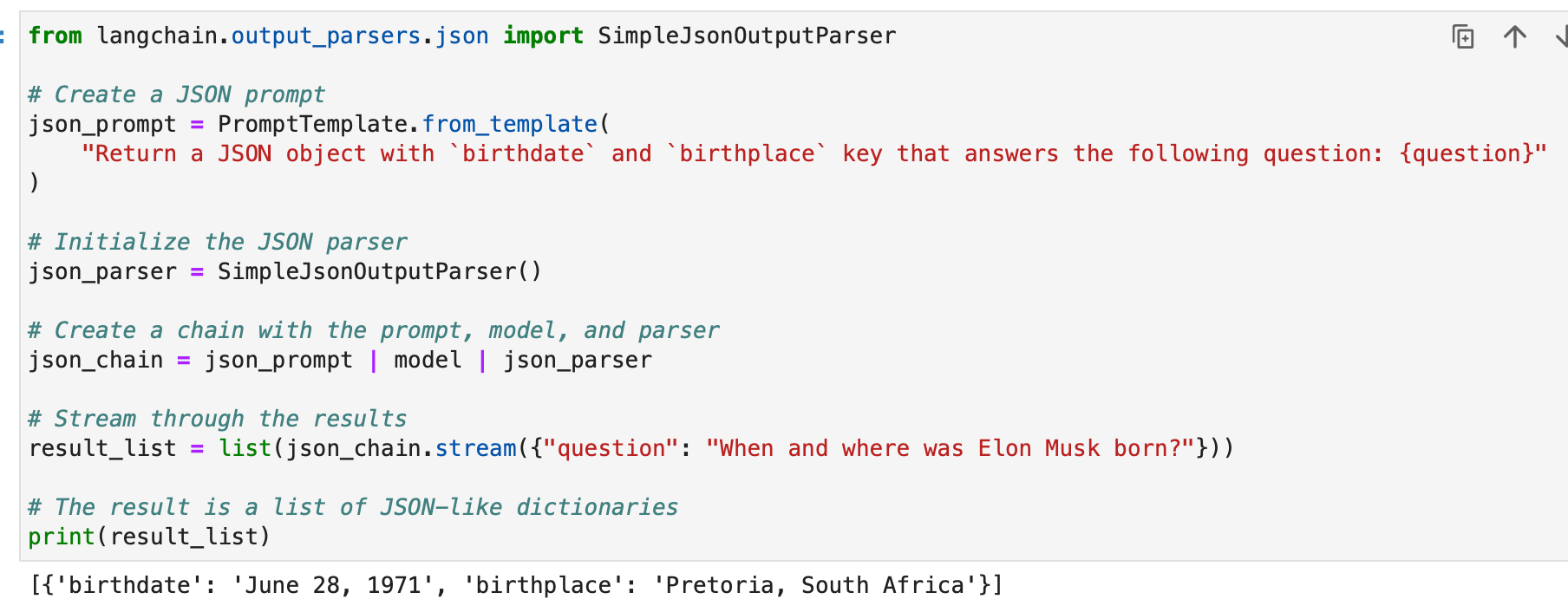
CommaSeparatedListOutputParser
The CommaSeparatedListOutputParser is helpful whenever you wish to extract comma-separated lists from mannequin responses. Here is an instance:
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
# Initialize the parser
output_parser = CommaSeparatedListOutputParser()
# Create format directions
format_instructions = output_parser.get_format_instructions()
# Create a immediate to request a listing
immediate = PromptTemplate(
template="Checklist 5 {topic}.n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions}
)
# Outline a question to immediate the mannequin
question = "English Premier League Groups"
# Generate the output
output = mannequin(immediate.format(topic=question))
# Parse the output utilizing the parser
parsed_result = output_parser.parse(output)
# The result's a listing of things
print(parsed_result)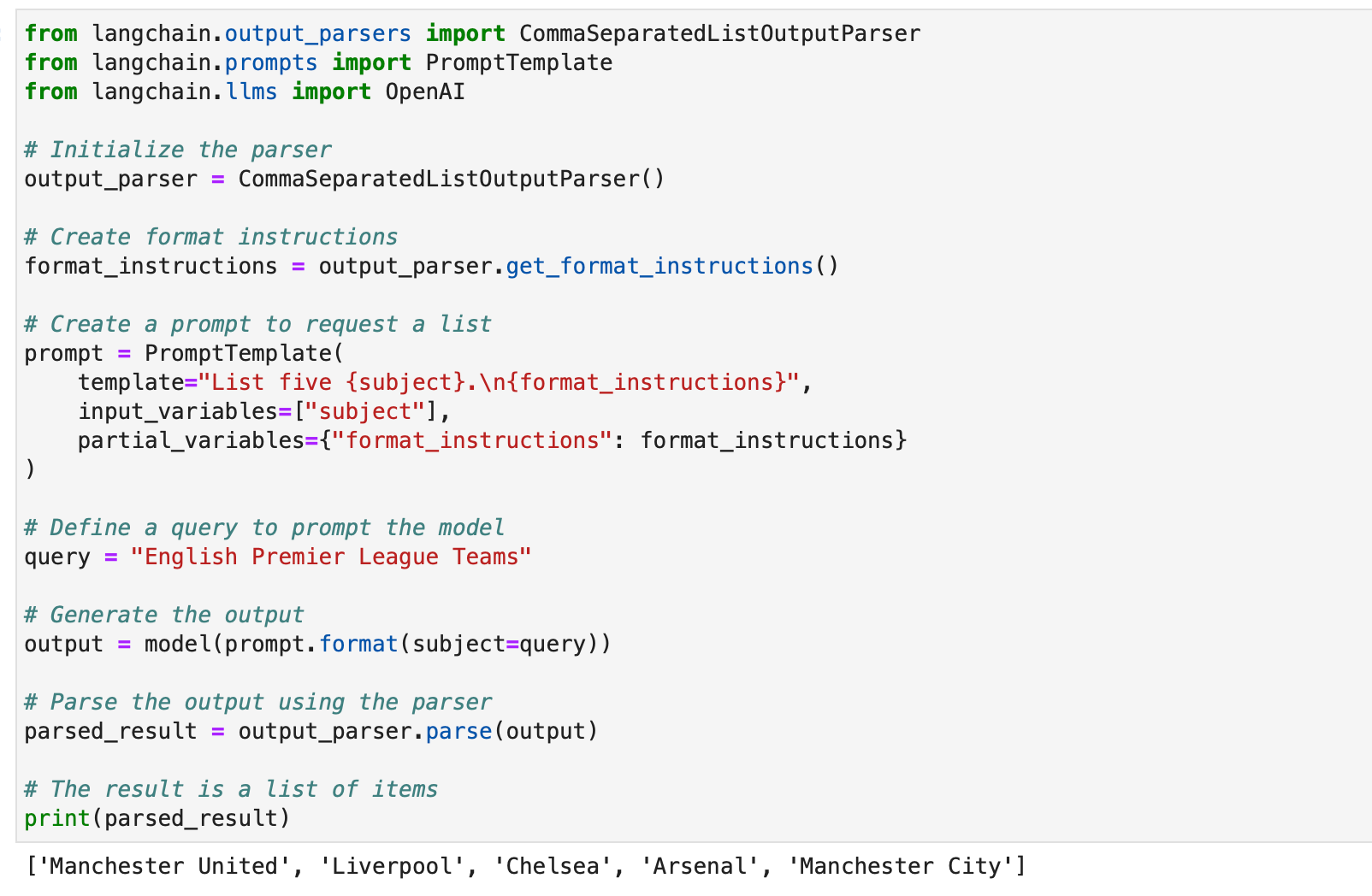
DatetimeOutputParser
Langchain’s DatetimeOutputParser is designed to parse datetime info. Here is learn how to use it:
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI
# Initialize the DatetimeOutputParser
output_parser = DatetimeOutputParser()
# Create a immediate with format directions
template = """
Reply the person's query:
{query}
{format_instructions}
"""
immediate = PromptTemplate.from_template(
template,
partial_variables={"format_instructions": output_parser.get_format_instructions()},
)
# Create a series with the immediate and language mannequin
chain = LLMChain(immediate=immediate, llm=OpenAI())
# Outline a question to immediate the mannequin
question = "when did Neil Armstrong land on the moon by way of GMT?"
# Run the chain
output = chain.run(question)
# Parse the output utilizing the datetime parser
parsed_result = output_parser.parse(output)
# The result's a datetime object
print(parsed_result)
These examples showcase how Langchain’s output parsers can be utilized to construction numerous varieties of mannequin responses, making them appropriate for various purposes and codecs. Output parsers are a precious instrument for enhancing the usability and interpretability of language mannequin outputs in Langchain.
Automate guide duties and workflows with our AI-driven workflow builder, designed by Nanonets for you and your groups.
Module II : Retrieval
Retrieval in LangChain performs an important function in purposes that require user-specific knowledge, not included within the mannequin’s coaching set. This course of, often called Retrieval Augmented Technology (RAG), entails fetching exterior knowledge and integrating it into the language mannequin’s technology course of. LangChain offers a complete suite of instruments and functionalities to facilitate this course of, catering to each easy and sophisticated purposes.
LangChain achieves retrieval by way of a sequence of parts which we’ll talk about one after the other.
Doc Loaders
Doc loaders in LangChain allow the extraction of information from numerous sources. With over 100 loaders out there, they assist a variety of doc sorts, apps and sources (personal s3 buckets, public web sites, databases).
You’ll be able to select a doc loader based mostly in your necessities right here.
All these loaders ingest knowledge into Doc courses. We’ll discover ways to use knowledge ingested into Doc courses later.
Textual content File Loader: Load a easy .txt file right into a doc.
from langchain.document_loaders import TextLoader
loader = TextLoader("./pattern.txt")
doc = loader.load()
CSV Loader: Load a CSV file right into a doc.
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="./example_data/pattern.csv")
paperwork = loader.load()
We are able to select to customise the parsing by specifying area names –
loader = CSVLoader(file_path="./example_data/mlb_teams_2012.csv", csv_args={
'delimiter': ',',
'quotechar': '"',
'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
paperwork = loader.load()
PDF Loaders: PDF Loaders in LangChain supply numerous strategies for parsing and extracting content material from PDF information. Every loader caters to completely different necessities and makes use of completely different underlying libraries. Under are detailed examples for every loader.
PyPDFLoader is used for primary PDF parsing.
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
MathPixLoader is right for extracting mathematical content material and diagrams.
from langchain.document_loaders import MathpixPDFLoader
loader = MathpixPDFLoader("example_data/math-content.pdf")
knowledge = loader.load()
PyMuPDFLoader is quick and consists of detailed metadata extraction.
from langchain.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
knowledge = loader.load()
# Optionally go further arguments for PyMuPDF's get_text() name
knowledge = loader.load(possibility="textual content")
PDFMiner Loader is used for extra granular management over textual content extraction.
from langchain.document_loaders import PDFMinerLoader
loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
knowledge = loader.load()
AmazonTextractPDFParser makes use of AWS Textract for OCR and different superior PDF parsing options.
from langchain.document_loaders import AmazonTextractPDFLoader
# Requires AWS account and configuration
loader = AmazonTextractPDFLoader("example_data/complex-layout.pdf")
paperwork = loader.load()
PDFMinerPDFasHTMLLoader generates HTML from PDF for semantic parsing.
from langchain.document_loaders import PDFMinerPDFasHTMLLoader
loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
knowledge = loader.load()
PDFPlumberLoader offers detailed metadata and helps one doc per web page.
from langchain.document_loaders import PDFPlumberLoader
loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
knowledge = loader.load()
Built-in Loaders: LangChain affords all kinds of customized loaders to straight load knowledge out of your apps (reminiscent of Slack, Sigma, Notion, Confluence, Google Drive and lots of extra) and databases and use them in LLM purposes.
The entire listing is right here.
Under are a few examples as an example this –
Instance I – Slack
Slack, a widely-used prompt messaging platform, could be built-in into LLM workflows and purposes.
- Go to your Slack Workspace Administration web page.
- Navigate to
{your_slack_domain}.slack.com/companies/export. - Choose the specified date vary and provoke the export.
- Slack notifies through e-mail and DM as soon as the export is prepared.
- The export ends in a
.zipfile positioned in your Downloads folder or your designated obtain path. - Assign the trail of the downloaded
.zipfile toLOCAL_ZIPFILE. - Use the
SlackDirectoryLoaderfrom thelangchain.document_loaderspackage deal.
from langchain.document_loaders import SlackDirectoryLoader
SLACK_WORKSPACE_URL = "https://xxx.slack.com" # Change together with your Slack URL
LOCAL_ZIPFILE = "" # Path to the Slack zip file
loader = SlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
print(docs)
Instance II – Figma
Figma, a well-liked instrument for interface design, affords a REST API for knowledge integration.
- Acquire the Figma file key from the URL format:
https://www.figma.com/file/{filekey}/sampleFilename. - Node IDs are discovered within the URL parameter
?node-id={node_id}. - Generate an entry token following directions on the Figma Assist Middle.
- The
FigmaFileLoaderclass fromlangchain.document_loaders.figmais used to load Figma knowledge. - Varied LangChain modules like
CharacterTextSplitter,ChatOpenAI, and many others., are employed for processing.
import os
from langchain.document_loaders.figma import FigmaFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationChain, LLMChain
from langchain.reminiscence import ConversationBufferWindowMemory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate
figma_loader = FigmaFileLoader(
os.environ.get("ACCESS_TOKEN"),
os.environ.get("NODE_IDS"),
os.environ.get("FILE_KEY"),
)
index = VectorstoreIndexCreator().from_loaders([figma_loader])
figma_doc_retriever = index.vectorstore.as_retriever()
- The
generate_codeperform makes use of the Figma knowledge to create HTML/CSS code. - It employs a templated dialog with a GPT-based mannequin.
def generate_code(human_input):
# Template for system and human prompts
system_prompt_template = "Your coding directions..."
human_prompt_template = "Code the {textual content}. Guarantee it is cellular responsive"
# Creating immediate templates
system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template)
human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template)
# Organising the AI mannequin
gpt_4 = ChatOpenAI(temperature=0.02, model_name="gpt-4")
# Retrieving related paperwork
relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input)
# Producing and formatting the immediate
dialog = [system_message_prompt, human_message_prompt]
chat_prompt = ChatPromptTemplate.from_messages(dialog)
response = gpt_4(chat_prompt.format_prompt(context=relevant_nodes, textual content=human_input).to_messages())
return response
# Instance utilization
response = generate_code("web page prime header")
print(response.content material)
- The
generate_codeperform, when executed, returns HTML/CSS code based mostly on the Figma design enter.
Allow us to now use our information to create a number of doc units.
We first load a PDF, the BCG annual sustainability report.
We use the PyPDFLoader for this.
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
pdfpages = loader.load_and_split()
We’ll ingest knowledge from Airtable now. Now we have an Airtable containing details about numerous OCR and knowledge extraction fashions –
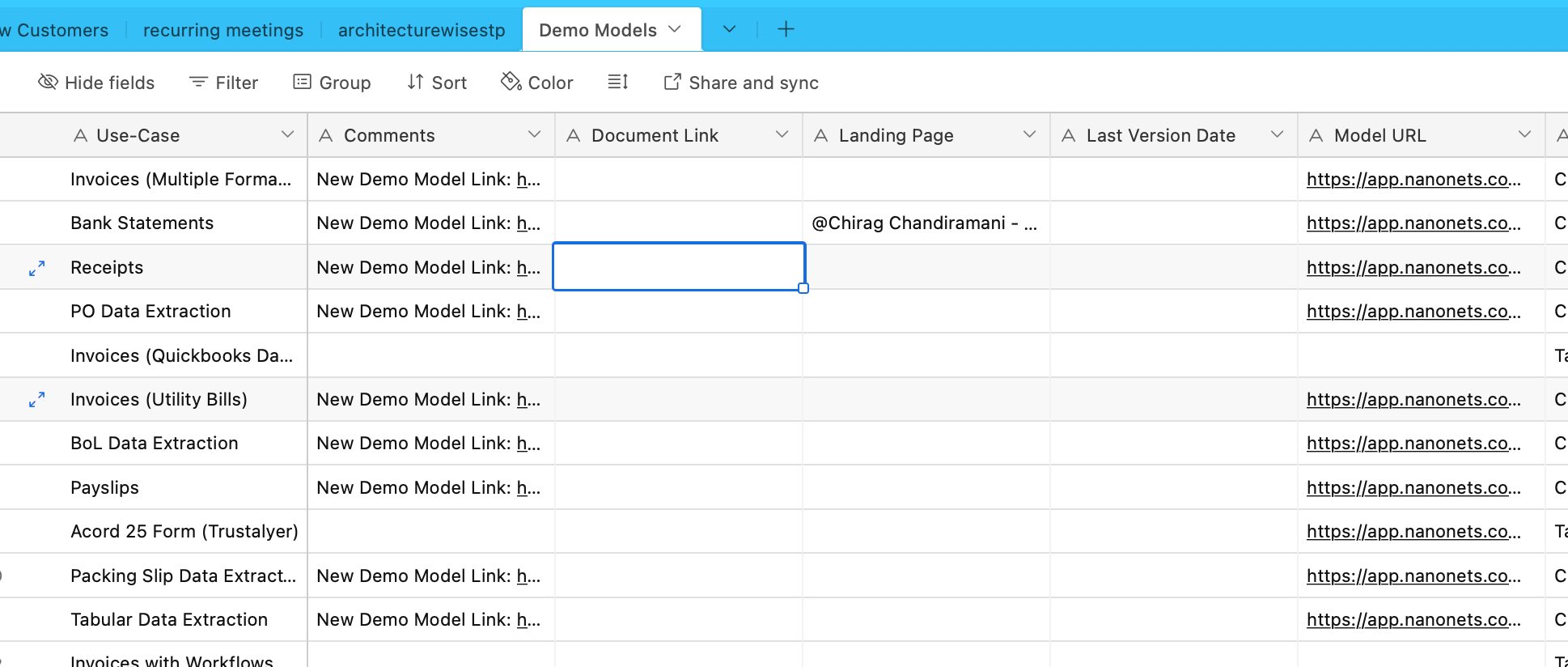
Allow us to use the AirtableLoader for this, discovered within the listing of built-in loaders.
from langchain.document_loaders import AirtableLoader
api_key = "XXXXX"
base_id = "XXXXX"
table_id = "XXXXX"
loader = AirtableLoader(api_key, table_id, base_id)
airtabledocs = loader.load()
Allow us to now proceed and discover ways to use these doc courses.
Doc Transformers
Doc transformers in LangChain are important instruments designed to govern paperwork, which we created in our earlier subsection.
They’re used for duties reminiscent of splitting lengthy paperwork into smaller chunks, combining, and filtering, that are essential for adapting paperwork to a mannequin’s context window or assembly particular software wants.
One such instrument is the RecursiveCharacterTextSplitter, a flexible textual content splitter that makes use of a personality listing for splitting. It permits parameters like chunk dimension, overlap, and beginning index. Here is an instance of the way it’s utilized in Python:
from langchain.text_splitter import RecursiveCharacterTextSplitter
state_of_the_union = "Your lengthy textual content right here..."
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
length_function=len,
add_start_index=True,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
One other instrument is the CharacterTextSplitter, which splits textual content based mostly on a specified character and consists of controls for chunk dimension and overlap:
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="nn",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
The HTMLHeaderTextSplitter is designed to separate HTML content material based mostly on header tags, retaining the semantic construction:
from langchain.text_splitter import HTMLHeaderTextSplitter
html_string = "Your HTML content material right here..."
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits[0])
A extra complicated manipulation could be achieved by combining HTMLHeaderTextSplitter with one other splitter, just like the Pipelined Splitter:
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter
url = "https://instance.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
chunk_size = 500
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
splits = text_splitter.split_documents(html_header_splits)
print(splits[0])
LangChain additionally affords particular splitters for various programming languages, just like the Python Code Splitter and the JavaScript Code Splitter:
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language
python_code = """
def hello_world():
print("Hiya, World!")
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50
)
python_docs = python_splitter.create_documents([python_code])
print(python_docs[0])
js_code = """
perform helloWorld() {
console.log("Hiya, World!");
}
helloWorld();
"""
js_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.JS, chunk_size=60
)
js_docs = js_splitter.create_documents([js_code])
print(js_docs[0])
For splitting textual content based mostly on token rely, which is helpful for language fashions with token limits, the TokenTextSplitter is used:
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=10)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
Lastly, the LongContextReorder reorders paperwork to forestall efficiency degradation in fashions as a consequence of lengthy contexts:
from langchain.document_transformers import LongContextReorder
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs[0])
These instruments display numerous methods to remodel paperwork in LangChain, from easy textual content splitting to complicated reordering and language-specific splitting. For extra in-depth and particular use circumstances, the LangChain documentation and Integrations part ought to be consulted.
In our examples, the loaders have already created chunked paperwork for us, and this half is already dealt with.
Textual content Embedding Fashions
Textual content embedding fashions in LangChain present a standardized interface for numerous embedding mannequin suppliers like OpenAI, Cohere, and Hugging Face. These fashions remodel textual content into vector representations, enabling operations like semantic search by way of textual content similarity in vector house.
To get began with textual content embedding fashions, you usually want to put in particular packages and arrange API keys. Now we have already finished this for OpenAI
In LangChain, the embed_documents methodology is used to embed a number of texts, offering a listing of vector representations. As an illustration:
from langchain.embeddings import OpenAIEmbeddings
# Initialize the mannequin
embeddings_model = OpenAIEmbeddings()
# Embed a listing of texts
embeddings = embeddings_model.embed_documents(
["Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!"]
)
print("Variety of paperwork embedded:", len(embeddings))
print("Dimension of every embedding:", len(embeddings[0]))
For embedding a single textual content, reminiscent of a search question, the embed_query methodology is used. That is helpful for evaluating a question to a set of doc embeddings. For instance:
from langchain.embeddings import OpenAIEmbeddings
# Initialize the mannequin
embeddings_model = OpenAIEmbeddings()
# Embed a single question
embedded_query = embeddings_model.embed_query("What was the title talked about within the dialog?")
print("First 5 dimensions of the embedded question:", embedded_query[:5])
Understanding these embeddings is essential. Every bit of textual content is transformed right into a vector, the dimension of which is determined by the mannequin used. As an illustration, OpenAI fashions usually produce 1536-dimensional vectors. These embeddings are then used for retrieving related info.
LangChain’s embedding performance just isn’t restricted to OpenAI however is designed to work with numerous suppliers. The setup and utilization may barely differ relying on the supplier, however the core idea of embedding texts into vector house stays the identical. For detailed utilization, together with superior configurations and integrations with completely different embedding mannequin suppliers, the LangChain documentation within the Integrations part is a precious useful resource.
Vector Shops
Vector shops in LangChain assist the environment friendly storage and looking of textual content embeddings. LangChain integrates with over 50 vector shops, offering a standardized interface for ease of use.
Instance: Storing and Looking out Embeddings
After embedding texts, we will retailer them in a vector retailer like Chroma and carry out similarity searches:
from langchain.vectorstores import Chroma
db = Chroma.from_texts(embedded_texts)
similar_texts = db.similarity_search("search question")
Allow us to alternatively use the FAISS vector retailer to create indexes for our paperwork.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
pdfstore = FAISS.from_documents(pdfpages,
embedding=OpenAIEmbeddings())
airtablestore = FAISS.from_documents(airtabledocs,
embedding=OpenAIEmbeddings())

Retrievers
Retrievers in LangChain are interfaces that return paperwork in response to an unstructured question. They’re extra normal than vector shops, specializing in retrieval fairly than storage. Though vector shops can be utilized as a retriever’s spine, there are different varieties of retrievers as nicely.
To arrange a Chroma retriever, you first set up it utilizing pip set up chromadb. Then, you load, cut up, embed, and retrieve paperwork utilizing a sequence of Python instructions. Here is a code instance for establishing a Chroma retriever:
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
full_text = open("state_of_the_union.txt", "r").learn()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text)
embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
retriever = db.as_retriever()
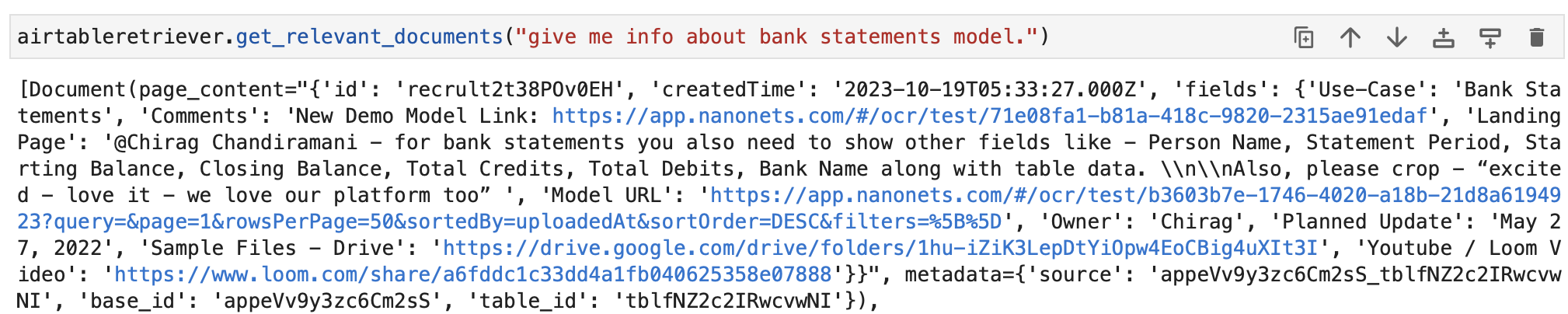
retrieved_docs = retriever.invoke("What did the president say about Ketanji Brown Jackson?")
print(retrieved_docs[0].page_content)
The MultiQueryRetriever automates immediate tuning by producing a number of queries for a person enter question and combines the outcomes. Here is an instance of its easy utilization:
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever
query = "What are the approaches to Activity Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=db.as_retriever(), llm=llm
)
unique_docs = retriever_from_llm.get_relevant_documents(question=query)
print("Variety of distinctive paperwork:", len(unique_docs))
Contextual Compression in LangChain compresses retrieved paperwork utilizing the context of the question, making certain solely related info is returned. This entails content material discount and filtering out much less related paperwork. The next code instance exhibits learn how to use Contextual Compression Retriever:
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever)
compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
print(compressed_docs[0].page_content)
The EnsembleRetriever combines completely different retrieval algorithms to realize higher efficiency. An instance of mixing BM25 and FAISS Retrievers is proven within the following code:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS
bm25_retriever = BM25Retriever.from_texts(doc_list).set_k(2)
faiss_vectorstore = FAISS.from_texts(doc_list, OpenAIEmbeddings())
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"ok": 2})
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)
docs = ensemble_retriever.get_relevant_documents("apples")
print(docs[0].page_content)
MultiVector Retriever in LangChain permits querying paperwork with a number of vectors per doc, which is helpful for capturing completely different semantic features inside a doc. Strategies for creating a number of vectors embody splitting into smaller chunks, summarizing, or producing hypothetical questions. For splitting paperwork into smaller chunks, the next Python code can be utilized:
python
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders from TextLoader
import uuid
loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
retailer = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=retailer, id_key=id_key)
doc_ids = [str(uuid.uuid4()) for _ in docs]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [sub_doc for doc in docs for sub_doc in child_text_splitter.split_documents([doc])]
for sub_doc in sub_docs:
sub_doc.metadata[id_key] = doc_ids[sub_docs.index(sub_doc)]
retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(listing(zip(doc_ids, docs)))
Producing summaries for higher retrieval as a consequence of extra targeted content material illustration is one other methodology. Here is an instance of producing summaries:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.doc import Doc
chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize the next doc:nn{doc}") | ChatOpenAI(max_retries=0) | StrOutputParser()
summaries = chain.batch(docs, {"max_concurrency": 5})
summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(listing(zip(doc_ids, docs)))
Producing hypothetical questions related to every doc utilizing LLM is one other method. This may be finished with the next code:
features = [{"name": "hypothetical_questions", "parameters": {"questions": {"type": "array", "items": {"type": "string"}}}}]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser
chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Generate 3 hypothetical questions:nn{doc}") | ChatOpenAI(max_retries=0).bind(features=features, function_call={"title": "hypothetical_questions"}) | JsonKeyOutputFunctionsParser(key_name="questions")
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5})
question_docs = [Document(page_content=q, metadata={id_key: doc_ids[i]}) for i, questions in enumerate(hypothetical_questions) for q in questions]
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(listing(zip(doc_ids, docs)))
The Mum or dad Doc Retriever is one other retriever that strikes a steadiness between embedding accuracy and context retention by storing small chunks and retrieving their bigger guardian paperwork. Its implementation is as follows:
from langchain.retrievers import ParentDocumentRetriever
loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
retailer = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore, docstore=retailer, child_splitter=child_splitter)
retriever.add_documents(docs, ids=None)
retrieved_docs = retriever.get_relevant_documents("question")
A self-querying retriever constructs structured queries from pure language inputs and applies them to its underlying VectorStore. Its implementation is proven within the following code:
from langchain.chat_models from ChatOpenAI
from langchain.chains.query_constructor.base from AttributeInfo
from langchain.retrievers.self_query.base from SelfQueryRetriever
metadata_field_info = [AttributeInfo(name="genre", description="...", type="string"), ...]
document_content_description = "Temporary abstract of a film"
llm = ChatOpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info)
retrieved_docs = retriever.invoke("question")
The WebResearchRetriever performs net analysis based mostly on a given question –
from langchain.retrievers.web_research import WebResearchRetriever
# Initialize parts
llm = ChatOpenAI(temperature=0)
search = GoogleSearchAPIWrapper()
vectorstore = Chroma(embedding_function=OpenAIEmbeddings())
# Instantiate WebResearchRetriever
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search)
# Retrieve paperwork
docs = web_research_retriever.get_relevant_documents("question")
For our examples, we will additionally use the usual retriever already carried out as a part of our vector retailer object as follows –

We are able to now question the retrievers. The output of our question can be doc objects related to the question. These can be finally utilized to create related responses in additional sections.

Automate guide duties and workflows with our AI-driven workflow builder, designed by Nanonets for you and your groups.
Module III : Brokers
LangChain introduces a strong idea referred to as “Brokers” that takes the concept of chains to an entire new stage. Brokers leverage language fashions to dynamically decide sequences of actions to carry out, making them extremely versatile and adaptive. In contrast to conventional chains, the place actions are hardcoded in code, brokers make use of language fashions as reasoning engines to resolve which actions to take and in what order.
The Agent is the core part accountable for decision-making. It harnesses the ability of a language mannequin and a immediate to find out the following steps to realize a selected goal. The inputs to an agent usually embody:
- Instruments: Descriptions of accessible instruments (extra on this later).
- Consumer Enter: The high-level goal or question from the person.
- Intermediate Steps: A historical past of (motion, instrument output) pairs executed to succeed in the present person enter.
The output of an agent could be the following motion to take actions (AgentActions) or the ultimate response to ship to the person (AgentFinish). An motion specifies a instrument and the enter for that instrument.
Instruments
Instruments are interfaces that an agent can use to work together with the world. They allow brokers to carry out numerous duties, reminiscent of looking the net, working shell instructions, or accessing exterior APIs. In LangChain, instruments are important for extending the capabilities of brokers and enabling them to perform various duties.
To make use of instruments in LangChain, you may load them utilizing the next snippet:
from langchain.brokers import load_tools
tool_names = [...]
instruments = load_tools(tool_names)
Some instruments might require a base Language Mannequin (LLM) to initialize. In such circumstances, you may go an LLM as nicely:
from langchain.brokers import load_tools
tool_names = [...]
llm = ...
instruments = load_tools(tool_names, llm=llm)
This setup lets you entry quite a lot of instruments and combine them into your agent’s workflows. The entire listing of instruments with utilization documentation is right here.
Allow us to have a look at some examples of Instruments.
DuckDuckGo
The DuckDuckGo instrument allows you to carry out net searches utilizing its search engine. Here is learn how to use it:
from langchain.instruments import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("manchester united vs luton city match abstract")

DataForSeo
The DataForSeo toolkit lets you receive search engine outcomes utilizing the DataForSeo API. To make use of this toolkit, you may must arrange your API credentials. Here is learn how to configure the credentials:
import os
os.environ["DATAFORSEO_LOGIN"] = "<your_api_access_username>"
os.environ["DATAFORSEO_PASSWORD"] = "<your_api_access_password>"
As soon as your credentials are set, you may create a DataForSeoAPIWrapper instrument to entry the API:
from langchain.utilities.dataforseo_api_search import DataForSeoAPIWrapper
wrapper = DataForSeoAPIWrapper()
outcome = wrapper.run("Climate in Los Angeles")
The DataForSeoAPIWrapper instrument retrieves search engine outcomes from numerous sources.
You’ll be able to customise the kind of outcomes and fields returned within the JSON response. For instance, you may specify the outcome sorts, fields, and set a most rely for the variety of prime outcomes to return:
json_wrapper = DataForSeoAPIWrapper(
json_result_types=["organic", "knowledge_graph", "answer_box"],
json_result_fields=["type", "title", "description", "text"],
top_count=3,
)
json_result = json_wrapper.outcomes("Invoice Gates")
This instance customizes the JSON response by specifying outcome sorts, fields, and limiting the variety of outcomes.
You too can specify the placement and language on your search outcomes by passing further parameters to the API wrapper:
customized_wrapper = DataForSeoAPIWrapper(
top_count=10,
json_result_types=["organic", "local_pack"],
json_result_fields=["title", "description", "type"],
params={"location_name": "Germany", "language_code": "en"},
)
customized_result = customized_wrapper.outcomes("espresso close to me")
By offering location and language parameters, you may tailor your search outcomes to particular areas and languages.
You’ve the pliability to decide on the search engine you wish to use. Merely specify the specified search engine:
customized_wrapper = DataForSeoAPIWrapper(
top_count=10,
json_result_types=["organic", "local_pack"],
json_result_fields=["title", "description", "type"],
params={"location_name": "Germany", "language_code": "en", "se_name": "bing"},
)
customized_result = customized_wrapper.outcomes("espresso close to me")
On this instance, the search is personalized to make use of Bing because the search engine.
The API wrapper additionally lets you specify the kind of search you wish to carry out. As an illustration, you may carry out a maps search:
maps_search = DataForSeoAPIWrapper(
top_count=10,
json_result_fields=["title", "value", "address", "rating", "type"],
params={
"location_coordinate": "52.512,13.36,12z",
"language_code": "en",
"se_type": "maps",
},
)
maps_search_result = maps_search.outcomes("espresso close to me")
This customizes the search to retrieve maps-related info.
Shell (bash)
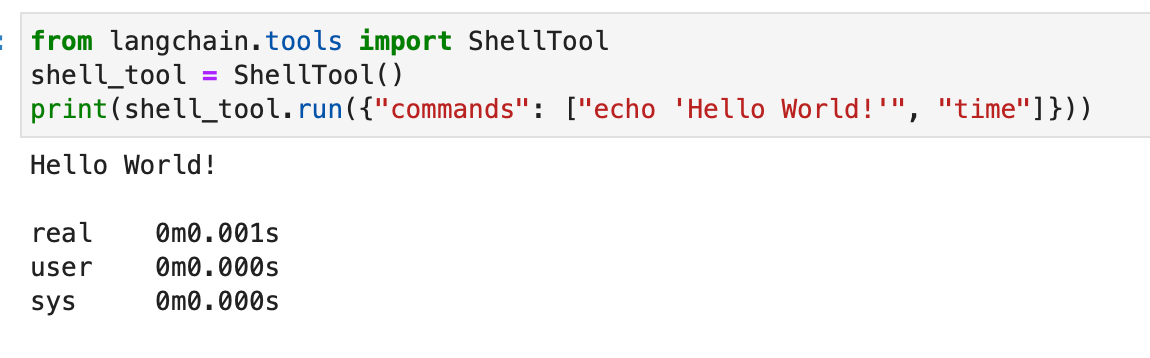
The Shell toolkit offers brokers with entry to the shell surroundings, permitting them to execute shell instructions. This characteristic is highly effective however ought to be used with warning, particularly in sandboxed environments. Here is how you should use the Shell instrument:
from langchain.instruments import ShellTool
shell_tool = ShellTool()
outcome = shell_tool.run({"instructions": ["echo 'Hello World!'", "time"]})
On this instance, the Shell instrument runs two shell instructions: echoing “Hiya World!” and displaying the present time.
You’ll be able to present the Shell instrument to an agent to carry out extra complicated duties. Here is an instance of an agent fetching hyperlinks from an internet web page utilizing the Shell instrument:
from langchain.brokers import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0.1)
shell_tool.description = shell_tool.description + f"args {shell_tool.args}".change(
"{", "{{"
).change("}", "}}")
self_ask_with_search = initialize_agent(
[shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
self_ask_with_search.run(
"Obtain the langchain.com webpage and grep for all urls. Return solely a sorted listing of them. Make sure you use double quotes."
)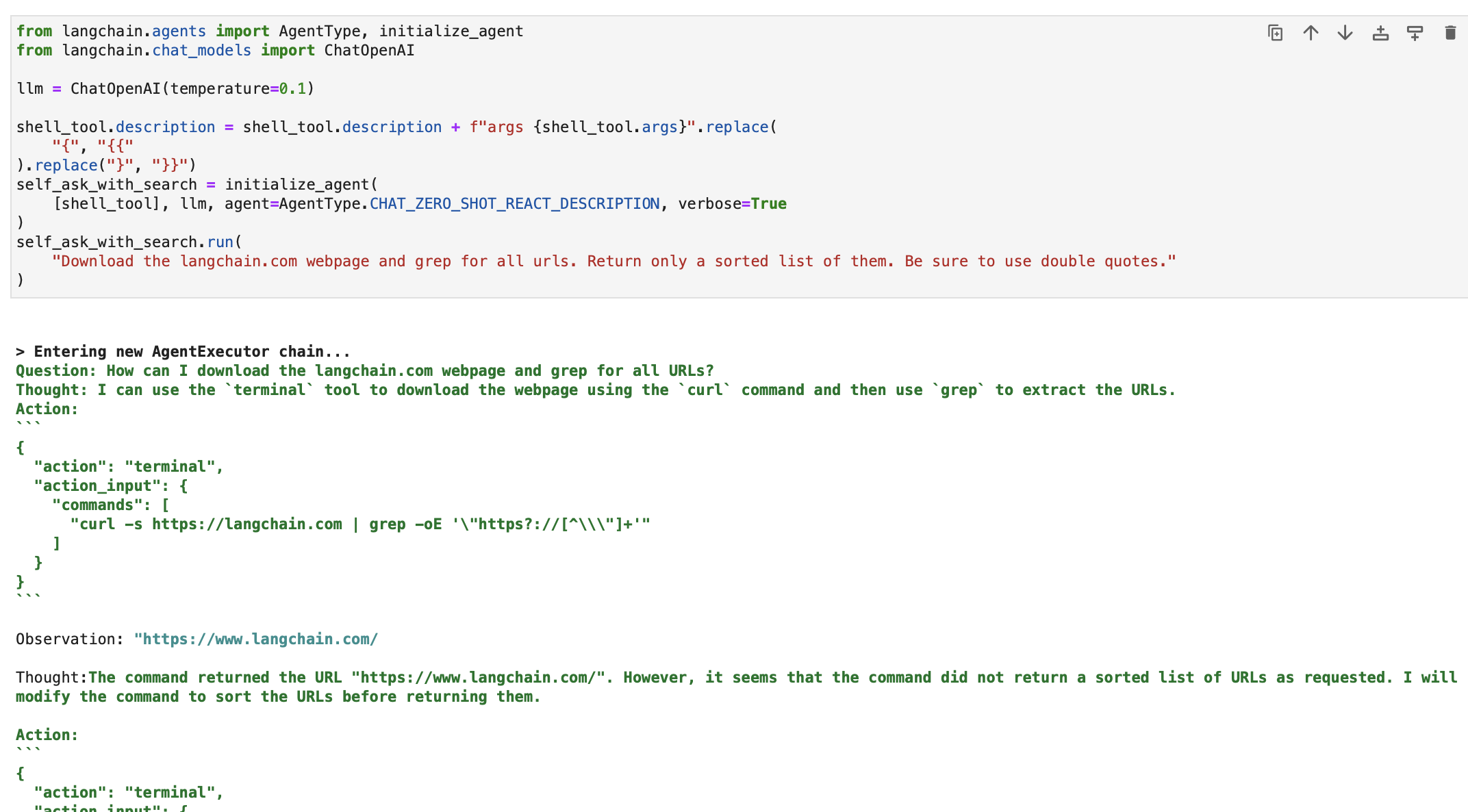
On this state of affairs, the agent makes use of the Shell instrument to execute a sequence of instructions to fetch, filter, and kind URLs from an internet web page.
The examples offered display among the instruments out there in LangChain. These instruments finally lengthen the capabilities of brokers (explored in subsequent subsection) and empower them to carry out numerous duties effectively. Relying in your necessities, you may select the instruments and toolkits that finest fit your undertaking’s wants and combine them into your agent’s workflows.
Again to Brokers
Let’s transfer on to brokers now.
The AgentExecutor is the runtime surroundings for an agent. It’s accountable for calling the agent, executing the actions it selects, passing the motion outputs again to the agent, and repeating the method till the agent finishes. In pseudocode, the AgentExecutor may look one thing like this:
next_action = agent.get_action(...)
whereas next_action != AgentFinish:
statement = run(next_action)
next_action = agent.get_action(..., next_action, statement)
return next_action
The AgentExecutor handles numerous complexities, reminiscent of coping with circumstances the place the agent selects a non-existent instrument, dealing with instrument errors, managing agent-produced outputs, and offering logging and observability in any respect ranges.
Whereas the AgentExecutor class is the first agent runtime in LangChain, there are different, extra experimental runtimes supported, together with:
- Plan-and-execute Agent
- Child AGI
- Auto GPT
To realize a greater understanding of the agent framework, let’s construct a primary agent from scratch, after which transfer on to discover pre-built brokers.
Earlier than we dive into constructing the agent, it is important to revisit some key terminology and schema:
- AgentAction: This can be a knowledge class representing the motion an agent ought to take. It consists of a
instrumentproperty (the title of the instrument to invoke) and atool_inputproperty (the enter for that instrument). - AgentFinish: This knowledge class signifies that the agent has completed its process and may return a response to the person. It usually features a dictionary of return values, typically with a key “output” containing the response textual content.
- Intermediate Steps: These are the data of earlier agent actions and corresponding outputs. They’re essential for passing context to future iterations of the agent.
In our instance, we’ll use OpenAI Operate Calling to create our agent. This method is dependable for agent creation. We’ll begin by making a easy instrument that calculates the size of a phrase. This instrument is helpful as a result of language fashions can generally make errors as a consequence of tokenization when counting phrase lengths.
First, let’s load the language mannequin we’ll use to manage the agent:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(mannequin="gpt-3.5-turbo", temperature=0)
Let’s check the mannequin with a phrase size calculation:
llm.invoke("what number of letters within the phrase educa?")
The response ought to point out the variety of letters within the phrase “educa.”
Subsequent, we’ll outline a easy Python perform to calculate the size of a phrase:
from langchain.brokers import instrument
@instrument
def get_word_length(phrase: str) -> int:
"""Returns the size of a phrase."""
return len(phrase)
We have created a instrument named get_word_length that takes a phrase as enter and returns its size.
Now, let’s create the immediate for the agent. The immediate instructs the agent on learn how to purpose and format the output. In our case, we’re utilizing OpenAI Operate Calling, which requires minimal directions. We’ll outline the immediate with placeholders for person enter and agent scratchpad:
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
immediate = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a very powerful assistant but not great at calculating word lengths.",
),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
Now, how does the agent know which instruments it may well use? We’re counting on OpenAI perform calling language fashions, which require features to be handed individually. To supply our instruments to the agent, we’ll format them as OpenAI perform calls:
from langchain.instruments.render import format_tool_to_openai_function
llm_with_tools = llm.bind(features=[format_tool_to_openai_function(t) for t in tools])
Now, we will create the agent by defining enter mappings and connecting the parts:
That is LCEL language. We’ll talk about this later intimately.
from langchain.brokers.format_scratchpad import format_to_openai_function_messages
from langchain.brokers.output_parsers import OpenAIFunctionsAgentOutputParser
agent = (
{
"enter": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai
_function_messages(
x["intermediate_steps"]
),
}
| immediate
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
We have created our agent, which understands person enter, makes use of out there instruments, and codecs output. Now, let’s work together with it:
agent.invoke({"enter": "what number of letters within the phrase educa?", "intermediate_steps": []})
The agent ought to reply with an AgentAction, indicating the following motion to take.
We have created the agent, however now we have to write a runtime for it. The best runtime is one which constantly calls the agent, executes actions, and repeats till the agent finishes. Here is an instance:
from langchain.schema.agent import AgentFinish
user_input = "what number of letters within the phrase educa?"
intermediate_steps = []
whereas True:
output = agent.invoke(
{
"enter": user_input,
"intermediate_steps": intermediate_steps,
}
)
if isinstance(output, AgentFinish):
final_result = output.return_values["output"]
break
else:
print(f"TOOL NAME: {output.instrument}")
print(f"TOOL INPUT: {output.tool_input}")
instrument = {"get_word_length": get_word_length}[output.tool]
statement = instrument.run(output.tool_input)
intermediate_steps.append((output, statement))
print(final_result)
On this loop, we repeatedly name the agent, execute actions, and replace the intermediate steps till the agent finishes. We additionally deal with instrument interactions throughout the loop.

To simplify this course of, LangChain offers the AgentExecutor class, which encapsulates agent execution and affords error dealing with, early stopping, tracing, and different enhancements. Let’s use AgentExecutor to work together with the agent:
from langchain.brokers import AgentExecutor
agent_executor = AgentExecutor(agent=agent, instruments=instruments, verbose=True)
agent_executor.invoke({"enter": "what number of letters within the phrase educa?"})
AgentExecutor simplifies the execution course of and offers a handy approach to work together with the agent.
Reminiscence can be mentioned intimately later.
The agent we have created to date is stateless, which means it does not bear in mind earlier interactions. To allow follow-up questions and conversations, we have to add reminiscence to the agent. This entails two steps:
- Add a reminiscence variable within the immediate to retailer chat historical past.
- Hold monitor of the chat historical past throughout interactions.
Let’s begin by including a reminiscence placeholder within the immediate:
from langchain.prompts import MessagesPlaceholder
MEMORY_KEY = "chat_history"
immediate = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a very powerful assistant but not great at calculating word lengths.",
),
MessagesPlaceholder(variable_name=MEMORY_KEY),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
Now, create a listing to trace the chat historical past:
from langchain.schema.messages import HumanMessage, AIMessage
chat_history = []
Within the agent creation step, we’ll embody the reminiscence as nicely:
agent = (
{
"enter": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
"chat_history": lambda x: x["chat_history"],
}
| immediate
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
Now, when working the agent, be certain to replace the chat historical past:
input1 = "what number of letters within the phrase educa?"
outcome = agent_executor.invoke({"enter": input1, "chat_history": chat_history})
chat_history.lengthen([
HumanMessage(content=input1),
AIMessage(content=result["output"]),
])
agent_executor.invoke({"enter": "is that an actual phrase?", "chat_history": chat_history})
This allows the agent to keep up a dialog historical past and reply follow-up questions based mostly on earlier interactions.
Congratulations! You’ve got efficiently created and executed your first end-to-end agent in LangChain. To delve deeper into LangChain’s capabilities, you may discover:
- Completely different agent sorts supported.
- Pre-built Brokers
- Methods to work with instruments and power integrations.
Agent Sorts
LangChain affords numerous agent sorts, every fitted to particular use circumstances. Listed here are among the out there brokers:
- Zero-shot ReAct: This agent makes use of the ReAct framework to decide on instruments based mostly solely on their descriptions. It requires descriptions for every instrument and is very versatile.
- Structured enter ReAct: This agent handles multi-input instruments and is appropriate for complicated duties like navigating an internet browser. It makes use of a instruments’ argument schema for structured enter.
- OpenAI Features: Particularly designed for fashions fine-tuned for perform calling, this agent is appropriate with fashions like gpt-3.5-turbo-0613 and gpt-4-0613. We used this to create our first agent above.
- Conversational: Designed for conversational settings, this agent makes use of ReAct for instrument choice and makes use of reminiscence to recollect earlier interactions.
- Self-ask with search: This agent depends on a single instrument, “Intermediate Reply,” which appears up factual solutions to questions. It is equal to the unique self-ask with search paper.
- ReAct doc retailer: This agent interacts with a doc retailer utilizing the ReAct framework. It requires “Search” and “Lookup” instruments and is just like the unique ReAct paper’s Wikipedia instance.
Discover these agent sorts to search out the one which most closely fits your wants in LangChain. These brokers can help you bind set of instruments inside them to deal with actions and generate responses. Be taught extra on learn how to construct your individual agent with instruments right here.
Prebuilt Brokers
Let’s proceed our exploration of brokers, specializing in prebuilt brokers out there in LangChain.
Gmail
LangChain affords a Gmail toolkit that lets you join your LangChain e-mail to the Gmail API. To get began, you may must arrange your credentials, that are defined within the Gmail API documentation. Upon getting downloaded the credentials.json file, you may proceed with utilizing the Gmail API. Moreover, you may want to put in some required libraries utilizing the next instructions:
pip set up --upgrade google-api-python-client > /dev/null
pip set up --upgrade google-auth-oauthlib > /dev/null
pip set up --upgrade google-auth-httplib2 > /dev/null
pip set up beautifulsoup4 > /dev/null # Optionally available for parsing HTML messages
You’ll be able to create the Gmail toolkit as follows:
from langchain.brokers.agent_toolkits import GmailToolkit
toolkit = GmailToolkit()
You too can customise authentication as per your wants. Behind the scenes, a googleapi useful resource is created utilizing the next strategies:
from langchain.instruments.gmail.utils import build_resource_service, get_gmail_credentials
credentials = get_gmail_credentials(
token_file="token.json",
scopes=["https://mail.google.com/"],
client_secrets_file="credentials.json",
)
api_resource = build_resource_service(credentials=credentials)
toolkit = GmailToolkit(api_resource=api_resource)
The toolkit affords numerous instruments that can be utilized inside an agent, together with:
GmailCreateDraft: Create a draft e-mail with specified message fields.GmailSendMessage: Ship e-mail messages.GmailSearch: Seek for e-mail messages or threads.GmailGetMessage: Fetch an e-mail by message ID.GmailGetThread: Seek for e-mail messages.
To make use of these instruments inside an agent, you may initialize the agent as follows:
from langchain.llms import OpenAI
from langchain.brokers import initialize_agent, AgentType
llm = OpenAI(temperature=0)
agent = initialize_agent(
instruments=toolkit.get_tools(),
llm=llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
)
Listed here are a few examples of how these instruments can be utilized:
- Create a Gmail draft for enhancing:
agent.run(
"Create a gmail draft for me to edit of a letter from the angle of a sentient parrot "
"who's trying to collaborate on some analysis together with her estranged buddy, a cat. "
"By no means might you ship the message, nevertheless."
)
- Seek for the most recent e-mail in your drafts:
agent.run("Might you search in my drafts for the most recent e-mail?")
These examples display the capabilities of LangChain’s Gmail toolkit inside an agent, enabling you to work together with Gmail programmatically.
SQL Database Agent
This part offers an outline of an agent designed to work together with SQL databases, notably the Chinook database. This agent can reply normal questions on a database and recuperate from errors. Please notice that it’s nonetheless in energetic growth, and never all solutions could also be right. Be cautious when working it on delicate knowledge, as it might carry out DML statements in your database.
To make use of this agent, you may initialize it as follows:
from langchain.brokers import create_sql_agent
from langchain.brokers.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.brokers import AgentExecutor
from langchain.brokers.agent_types import AgentType
from langchain.chat_models import ChatOpenAI
db = SQLDatabase.from_uri("sqlite:///../../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0))
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
This agent could be initialized utilizing the ZERO_SHOT_REACT_DESCRIPTION agent sort. It’s designed to reply questions and supply descriptions. Alternatively, you may initialize the agent utilizing the OPENAI_FUNCTIONS agent sort with OpenAI’s GPT-3.5-turbo mannequin, which we utilized in our earlier consumer.
Disclaimer
- The question chain might generate insert/replace/delete queries. Be cautious, and use a customized immediate or create a SQL person with out write permissions if wanted.
- Bear in mind that working sure queries, reminiscent of “run the largest question potential,” might overload your SQL database, particularly if it incorporates tens of millions of rows.
- Knowledge warehouse-oriented databases typically assist user-level quotas to restrict useful resource utilization.
You’ll be able to ask the agent to explain a desk, such because the “playlisttrack” desk. Here is an instance of learn how to do it:
agent_executor.run("Describe the playlisttrack desk")
The agent will present details about the desk’s schema and pattern rows.
When you mistakenly ask a few desk that does not exist, the agent can recuperate and supply details about the closest matching desk. For instance:
agent_executor.run("Describe the playlistsong desk")
The agent will discover the closest matching desk and supply details about it.
You too can ask the agent to run queries on the database. As an illustration:
agent_executor.run("Checklist the full gross sales per nation. Which nation's clients spent essentially the most?")
The agent will execute the question and supply the outcome, such because the nation with the very best complete gross sales.
To get the full variety of tracks in every playlist, you should use the next question:
agent_executor.run("Present the full variety of tracks in every playlist. The Playlist title ought to be included within the outcome.")
The agent will return the playlist names together with the corresponding complete monitor counts.
In circumstances the place the agent encounters errors, it may well recuperate and supply correct responses. As an illustration:
agent_executor.run("Who're the highest 3 finest promoting artists?")
Even after encountering an preliminary error, the agent will modify and supply the right reply, which, on this case, is the highest 3 best-selling artists.
Pandas DataFrame Agent
This part introduces an agent designed to work together with Pandas DataFrames for question-answering functions. Please notice that this agent makes use of the Python agent underneath the hood to execute Python code generated by a language mannequin (LLM). Train warning when utilizing this agent to forestall potential hurt from malicious Python code generated by the LLM.
You’ll be able to initialize the Pandas DataFrame agent as follows:
from langchain_experimental.brokers.agent_toolkits import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.brokers.agent_types import AgentType
from langchain.llms import OpenAI
import pandas as pd
df = pd.read_csv("titanic.csv")
# Utilizing ZERO_SHOT_REACT_DESCRIPTION agent sort
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True)
# Alternatively, utilizing OPENAI_FUNCTIONS agent sort
# agent = create_pandas_dataframe_agent(
# ChatOpenAI(temperature=0, mannequin="gpt-3.5-turbo-0613"),
# df,
# verbose=True,
# agent_type=AgentType.OPENAI_FUNCTIONS,
# )
You’ll be able to ask the agent to rely the variety of rows within the DataFrame:
agent.run("what number of rows are there?")
The agent will execute the code df.form[0] and supply the reply, reminiscent of “There are 891 rows within the dataframe.”
You too can ask the agent to filter rows based mostly on particular standards, reminiscent of discovering the variety of folks with greater than 3 siblings:
agent.run("how many individuals have greater than 3 siblings")
The agent will execute the code df[df['SibSp'] > 3].form[0] and supply the reply, reminiscent of “30 folks have greater than 3 siblings.”
If you wish to calculate the sq. root of the typical age, you may ask the agent:
agent.run("whats the sq. root of the typical age?")
The agent will calculate the typical age utilizing df['Age'].imply() after which calculate the sq. root utilizing math.sqrt(). It would present the reply, reminiscent of “The sq. root of the typical age is 5.449689683556195.”
Let’s create a replica of the DataFrame, and lacking age values are crammed with the imply age:
df1 = df.copy()
df1["Age"] = df1["Age"].fillna(df1["Age"].imply())
Then, you may initialize the agent with each DataFrames and ask it a query:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), [df, df1], verbose=True)
agent.run("what number of rows within the age column are completely different?")
The agent will evaluate the age columns in each DataFrames and supply the reply, reminiscent of “177 rows within the age column are completely different.”
Jira Toolkit
This part explains learn how to use the Jira toolkit, which permits brokers to work together with a Jira occasion. You’ll be able to carry out numerous actions reminiscent of trying to find points and creating points utilizing this toolkit. It makes use of the atlassian-python-api library. To make use of this toolkit, it’s essential to set surroundings variables on your Jira occasion, together with JIRA_API_TOKEN, JIRA_USERNAME, and JIRA_INSTANCE_URL. Moreover, you might must set your OpenAI API key as an surroundings variable.
To get began, set up the atlassian-python-api library and set the required surroundings variables:
%pip set up atlassian-python-api
import os
from langchain.brokers import AgentType
from langchain.brokers import initialize_agent
from langchain.brokers.agent_toolkits.jira.toolkit import JiraToolkit
from langchain.llms import OpenAI
from langchain.utilities.jira import JiraAPIWrapper
os.environ["JIRA_API_TOKEN"] = "abc"
os.environ["JIRA_USERNAME"] = "123"
os.environ["JIRA_INSTANCE_URL"] = "https://jira.atlassian.com"
os.environ["OPENAI_API_KEY"] = "xyz"
llm = OpenAI(temperature=0)
jira = JiraAPIWrapper()
toolkit = JiraToolkit.from_jira_api_wrapper(jira)
agent = initialize_agent(
toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
You’ll be able to instruct the agent to create a brand new subject in a selected undertaking with a abstract and outline:
agent.run("make a brand new subject in undertaking PW to remind me to make extra fried rice")
The agent will execute the required actions to create the difficulty and supply a response, reminiscent of “A brand new subject has been created in undertaking PW with the abstract ‘Make extra fried rice’ and outline ‘Reminder to make extra fried rice’.”
This lets you work together together with your Jira occasion utilizing pure language directions and the Jira toolkit.
Automate guide duties and workflows with our AI-driven workflow builder, designed by Nanonets for you and your groups.
Module IV : Chains
LangChain is a instrument designed for using Massive Language Fashions (LLMs) in complicated purposes. It offers frameworks for creating chains of parts, together with LLMs and different varieties of parts. Two main frameworks
- The LangChain Expression Language (LCEL)
- Legacy Chain interface
The LangChain Expression Language (LCEL) is a syntax that enables for intuitive composition of chains. It helps superior options like streaming, asynchronous calls, batching, parallelization, retries, fallbacks, and tracing. For instance, you may compose a immediate, mannequin, and output parser in LCEL as proven within the following code:
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
mannequin = ChatOpenAI(mannequin="gpt-3.5-turbo", temperature=0)
immediate = ChatPromptTemplate.from_messages([
("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."),
("human", "{question}")
])
runnable = immediate | mannequin | StrOutputParser()
for chunk in runnable.stream({"query": "What are the seven wonders of the world"}):
print(chunk, finish="", flush=True)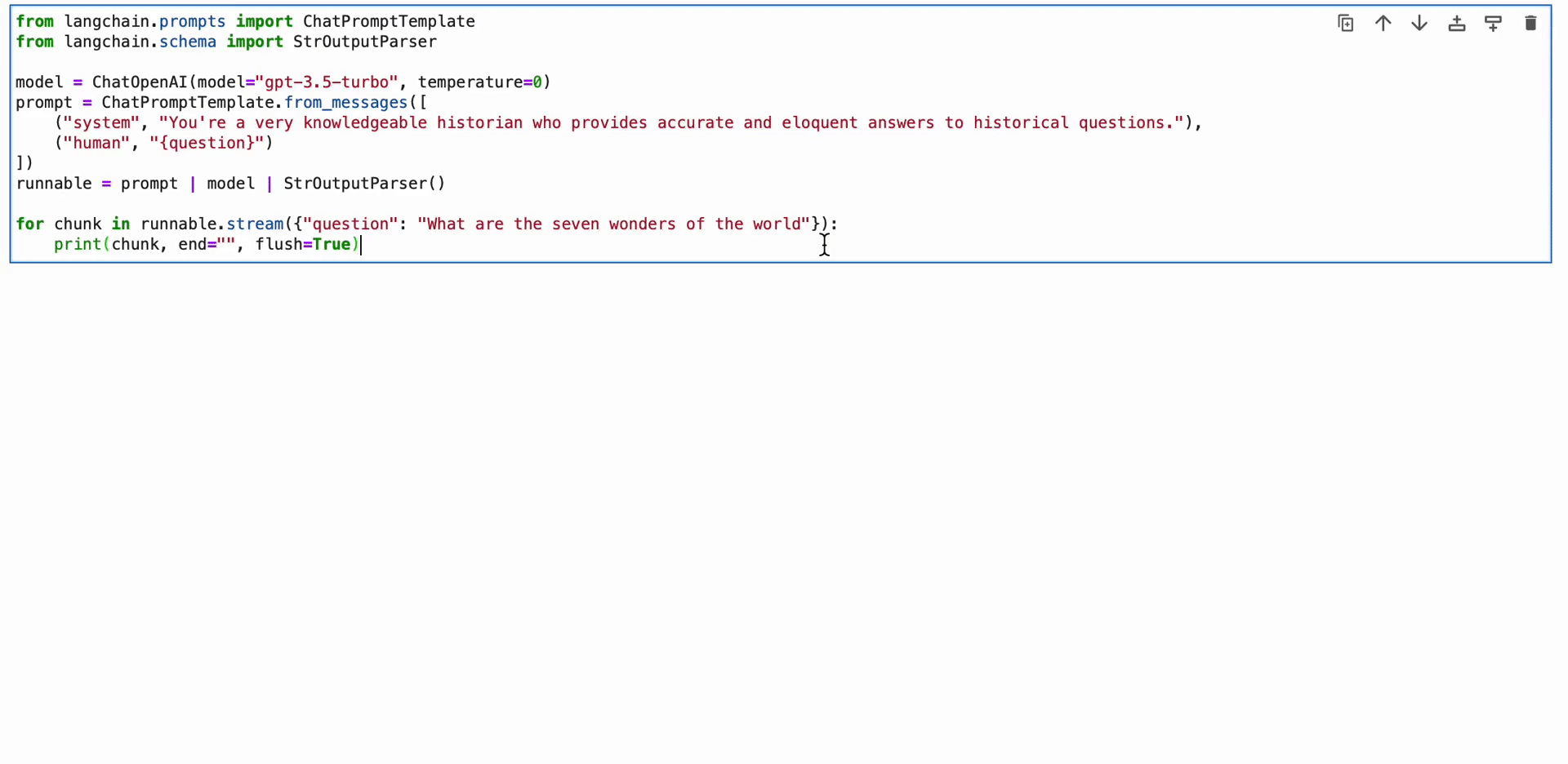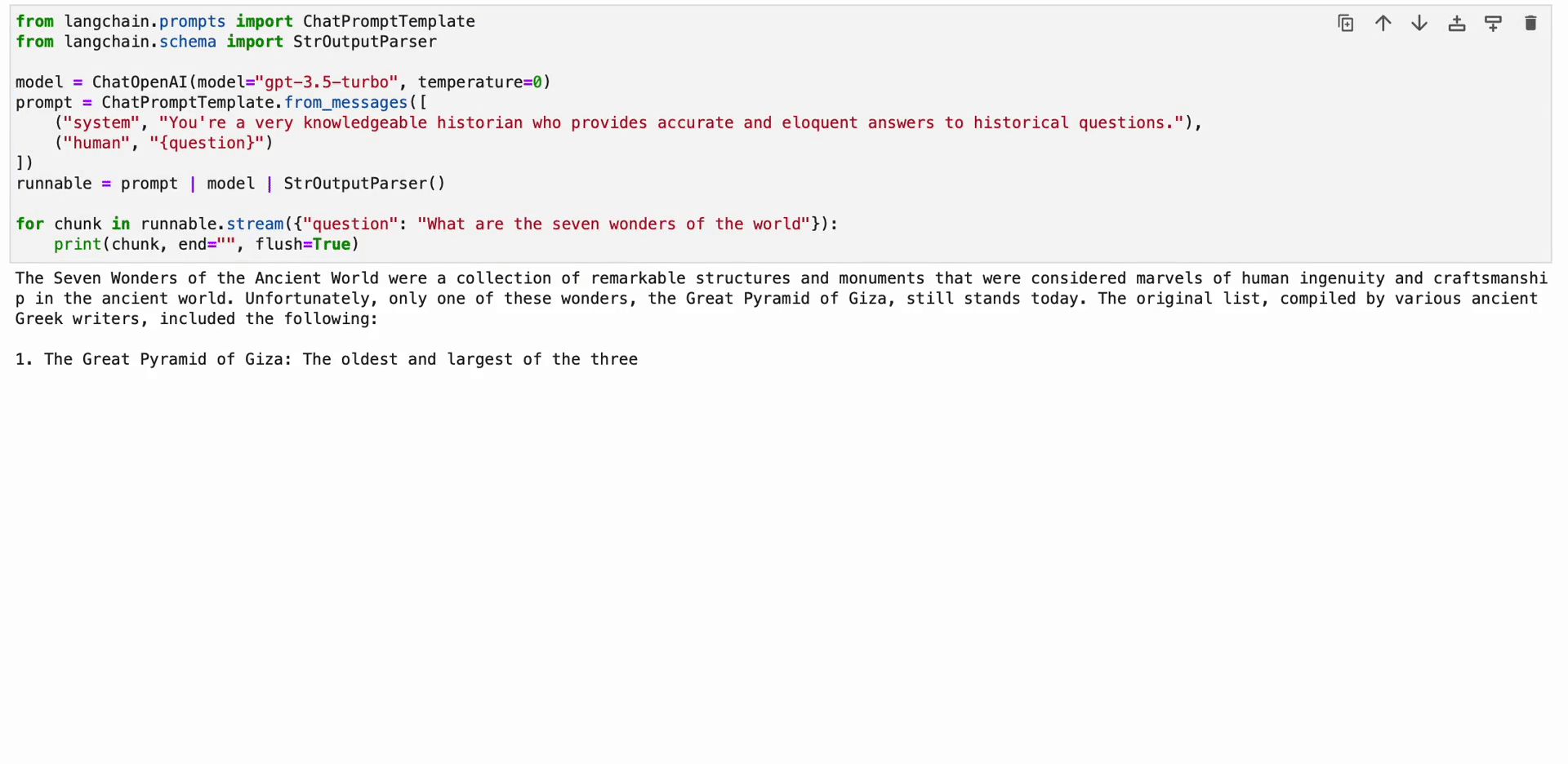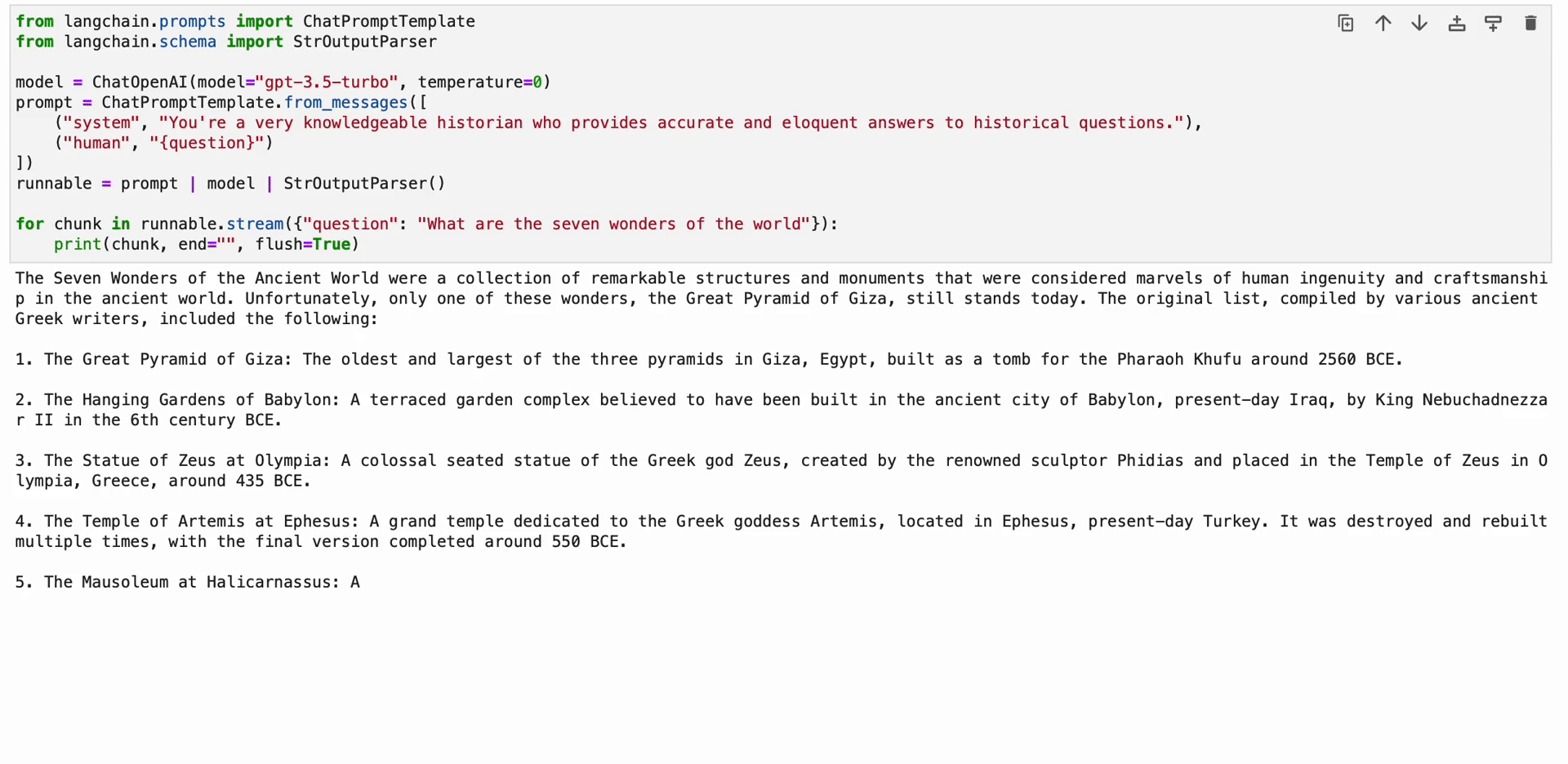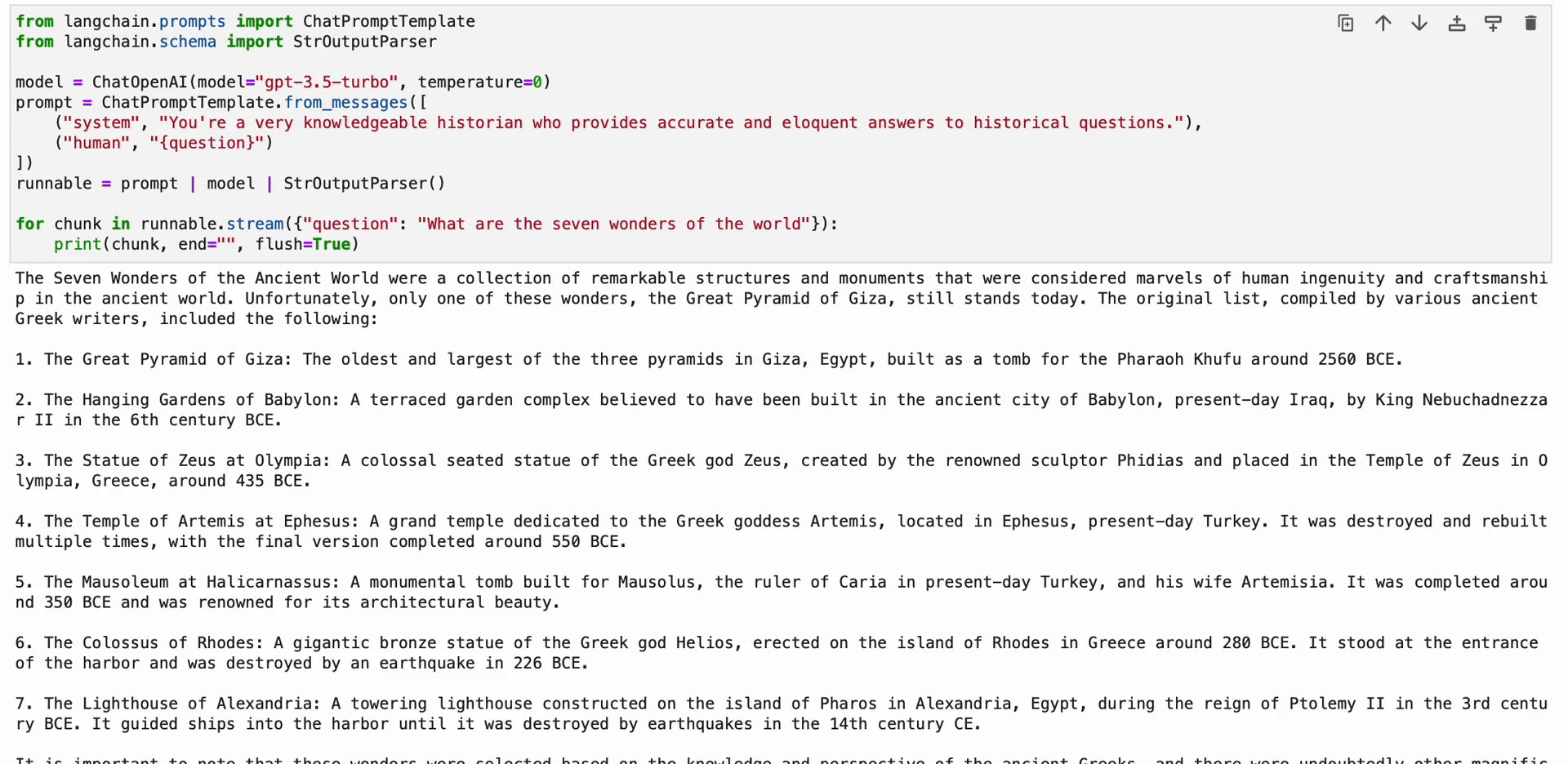
Alternatively, the LLMChain is an possibility just like LCEL for composing parts. The LLMChain instance is as follows:
from langchain.chains import LLMChain
chain = LLMChain(llm=mannequin, immediate=immediate, output_parser=StrOutputParser())
chain.run(query="What are the seven wonders of the world")
Chains in LangChain will also be stateful by incorporating a Reminiscence object. This enables for knowledge persistence throughout calls, as proven on this instance:
from langchain.chains import ConversationChain
from langchain.reminiscence import ConversationBufferMemory
dialog = ConversationChain(llm=chat, reminiscence=ConversationBufferMemory())
dialog.run("Reply briefly. What are the primary 3 colours of a rainbow?")
dialog.run("And the following 4?")
LangChain additionally helps integration with OpenAI’s function-calling APIs, which is helpful for acquiring structured outputs and executing features inside a series. For getting structured outputs, you may specify them utilizing Pydantic courses or JsonSchema, as illustrated under:
from langchain.pydantic_v1 import BaseModel, Subject
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
class Particular person(BaseModel):
title: str = Subject(..., description="The individual's title")
age: int = Subject(..., description="The individual's age")
fav_food: Optionally available[str] = Subject(None, description="The individual's favourite meals")
llm = ChatOpenAI(mannequin="gpt-4", temperature=0)
immediate = ChatPromptTemplate.from_messages([
# Prompt messages here
])
runnable = create_structured_output_runnable(Particular person, llm, immediate)
runnable.invoke({"enter": "Sally is 13"})
For structured outputs, a legacy method utilizing LLMChain can be out there:
from langchain.chains.openai_functions import create_structured_output_chain
class Particular person(BaseModel):
title: str = Subject(..., description="The individual's title")
age: int = Subject(..., description="The individual's age")
chain = create_structured_output_chain(Particular person, llm, immediate, verbose=True)
chain.run("Sally is 13")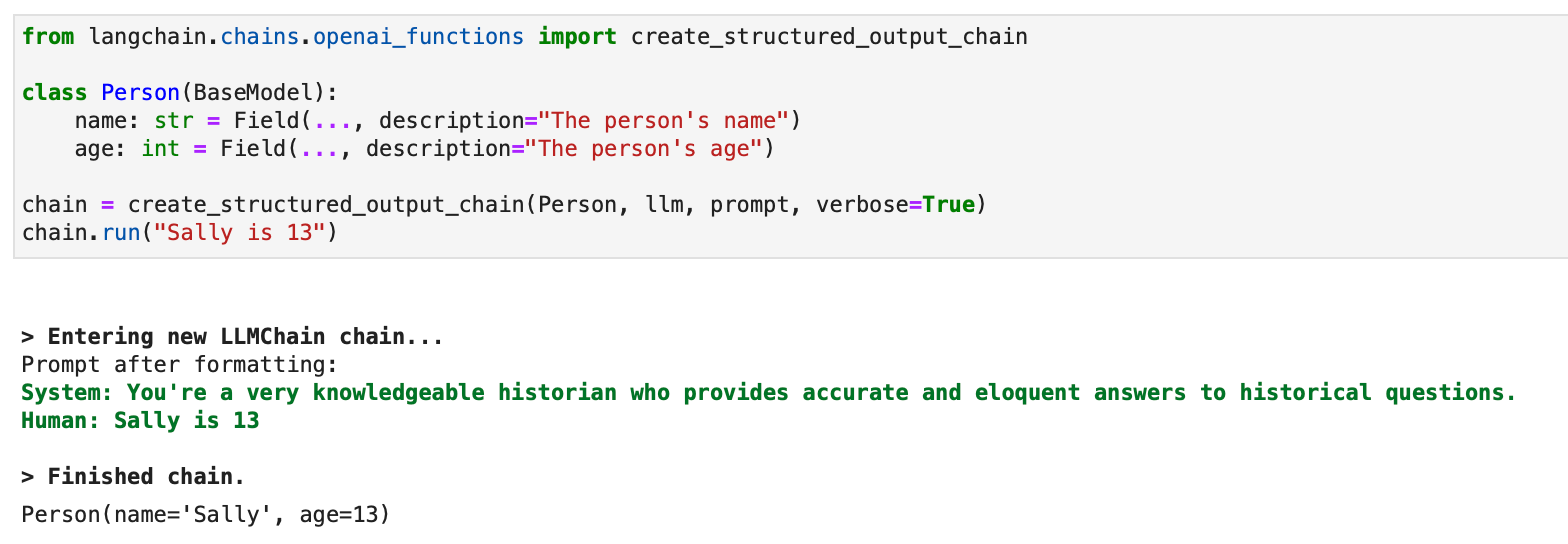
LangChain leverages OpenAI features to create numerous particular chains for various functions. These embody chains for extraction, tagging, OpenAPI, and QA with citations.
Within the context of extraction, the method is just like the structured output chain however focuses on info or entity extraction. For tagging, the concept is to label a doc with courses reminiscent of sentiment, language, model, lined matters, or political tendency.
An instance of how tagging works in LangChain could be demonstrated with a Python code. The method begins with putting in the required packages and establishing the surroundings:
pip set up langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv()
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic
The schema for tagging is outlined, specifying the properties and their anticipated sorts:
schema = {
"properties": {
"sentiment": {"sort": "string"},
"aggressiveness": {"sort": "integer"},
"language": {"sort": "string"},
}
}
llm = ChatOpenAI(temperature=0, mannequin="gpt-3.5-turbo-0613")
chain = create_tagging_chain(schema, llm)
Examples of working the tagging chain with completely different inputs present the mannequin’s capability to interpret sentiments, languages, and aggressiveness:
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.run(inp)
# {'sentiment': 'constructive', 'language': 'Spanish'}
inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.run(inp)
# {'sentiment': 'enojado', 'aggressiveness': 1, 'language': 'es'}
For finer management, the schema could be outlined extra particularly, together with potential values, descriptions, and required properties. An instance of this enhanced management is proven under:
schema = {
"properties": {
# Schema definitions right here
},
"required": ["language", "sentiment", "aggressiveness"],
}
chain = create_tagging_chain(schema, llm)
Pydantic schemas will also be used for outlining tagging standards, offering a Pythonic approach to specify required properties and kinds:
from enum import Enum
from pydantic import BaseModel, Subject
class Tags(BaseModel):
# Class fields right here
chain = create_tagging_chain_pydantic(Tags, llm)
Moreover, LangChain’s metadata tagger doc transformer can be utilized to extract metadata from LangChain Paperwork, providing comparable performance to the tagging chain however utilized to a LangChain Doc.
Citing retrieval sources is one other characteristic of LangChain, utilizing OpenAI features to extract citations from textual content. That is demonstrated within the following code:
from langchain.chains import create_citation_fuzzy_match_chain
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0, mannequin="gpt-3.5-turbo-0613")
chain = create_citation_fuzzy_match_chain(llm)
# Additional code for working the chain and displaying outcomes
In LangChain, chaining in Massive Language Mannequin (LLM) purposes usually entails combining a immediate template with an LLM and optionally an output parser. The advisable method to do that is thru the LangChain Expression Language (LCEL), though the legacy LLMChain method can be supported.
Utilizing LCEL, the BasePromptTemplate, BaseLanguageModel, and BaseOutputParser all implement the Runnable interface and could be simply piped into each other. Here is an instance demonstrating this:
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser
immediate = PromptTemplate.from_template(
"What is an efficient title for a corporation that makes {product}?"
)
runnable = immediate | ChatOpenAI() | StrOutputParser()
runnable.invoke({"product": "colourful socks"})
# Output: 'VibrantSocks'
Routing in LangChain permits for creating non-deterministic chains the place the output of a earlier step determines the following step. This helps in structuring and sustaining consistency in interactions with LLMs. As an illustration, in case you have two templates optimized for various kinds of questions, you may select the template based mostly on person enter.
Here is how one can obtain this utilizing LCEL with a RunnableBranch, which is initialized with a listing of (situation, runnable) pairs and a default runnable:
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableBranch
# Code for outlining physics_prompt and math_prompt
general_prompt = PromptTemplate.from_template(
"You're a useful assistant. Reply the query as precisely as you may.nn{enter}"
)
prompt_branch = RunnableBranch(
(lambda x: x["topic"] == "math", math_prompt),
(lambda x: x["topic"] == "physics", physics_prompt),
general_prompt,
)
# Extra code for establishing the classifier and last chain
The ultimate chain is then constructed utilizing numerous parts, reminiscent of a subject classifier, immediate department, and an output parser, to find out the movement based mostly on the subject of the enter:
from operator import itemgetter
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
final_chain = (
RunnablePassthrough.assign(matter=itemgetter("enter") | classifier_chain)
| prompt_branch
| ChatOpenAI()
| StrOutputParser()
)
final_chain.invoke(
{
"enter": "What's the first prime quantity better than 40 such that one plus the prime quantity is divisible by 3?"
}
)
# Output: Detailed reply to the maths query
This method exemplifies the pliability and energy of LangChain in dealing with complicated queries and routing them appropriately based mostly on the enter.
Within the realm of language fashions, a standard apply is to observe up an preliminary name with a sequence of subsequent calls, utilizing the output of 1 name as enter for the following. This sequential method is particularly useful whenever you wish to construct on the data generated in earlier interactions. Whereas the LangChain Expression Language (LCEL) is the advisable methodology for creating these sequences, the SequentialChain methodology remains to be documented for its backward compatibility.
As an instance this, let’s contemplate a state of affairs the place we first generate a play synopsis after which a assessment based mostly on that synopsis. Utilizing Python’s langchain.prompts, we create two PromptTemplate cases: one for the synopsis and one other for the assessment. Here is the code to arrange these templates:
from langchain.prompts import PromptTemplate
synopsis_prompt = PromptTemplate.from_template(
"You're a playwright. Given the title of play, it's your job to write down a synopsis for that title.nnTitle: {title}nPlaywright: This can be a synopsis for the above play:"
)
review_prompt = PromptTemplate.from_template(
"You're a play critic from the New York Instances. Given the synopsis of play, it's your job to write down a assessment for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Instances play critic of the above play:"
)
Within the LCEL method, we chain these prompts with ChatOpenAI and StrOutputParser to create a sequence that first generates a synopsis after which a assessment. The code snippet is as follows:
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser
llm = ChatOpenAI()
chain = (
llm
| review_prompt
| llm
| StrOutputParser()
)
chain.invoke({"title": "Tragedy at sundown on the seaside"})
If we want each the synopsis and the assessment, we will use RunnablePassthrough to create a separate chain for every after which mix them:
from langchain.schema.runnable import RunnablePassthrough
synopsis_chain = synopsis_prompt | llm | StrOutputParser()
review_chain = review_prompt | llm | StrOutputParser()
chain = {"synopsis": synopsis_chain} | RunnablePassthrough.assign(assessment=review_chain)
chain.invoke({"title": "Tragedy at sundown on the seaside"})
For situations involving extra complicated sequences, the SequentialChain methodology comes into play. This enables for a number of inputs and outputs. Contemplate a case the place we want a synopsis based mostly on a play’s title and period. Here is how we would set it up:
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.7)
synopsis_template = "You're a playwright. Given the title of play and the period it's set in, it's your job to write down a synopsis for that title.nnTitle: {title}nEra: {period}nPlaywright: This can be a synopsis for the above play:"
synopsis_prompt_template = PromptTemplate(input_variables=["title", "era"], template=synopsis_template)
synopsis_chain = LLMChain(llm=llm, immediate=synopsis_prompt_template, output_key="synopsis")
review_template = "You're a play critic from the New York Instances. Given the synopsis of play, it's your job to write down a assessment for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Instances play critic of the above play:"
prompt_template = PromptTemplate(input_variables=["synopsis"], template=review_template)
review_chain = LLMChain(llm=llm, immediate=prompt_template, output_key="assessment")
overall_chain = SequentialChain(
chains=[synopsis_chain, review_chain],
input_variables=["era", "title"],
output_variables=["synopsis", "review"],
verbose=True,
)
overall_chain({"title": "Tragedy at sundown on the seaside", "period": "Victorian England"})
In situations the place you wish to keep context all through a series or for a later a part of the chain, SimpleMemory can be utilized. That is notably helpful for managing complicated enter/output relationships. As an illustration, in a state of affairs the place we wish to generate social media posts based mostly on a play’s title, period, synopsis, and assessment, SimpleMemory will help handle these variables:
from langchain.reminiscence import SimpleMemory
from langchain.chains import SequentialChain
template = "You're a social media supervisor for a theater firm. Given the title of play, the period it's set in, the date, time and placement, the synopsis of the play, and the assessment of the play,
it's your job to write down a social media publish for that play.nnHere is a few context concerning the time and placement of the play:nDate and Time: {time}nLocation: {location}nnPlay Synopsis:n{synopsis}nReview from a New York Instances play critic of the above play:n{assessment}nnSocial Media Put up:"
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, immediate=prompt_template, output_key="social_post_text")
overall_chain = SequentialChain(
reminiscence=SimpleMemory(recollections={"time": "December twenty fifth, 8pm PST", "location": "Theater within the Park"}),
chains=[synopsis_chain, review_chain, social_chain],
input_variables=["era", "title"],
output_variables=["social_post_text"],
verbose=True,
)
overall_chain({"title": "Tragedy at sundown on the seaside", "period": "Victorian England"})
Along with sequential chains, there are specialised chains for working with paperwork. Every of those chains serves a special objective, from combining paperwork to refining solutions based mostly on iterative doc evaluation, to mapping and lowering doc content material for summarization or re-ranking based mostly on scored responses. These chains could be recreated with LCEL for added flexibility and customization.
-
StuffDocumentsChaincombines a listing of paperwork right into a single immediate handed to an LLM. -
RefineDocumentsChainupdates its reply iteratively for every doc, appropriate for duties the place paperwork exceed the mannequin’s context capability. -
MapReduceDocumentsChainapplies a series to every doc individually after which combines the outcomes. -
MapRerankDocumentsChainscores every document-based response and selects the highest-scoring one.
Here is an instance of the way you may arrange a MapReduceDocumentsChain utilizing LCEL:
from functools import partial
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.schema import Doc, StrOutputParser
from langchain.schema.prompt_template import format_document
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough
llm = ChatAnthropic()
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, immediate=document_prompt)
map_chain = (
{"context": partial_format_document}
| PromptTemplate.from_template("Summarize this content material:nn{context}")
| llm
| StrOutputParser()
)
map_as_doc_chain = (
RunnableParallel({"doc": RunnablePassthrough(), "content material": map_chain})
| (lambda x: Doc(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)")
def format_docs(docs):
return "nn".be a part of(partial_format_document(doc) for doc in docs)
collapse_chain = (
{"context": format_docs}
| PromptTemplate.from_template("Collapse this content material:nn{context}")
| llm
| StrOutputParser()
)
reduce_chain = (
{"context": format_docs}
| PromptTemplate.from_template("Mix these summaries:nn{context}")
| llm
| StrOutputParser()
).with_config(run_name="Scale back")
map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(run_name="Map cut back")
This configuration permits for an in depth and complete evaluation of doc content material, leveraging the strengths of LCEL and the underlying language mannequin.
Automate guide duties and workflows with our AI-driven workflow builder, designed by Nanonets for you and your groups.
Module V : Reminiscence
In LangChain, reminiscence is a elementary facet of conversational interfaces, permitting techniques to reference previous interactions. That is achieved by way of storing and querying info, with two main actions: studying and writing. The reminiscence system interacts with a series twice throughout a run, augmenting person inputs and storing the inputs and outputs for future reference.
Constructing Reminiscence right into a System
- Storing Chat Messages: The LangChain reminiscence module integrates numerous strategies to retailer chat messages, starting from in-memory lists to databases. This ensures that every one chat interactions are recorded for future reference.
- Querying Chat Messages: Past storing chat messages, LangChain employs knowledge constructions and algorithms to create a helpful view of those messages. Easy reminiscence techniques may return current messages, whereas extra superior techniques might summarize previous interactions or deal with entities talked about within the present interplay.
To display using reminiscence in LangChain, contemplate the ConversationBufferMemory class, a easy reminiscence kind that shops chat messages in a buffer. Here is an instance:
from langchain.reminiscence import ConversationBufferMemory
reminiscence = ConversationBufferMemory()
reminiscence.chat_memory.add_user_message("Hiya!")
reminiscence.chat_memory.add_ai_message("How can I help you?")
When integrating reminiscence into a series, it is essential to know the variables returned from reminiscence and the way they’re used within the chain. As an illustration, the load_memory_variables methodology helps align the variables learn from reminiscence with the chain’s expectations.
Finish-to-Finish Instance with LangChain
Think about using ConversationBufferMemory in an LLMChain. The chain, mixed with an applicable immediate template and the reminiscence, offers a seamless conversational expertise. Here is a simplified instance:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.reminiscence import ConversationBufferMemory
llm = OpenAI(temperature=0)
template = "Your dialog template right here..."
immediate = PromptTemplate.from_template(template)
reminiscence = ConversationBufferMemory(memory_key="chat_history")
dialog = LLMChain(llm=llm, immediate=immediate, reminiscence=reminiscence)
response = dialog({"query": "What is the climate like?"})
This instance illustrates how LangChain’s reminiscence system integrates with its chains to supply a coherent and contextually conscious conversational expertise.
Reminiscence Sorts in Langchain
Langchain affords numerous reminiscence sorts that may be utilized to boost interactions with the AI fashions. Every reminiscence sort has its personal parameters and return sorts, making them appropriate for various situations. Let’s discover among the reminiscence sorts out there in Langchain together with code examples.
1. Dialog Buffer Reminiscence
This reminiscence sort lets you retailer and extract messages from conversations. You’ll be able to extract the historical past as a string or as a listing of messages.
from langchain.reminiscence import ConversationBufferMemory
reminiscence = ConversationBufferMemory()
reminiscence.save_context({"enter": "hello"}, {"output": "whats up"})
reminiscence.load_memory_variables({})
# Extract historical past as a string
{'historical past': 'Human: hinAI: whats up'}
# Extract historical past as a listing of messages
{'historical past': [HumanMessage(content="hi", additional_kwargs={}),
AIMessage(content="whats up", additional_kwargs={})]}
You too can use Dialog Buffer Reminiscence in a series for chat-like interactions.
2. Dialog Buffer Window Reminiscence
This reminiscence sort retains a listing of current interactions and makes use of the final Okay interactions, stopping the buffer from getting too massive.
from langchain.reminiscence import ConversationBufferWindowMemory
reminiscence = ConversationBufferWindowMemory(ok=1)
reminiscence.save_context({"enter": "hello"}, {"output": "whats up"})
reminiscence.save_context({"enter": "not a lot you"}, {"output": "not a lot"})
reminiscence.load_memory_variables({})
{'historical past': 'Human: not a lot younAI: not a lot'}
Like Dialog Buffer Reminiscence, you may as well use this reminiscence sort in a series for chat-like interactions.
3. Dialog Entity Reminiscence
This reminiscence sort remembers information about particular entities in a dialog and extracts info utilizing an LLM.
from langchain.reminiscence import ConversationEntityMemory
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
reminiscence = ConversationEntityMemory(llm=llm)
_input = {"enter": "Deven & Sam are engaged on a hackathon undertaking"}
reminiscence.load_memory_variables(_input)
reminiscence.save_context(
_input,
{"output": " That feels like an ideal undertaking! What sort of undertaking are they engaged on?"}
)
reminiscence.load_memory_variables({"enter": 'who's Sam'})
{'historical past': 'Human: Deven & Sam are engaged on a hackathon projectnAI: That feels like an ideal undertaking! What sort of undertaking are they engaged on?',
'entities': {'Sam': 'Sam is engaged on a hackathon undertaking with Deven.'}}
4. Dialog Information Graph Reminiscence
This reminiscence sort makes use of a information graph to recreate reminiscence. You’ll be able to extract present entities and information triplets from messages.
from langchain.reminiscence import ConversationKGMemory
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
reminiscence = ConversationKGMemory(llm=llm)
reminiscence.save_context({"enter": "say hello to sam"}, {"output": "who's sam"})
reminiscence.save_context({"enter": "sam is a buddy"}, {"output": "okay"})
reminiscence.load_memory_variables({"enter": "who's sam"})
{'historical past': 'On Sam: Sam is buddy.'}
You too can use this reminiscence sort in a series for conversation-based information retrieval.
5. Dialog Abstract Reminiscence
This reminiscence sort creates a abstract of the dialog over time, helpful for condensing info from longer conversations.
from langchain.reminiscence import ConversationSummaryMemory
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
reminiscence = ConversationSummaryMemory(llm=llm)
reminiscence.save_context({"enter": "hello"}, {"output": "whats up"})
reminiscence.load_memory_variables({})
{'historical past': 'nThe human greets the AI, to which the AI responds.'}
6. Dialog Abstract Buffer Reminiscence
This reminiscence sort combines the dialog abstract and buffer, sustaining a steadiness between current interactions and a abstract. It makes use of token size to find out when to flush interactions.
from langchain.reminiscence import ConversationSummaryBufferMemory
from langchain.llms import OpenAI
llm = OpenAI()
reminiscence = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
reminiscence.save_context({"enter": "hello"}, {"output": "whats up"})
reminiscence.save_context({"enter": "not a lot you"}, {"output": "not a lot"})
reminiscence.load_memory_variables({})
{'historical past': 'System: nThe human says "hello", and the AI responds with "whats up".nHuman: not a lot younAI: not a lot'}
You should utilize these reminiscence sorts to boost your interactions with AI fashions in Langchain. Every reminiscence sort serves a selected objective and could be chosen based mostly in your necessities.
7. Dialog Token Buffer Reminiscence
ConversationTokenBufferMemory is one other reminiscence sort that retains a buffer of current interactions in reminiscence. In contrast to the earlier reminiscence sorts that target the variety of interactions, this one makes use of token size to find out when to flush interactions.
Utilizing reminiscence with LLM:
from langchain.reminiscence import ConversationTokenBufferMemory
from langchain.llms import OpenAI
llm = OpenAI()
reminiscence = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
reminiscence.save_context({"enter": "hello"}, {"output": "whats up"})
reminiscence.save_context({"enter": "not a lot you"}, {"output": "not a lot"})
reminiscence.load_memory_variables({})
{'historical past': 'Human: not a lot younAI: not a lot'}
On this instance, the reminiscence is ready to restrict interactions based mostly on token size fairly than the variety of interactions.
You too can get the historical past as a listing of messages when utilizing this reminiscence sort.
reminiscence = ConversationTokenBufferMemory(
llm=llm, max_token_limit=10, return_messages=True
)
reminiscence.save_context({"enter": "hello"}, {"output": "whats up"})
reminiscence.save_context({"enter": "not a lot you"}, {"output": "not a lot"})
Utilizing in a series:
You should utilize ConversationTokenBufferMemory in a series to boost interactions with the AI mannequin.
from langchain.chains import ConversationChain
conversation_with_summary = ConversationChain(
llm=llm,
# We set a really low max_token_limit for the needs of testing.
reminiscence=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60),
verbose=True,
)
conversation_with_summary.predict(enter="Hello, what's up?")
On this instance, ConversationTokenBufferMemory is utilized in a ConversationChain to handle the dialog and restrict interactions based mostly on token size.
8. VectorStoreRetrieverMemory
VectorStoreRetrieverMemory shops recollections in a vector retailer and queries the top-Okay most “salient” paperwork each time it’s referred to as. This reminiscence sort does not explicitly monitor the order of interactions however makes use of vector retrieval to fetch related recollections.
from datetime import datetime
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.reminiscence import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
# Initialize your vector retailer (specifics rely upon the chosen vector retailer)
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS
embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {})
# Create your VectorStoreRetrieverMemory
retriever = vectorstore.as_retriever(search_kwargs=dict(ok=1))
reminiscence = VectorStoreRetrieverMemory(retriever=retriever)
# Save context and related info to the reminiscence
reminiscence.save_context({"enter": "My favourite meals is pizza"}, {"output": "that is good to know"})
reminiscence.save_context({"enter": "My favourite sport is soccer"}, {"output": "..."})
reminiscence.save_context({"enter": "I do not just like the Celtics"}, {"output": "okay"})
# Retrieve related info from reminiscence based mostly on a question
print(reminiscence.load_memory_variables({"immediate": "what sport ought to i watch?"})["history"])
On this instance, VectorStoreRetrieverMemory is used to retailer and retrieve related info from a dialog based mostly on vector retrieval.
You too can use VectorStoreRetrieverMemory in a series for conversation-based information retrieval, as proven within the earlier examples.
These completely different reminiscence sorts in Langchain present numerous methods to handle and retrieve info from conversations, enhancing the capabilities of AI fashions in understanding and responding to person queries and context. Every reminiscence sort could be chosen based mostly on the particular necessities of your software.
Now we’ll discover ways to use reminiscence with an LLMChain. Reminiscence in an LLMChain permits the mannequin to recollect earlier interactions and context to supply extra coherent and context-aware responses.
To arrange reminiscence in an LLMChain, it’s essential to create a reminiscence class, reminiscent of ConversationBufferMemory. Here is how one can set it up:
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.reminiscence import ConversationBufferMemory
from langchain.prompts import PromptTemplate
template = """You're a chatbot having a dialog with a human.
{chat_history}
Human: {human_input}
Chatbot:"""
immediate = PromptTemplate(
input_variables=["chat_history", "human_input"], template=template
)
reminiscence = ConversationBufferMemory(memory_key="chat_history")
llm = OpenAI()
llm_chain = LLMChain(
llm=llm,
immediate=immediate,
verbose=True,
reminiscence=reminiscence,
)
llm_chain.predict(human_input="Hello there my buddy")
On this instance, the ConversationBufferMemory is used to retailer the dialog historical past. The memory_key parameter specifies the important thing used to retailer the dialog historical past.
If you’re utilizing a chat mannequin as a substitute of a completion-style mannequin, you may construction your prompts in a different way to raised make the most of the reminiscence. Here is an instance of learn how to arrange a chat model-based LLMChain with reminiscence:
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
# Create a ChatPromptTemplate
immediate = ChatPromptTemplate.from_messages(
[
SystemMessage(
content="You are a chatbot having a conversation with a human."
), # The persistent system prompt
MessagesPlaceholder(
variable_name="chat_history"
), # Where the memory will be stored.
HumanMessagePromptTemplate.from_template(
"{human_input}"
), # Where the human input will be injected
]
)
reminiscence = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
llm = ChatOpenAI()
chat_llm_chain = LLMChain(
llm=llm,
immediate=immediate,
verbose=True,
reminiscence=reminiscence,
)
chat_llm_chain.predict(human_input="Hello there my buddy")
On this instance, the ChatPromptTemplate is used to construction the immediate, and the ConversationBufferMemory is used to retailer and retrieve the dialog historical past. This method is especially helpful for chat-style conversations the place context and historical past play an important function.
Reminiscence will also be added to a series with a number of inputs, reminiscent of a query/answering chain. Here is an instance of learn how to arrange reminiscence in a query/answering chain:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.doc import Doc
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.reminiscence import ConversationBufferMemory
# Break up an extended doc into smaller chunks
with open("../../state_of_the_union.txt") as f:
state_of_the_union = f.learn()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
# Create an ElasticVectorSearch occasion to index and search the doc chunks
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(
texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
)
# Carry out a query concerning the doc
question = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(question)
# Arrange a immediate for the question-answering chain with reminiscence
template = """You're a chatbot having a dialog with a human.
Given the next extracted components of an extended doc and a query, create a last reply.
{context}
{chat_history}
Human: {human_input}
Chatbot:"""
immediate = PromptTemplate(
input_variables=["chat_history", "human_input", "context"], template=template
)
reminiscence = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain(
OpenAI(temperature=0), chain_type="stuff", reminiscence=reminiscence, immediate=immediate
)
# Ask the query and retrieve the reply
question = "What did the president say about Justice Breyer"
outcome = chain({"input_documents": docs, "human_input": question}, return_only_outputs=True)
print(outcome)
print(chain.reminiscence.buffer)
On this instance, a query is answered utilizing a doc cut up into smaller chunks. The ConversationBufferMemory is used to retailer and retrieve the dialog historical past, permitting the mannequin to supply context-aware solutions.
Including reminiscence to an agent permits it to recollect and use earlier interactions to reply questions and supply context-aware responses. Here is how one can arrange reminiscence in an agent:
from langchain.brokers import ZeroShotAgent, Instrument, AgentExecutor
from langchain.reminiscence import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.utilities import GoogleSearchAPIWrapper
# Create a instrument for looking
search = GoogleSearchAPIWrapper()
instruments = [
Tool(
name="Search",
func=search.run,
description="useful for when you need to answer questions about current events",
)
]
# Create a immediate with reminiscence
prefix = """Have a dialog with a human, answering the next questions as finest you may. You've entry to the next instruments:"""
suffix = """Start!"
{chat_history}
Query: {enter}
{agent_scratchpad}"""
immediate = ZeroShotAgent.create_prompt(
instruments,
prefix=prefix,
suffix=suffix,
input_variables=["input", "chat_history", "agent_scratchpad"],
)
reminiscence = ConversationBufferMemory(memory_key="chat_history")
# Create an LLMChain with reminiscence
llm_chain = LLMChain(llm=OpenAI(temperature=0), immediate=immediate)
agent = ZeroShotAgent(llm_chain=llm_chain, instruments=instruments, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools(
agent=agent, instruments=instruments, verbose=True, reminiscence=reminiscence
)
# Ask a query and retrieve the reply
response = agent_chain.run(enter="How many individuals dwell
in Canada?")
print(response)
# Ask a follow-up query
response = agent_chain.run(enter="What's their nationwide anthem referred to as?")
print(response)
On this instance, reminiscence is added to an agent, permitting it to recollect the earlier dialog historical past and supply context-aware solutions. This allows the agent to reply follow-up questions precisely based mostly on the data saved in reminiscence.
LangChain Expression Language
On this planet of pure language processing and machine studying, composing complicated chains of operations could be a daunting process. Luckily, LangChain Expression Language (LCEL) involves the rescue, offering a declarative and environment friendly approach to construct and deploy refined language processing pipelines. LCEL is designed to simplify the method of composing chains, making it potential to go from prototyping to manufacturing with ease. On this weblog, we’ll discover what LCEL is and why you may wish to use it, together with sensible code examples as an example its capabilities.
LCEL, or LangChain Expression Language, is a strong instrument for composing language processing chains. It was purpose-built to assist the transition from prototyping to manufacturing seamlessly, with out requiring in depth code modifications. Whether or not you are constructing a easy “immediate + LLM” chain or a fancy pipeline with a whole lot of steps, LCEL has you lined.
Listed here are some causes to make use of LCEL in your language processing tasks:
- Quick Token Streaming: LCEL delivers tokens from a Language Mannequin to an output parser in real-time, enhancing responsiveness and effectivity.
- Versatile APIs: LCEL helps each synchronous and asynchronous APIs for prototyping and manufacturing use, dealing with a number of requests effectively.
- Automated Parallelization: LCEL optimizes parallel execution when potential, lowering latency in each sync and async interfaces.
- Dependable Configurations: Configure retries and fallbacks for enhanced chain reliability at scale, with streaming assist in growth.
- Stream Intermediate Outcomes: Entry intermediate outcomes throughout processing for person updates or debugging functions.
- Schema Technology: LCEL generates Pydantic and JSONSchema schemas for enter and output validation.
- Complete Tracing: LangSmith routinely traces all steps in complicated chains for observability and debugging.
- Straightforward Deployment: Deploy LCEL-created chains effortlessly utilizing LangServe.
Now, let’s dive into sensible code examples that display the ability of LCEL. We’ll discover frequent duties and situations the place LCEL shines.
Immediate + LLM
Probably the most elementary composition entails combining a immediate and a language mannequin to create a series that takes person enter, provides it to a immediate, passes it to a mannequin, and returns the uncooked mannequin output. Here is an instance:
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
immediate = ChatPromptTemplate.from_template("inform me a joke about {foo}")
mannequin = ChatOpenAI()
chain = immediate | mannequin
outcome = chain.invoke({"foo": "bears"})
print(outcome)
On this instance, the chain generates a joke about bears.
You’ll be able to connect cease sequences to your chain to manage the way it processes textual content. For instance:
chain = immediate | mannequin.bind(cease=["n"])
outcome = chain.invoke({"foo": "bears"})
print(outcome)
This configuration stops textual content technology when a newline character is encountered.
LCEL helps attaching perform name info to your chain. Here is an instance:
features = [
{
"name": "joke",
"description": "A joke",
"parameters": {
"type": "object",
"properties": {
"setup": {"type": "string", "description": "The setup for the joke"},
"punchline": {
"type": "string",
"description": "The punchline for the joke",
},
},
"required": ["setup", "punchline"],
},
}
]
chain = immediate | mannequin.bind(function_call={"title": "joke"}, features=features)
outcome = chain.invoke({"foo": "bears"}, config={})
print(outcome)
This instance attaches perform name info to generate a joke.
Immediate + LLM + OutputParser
You’ll be able to add an output parser to remodel the uncooked mannequin output right into a extra workable format. Here is how you are able to do it:
from langchain.schema.output_parser import StrOutputParser
chain = immediate | mannequin | StrOutputParser()
outcome = chain.invoke({"foo": "bears"})
print(outcome)
The output is now in a string format, which is extra handy for downstream duties.
When specifying a perform to return, you may parse it straight utilizing LCEL. For instance:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
chain = (
immediate
| mannequin.bind(function_call={"title": "joke"}, features=features)
| JsonOutputFunctionsParser()
)
outcome = chain.invoke({"foo": "bears"})
print(outcome)
This instance parses the output of the “joke” perform straight.
These are only a few examples of how LCEL simplifies complicated language processing duties. Whether or not you are constructing chatbots, producing content material, or performing complicated textual content transformations, LCEL can streamline your workflow and make your code extra maintainable.
RAG (Retrieval-augmented Technology)
LCEL can be utilized to create retrieval-augmented technology chains, which mix retrieval and language technology steps. Here is an instance:
from operator import itemgetter
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISS
# Create a vector retailer and retriever
vectorstore = FAISS.from_texts(
["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
# Outline templates for prompts
template = """Reply the query based mostly solely on the next context:
{context}
Query: {query}
"""
immediate = ChatPromptTemplate.from_template(template)
mannequin = ChatOpenAI()
# Create a retrieval-augmented technology chain
chain = (
{"context": retriever, "query": RunnablePassthrough()}
| immediate
| mannequin
| StrOutputParser()
)
outcome = chain.invoke("the place did harrison
work?")
print(outcome)
On this instance, the chain retrieves related info from the context and generates a response to the query.
Conversational Retrieval Chain
You’ll be able to simply add dialog historical past to your chains. Here is an instance of a conversational retrieval chain:
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document
from langchain.prompts.immediate import PromptTemplate
# Outline templates for prompts
_template = """Given the next dialog and a observe up query, rephrase the observe up query to be a standalone query, in its unique language.
Chat Historical past:
{chat_history}
Comply with Up Enter: {query}
Standalone query:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template)
template = """Reply the query based mostly solely on the next context:
{context}
Query: {query}
"""
ANSWER_PROMPT = ChatPromptTemplate.from_template(template)
# Outline enter map and context
_inputs = RunnableMap(
standalone_question=RunnablePassthrough.assign(
chat_history=lambda x: _format_chat_history(x["chat_history"])
)
| CONDENSE_QUESTION_PROMPT
| ChatOpenAI(temperature=0)
| StrOutputParser(),
)
_context = retriever
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI()
outcome = conversational_qa_chain.invoke(
{
"query": "the place did harrison work?",
"chat_history": [],
}
)
print(outcome)
On this instance, the chain handles a follow-up query inside a conversational context.
With Reminiscence and Returning Supply Paperwork
LCEL additionally helps reminiscence and returning supply paperwork. Here is how you should use reminiscence in a series:
from operator import itemgetter
from langchain.reminiscence import ConversationBufferMemory
# Create a reminiscence occasion
reminiscence = ConversationBufferMemory(
return_messages=True, output_key="reply", input_key="query"
)
# Outline steps for the chain
loaded_memory = RunnablePassthrough.assign(
chat_history=RunnableLambda(reminiscence.load_memory_variables) | itemgetter("historical past"),
)
standalone_question = {
"standalone_question": {
"query": lambda x: x["question"],
"chat_history": lambda x: _format_chat_history(x["chat_history"]),
}
| CONDENSE_QUESTION_PROMPT
| ChatOpenAI(temperature=0)
| StrOutputParser(),
}
retrieved_documents = retriever,
"query": lambda x: x["standalone_question"],
final_inputs = {
"context": lambda x: _combine_documents(x["docs"]),
"query": itemgetter("query"),
}
reply = ChatOpenAI(),
"docs": itemgetter("docs"),
# Create the ultimate chain by combining the steps
final_chain = loaded_memory | standalone_question | retrieved_documents | reply
inputs = {"query": "the place did harrison work?"}
outcome = final_chain.invoke(inputs)
print(outcome)
On this instance, reminiscence is used to retailer and retrieve dialog historical past and supply paperwork.
A number of Chains
You’ll be able to string collectively a number of chains utilizing Runnables. Here is an instance:
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
prompt1 = ChatPromptTemplate.from_template("what's the metropolis {individual} is from?")
prompt2 = ChatPromptTemplate.from_template(
"what nation is town {metropolis} in? reply in {language}"
)
mannequin = ChatOpenAI()
chain1 = prompt1 | mannequin | StrOutputParser()
chain2 = (
{"metropolis": chain1, "language": itemgetter("language")}
| prompt2
| mannequin
| StrOutputParser()
)
outcome = chain2.invoke({"individual": "obama", "language": "spanish"})
print(outcome)
On this instance, two chains are mixed to generate details about a metropolis and its nation in a specified language.
Branching and Merging
LCEL lets you cut up and merge chains utilizing RunnableMaps. Here is an instance of branching and merging:
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser
planner = (
ChatPromptTemplate.from_template("Generate an argument about: {enter}")
| ChatOpenAI()
| StrOutputParser()
| {"base_response": RunnablePassthrough()}
)
arguments_for = (
ChatPromptTemplate.from_template(
"Checklist the professionals or constructive features of {base_response}"
)
| ChatOpenAI()
| StrOutputParser()
)
arguments_against = (
ChatPromptTemplate.from_template(
"Checklist the cons or unfavourable features of {base_response}"
)
| ChatOpenAI()
| StrOutputParser()
)
final_responder = (
ChatPromptTemplate.from_messages(
[
("ai", "{original_response}"),
("human", "Pros:n{results_1}nnCons:n{results_2}"),
("system", "Generate a final response given the critique"),
]
)
| ChatOpenAI()
| StrOutputParser()
)
chain = (
planner
| {
"results_1": arguments_for,
"results_2": arguments_against,
"original_response": itemgetter("base_response"),
}
| final_responder
)
outcome = chain.invoke({"enter": "scrum"})
print(outcome)
On this instance, a branching and merging chain is used to generate an argument and consider its professionals and cons earlier than producing a last response.
Writing Python Code with LCEL
One of many highly effective purposes of LangChain Expression Language (LCEL) is writing Python code to resolve person issues. Under is an instance of learn how to use LCEL to write down Python code:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_experimental.utilities import PythonREPL
template = """Write some python code to resolve the person's drawback.
Return solely python code in Markdown format, e.g.:
```python
....
```"""
immediate = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")])
mannequin = ChatOpenAI()
def _sanitize_output(textual content: str):
_, after = textual content.cut up("```python")
return after.cut up("```")[0]
chain = immediate | mannequin | StrOutputParser() | _sanitize_output | PythonREPL().run
outcome = chain.invoke({"enter": "what's 2 plus 2"})
print(outcome)
On this instance, a person offers enter, and LCEL generates Python code to resolve the issue. The code is then executed utilizing a Python REPL, and the ensuing Python code is returned in Markdown format.
Please notice that utilizing a Python REPL can execute arbitrary code, so use it with warning.
Including Reminiscence to a Chain
Reminiscence is important in lots of conversational AI purposes. Here is learn how to add reminiscence to an arbitrary chain:
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.reminiscence import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
mannequin = ChatOpenAI()
immediate = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful chatbot"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
reminiscence = ConversationBufferMemory(return_messages=True)
# Initialize reminiscence
reminiscence.load_memory_variables({})
chain = (
RunnablePassthrough.assign(
historical past=RunnableLambda(reminiscence.load_memory_variables) | itemgetter("historical past")
)
| immediate
| mannequin
)
inputs = {"enter": "hello, I am Bob"}
response = chain.invoke(inputs)
response
# Save the dialog in reminiscence
reminiscence.save_context(inputs, {"output": response.content material})
# Load reminiscence to see the dialog historical past
reminiscence.load_memory_variables({})
On this instance, reminiscence is used to retailer and retrieve dialog historical past, permitting the chatbot to keep up context and reply appropriately.
Utilizing Exterior Instruments with Runnables
LCEL lets you seamlessly combine exterior instruments with Runnables. Here is an instance utilizing the DuckDuckGo Search instrument:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.instruments import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
template = """Flip the next person enter right into a search question for a search engine:
{enter}"""
immediate = ChatPromptTemplate.from_template(template)
mannequin = ChatOpenAI()
chain = immediate | mannequin | StrOutputParser() | search
search_result = chain.invoke({"enter": "I would like to determine what video games are tonight"})
print(search_result)
On this instance, LCEL integrates the DuckDuckGo Search instrument into the chain, permitting it to generate a search question from person enter and retrieve search outcomes.
LCEL’s flexibility makes it straightforward to include numerous exterior instruments and companies into your language processing pipelines, enhancing their capabilities and performance.
Including Moderation to an LLM Software
To make sure that your LLM software adheres to content material insurance policies and consists of moderation safeguards, you may combine moderation checks into your chain. Here is learn how to add moderation utilizing LangChain:
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate
average = OpenAIModerationChain()
mannequin = OpenAI()
immediate = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")])
chain = immediate | mannequin
# Authentic response with out moderation
response_without_moderation = chain.invoke({"enter": "you're silly"})
print(response_without_moderation)
moderated_chain = chain | average
# Response after moderation
response_after_moderation = moderated_chain.invoke({"enter": "you're silly"})
print(response_after_moderation)
On this instance, the OpenAIModerationChain is used so as to add moderation to the response generated by the LLM. The moderation chain checks the response for content material that violates OpenAI’s content material coverage. If any violations are discovered, it should flag the response accordingly.
Routing by Semantic Similarity
LCEL lets you implement customized routing logic based mostly on the semantic similarity of person enter. Here is an instance of learn how to dynamically decide the chain logic based mostly on person enter:
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.utils.math import cosine_similarity
physics_template = """You're a very good physics professor.
You're nice at answering questions on physics in a concise and straightforward to know method.
When you do not know the reply to a query you admit that you do not know.
Here's a query:
{question}"""
math_template = """You're a excellent mathematician. You're nice at answering math questions.
You're so good as a result of you'll be able to break down onerous issues into their part components,
reply the part components, after which put them collectively to reply the broader query.
Here's a query:
{question}"""
embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates)
def prompt_router(enter):
query_embedding = embeddings.embed_query(enter["query"])
similarity = cosine_similarity([query_embedding], prompt_embeddings)[0]
most_similar = prompt_templates[similarity.argmax()]
print("Utilizing MATH" if most_similar == math_template else "Utilizing PHYSICS")
return PromptTemplate.from_template(most_similar)
chain = (
{"question": RunnablePassthrough()}
| RunnableLambda(prompt_router)
| ChatOpenAI()
| StrOutputParser()
)
print(chain.invoke({"question": "What's a black gap"}))
print(chain.invoke({"question": "What's a path integral"}))
On this instance, the prompt_router perform calculates the cosine similarity between person enter and predefined immediate templates for physics and math questions. Based mostly on the similarity rating, the chain dynamically selects essentially the most related immediate template, making certain that the chatbot responds appropriately to the person’s query.
Utilizing Brokers and Runnables
LangChain lets you create brokers by combining Runnables, prompts, fashions, and instruments. Here is an instance of constructing an agent and utilizing it:
from langchain.brokers import XMLAgent, instrument, AgentExecutor
from langchain.chat_models import ChatAnthropic
mannequin = ChatAnthropic(mannequin="claude-2")
@instrument
def search(question: str) -> str:
"""Search issues about present occasions."""
return "32 levels"
tool_list = [search]
# Get immediate to make use of
immediate = XMLAgent.get_default_prompt()
# Logic for going from intermediate steps to a string to go into the mannequin
def convert_intermediate_steps(intermediate_steps):
log = ""
for motion, statement in intermediate_steps:
log += (
f"<instrument>{motion.instrument}</instrument><tool_input>{motion.tool_input}"
f"</tool_input><statement>{statement}</statement>"
)
return log
# Logic for changing instruments to a string to go within the immediate
def convert_tools(instruments):
return "n".be a part of([f"{tool.name}: {tool.description}" for tool in tools])
agent = (
{
"query": lambda x: x["question"],
"intermediate_steps": lambda x: convert_intermediate_steps(
x["intermediate_steps"]
),
}
| immediate.partial(instruments=convert_tools(tool_list))
| mannequin.bind(cease=["</tool_input>", "</final_answer>"])
| XMLAgent.get_default_output_parser()
)
agent_executor = AgentExecutor(agent=agent, instruments=tool_list, verbose=True)
outcome = agent_executor.invoke({"query": "What is the climate in New York?"})
print(outcome)
On this instance, an agent is created by combining a mannequin, instruments, a immediate, and a customized logic for intermediate steps and power conversion. The agent is then executed, offering a response to the person’s question.
Querying a SQL Database
You should utilize LangChain to question a SQL database and generate SQL queries based mostly on person questions. Here is an instance:
from langchain.prompts import ChatPromptTemplate
template = """Based mostly on the desk schema under, write a SQL question that may reply the person's query:
{schema}
Query: {query}
SQL Question:"""
immediate = ChatPromptTemplate.from_template(template)
from langchain.utilities import SQLDatabase
# Initialize the database (you may want the Chinook pattern DB for this instance)
db = SQLDatabase.from_uri("sqlite:///./Chinook.db")
def get_schema(_):
return db.get_table_info()
def run_query(question):
return db.run(question)
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
mannequin = ChatOpenAI()
sql_response = (
RunnablePassthrough.assign(schema=get_schema)
| immediate
| mannequin.bind(cease=["nSQLResult:"])
| StrOutputParser()
)
outcome = sql_response.invoke({"query": "What number of staff are there?"})
print(outcome)
template = """Based mostly on the desk schema under, query, SQL question, and SQL response, write a pure language response:
{schema}
Query: {query}
SQL Question: {question}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template)
full_chain = (
RunnablePassthrough.assign(question=sql_response)
| RunnablePassthrough.assign(
schema=get_schema,
response=lambda x: db.run(x["query"]),
)
| prompt_response
| mannequin
)
response = full_chain.invoke({"query": "What number of staff are there?"})
print(response)
On this instance, LangChain is used to generate SQL queries based mostly on person questions and retrieve responses from a SQL database. The prompts and responses are formatted to supply pure language interactions with the database.
Automate guide duties and workflows with our AI-driven workflow builder, designed by Nanonets for you and your groups.
LangServe & LangSmith
LangServe helps builders deploy LangChain runnables and chains as a REST API. This library is built-in with FastAPI and makes use of pydantic for knowledge validation. Moreover, it offers a consumer that can be utilized to name into runnables deployed on a server, and a JavaScript consumer is offered in LangChainJS.
Options
- Enter and Output schemas are routinely inferred out of your LangChain object and enforced on each API name, with wealthy error messages.
- An API docs web page with JSONSchema and Swagger is offered.
- Environment friendly /invoke, /batch, and /stream endpoints with assist for a lot of concurrent requests on a single server.
- /stream_log endpoint for streaming all (or some) intermediate steps out of your chain/agent.
- Playground web page at /playground with streaming output and intermediate steps.
- Constructed-in (non-obligatory) tracing to LangSmith; simply add your API key (see Directions).
- All constructed with battle-tested open-source Python libraries like FastAPI, Pydantic, uvloop, and asyncio.
Limitations
- Shopper callbacks usually are not but supported for occasions that originate on the server.
- OpenAPI docs is not going to be generated when utilizing Pydantic V2. FastAPI doesn’t assist mixing pydantic v1 and v2 namespaces. See the part under for extra particulars.
Use the LangChain CLI to bootstrap a LangServe undertaking rapidly. To make use of the langchain CLI, just remember to have a current model of langchain-cli put in. You’ll be able to set up it with pip set up -U langchain-cli.
langchain app new ../path/to/listing
Get your LangServe occasion began rapidly with LangChain Templates. For extra examples, see the templates index or the examples listing.
Here is a server that deploys an OpenAI chat mannequin, an Anthropic chat mannequin, and a series that makes use of the Anthropic mannequin to inform a joke a few matter.
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes
app = FastAPI(
title="LangChain Server",
model="1.0",
description="A easy api server utilizing Langchain's Runnable interfaces",
)
add_routes(
app,
ChatOpenAI(),
path="/openai",
)
add_routes(
app,
ChatAnthropic(),
path="/anthropic",
)
mannequin = ChatAnthropic()
immediate = ChatPromptTemplate.from_template("inform me a joke about {matter}")
add_routes(
app,
immediate | mannequin,
path="/chain",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
As soon as you have deployed the server above, you may view the generated OpenAPI docs utilizing:
curl localhost:8000/docs
Be sure so as to add the /docs suffix.
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable
openai = RemoteRunnable("http://localhost:8000/openai/")
anthropic = RemoteRunnable("http://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("http://localhost:8000/chain/")
joke_chain.invoke({"matter": "parrots"})
# or async
await joke_chain.ainvoke({"matter": "parrots"})
immediate = [
SystemMessage(content="Act like either a cat or a parrot."),
HumanMessage(content="Hello!")
]
# Helps astream
async for msg in anthropic.astream(immediate):
print(msg, finish="", flush=True)
immediate = ChatPromptTemplate.from_messages(
[("system", "Tell me a long story about {topic}")]
)
# Can outline customized chains
chain = immediate | RunnableMap({
"openai": openai,
"anthropic": anthropic,
})
chain.batch([{ "topic": "parrots" }, { "topic": "cats" }])
In TypeScript (requires LangChain.js model 0.0.166 or later):
import { RemoteRunnable } from "langchain/runnables/distant";
const chain = new RemoteRunnable({
url: `http://localhost:8000/chain/invoke/`,
});
const outcome = await chain.invoke({
matter: "cats",
});
Python utilizing requests:
import requests
response = requests.publish(
"http://localhost:8000/chain/invoke/",
json={'enter': {'matter': 'cats'}}
)
response.json()
You too can use curl:
curl --location --request POST 'http://localhost:8000/chain/invoke/'
--header 'Content material-Kind: software/json'
--data-raw '{
"enter": {
"matter": "cats"
}
}'
The next code:
...
add_routes(
app,
runnable,
path="/my_runnable",
)
provides of those endpoints to the server:
- POST /my_runnable/invoke – invoke the runnable on a single enter
- POST /my_runnable/batch – invoke the runnable on a batch of inputs
- POST /my_runnable/stream – invoke on a single enter and stream the output
- POST /my_runnable/stream_log – invoke on a single enter and stream the output, together with output of intermediate steps because it’s generated
- GET /my_runnable/input_schema – json schema for enter to the runnable
- GET /my_runnable/output_schema – json schema for output of the runnable
- GET /my_runnable/config_schema – json schema for config of the runnable
You could find a playground web page on your runnable at /my_runnable/playground. This exposes a easy UI to configure and invoke your runnable with streaming output and intermediate steps.
For each consumer and server:
pip set up "langserve[all]"
or pip set up “langserve[client]” for consumer code, and pip set up “langserve[server]” for server code.
If it’s essential to add authentication to your server, please reference FastAPI’s safety documentation and middleware documentation.
You’ll be able to deploy to GCP Cloud Run utilizing the next command:
gcloud run deploy [your-service-name] --source . --port 8001 --allow-unauthenticated --region us-central1 --set-env-vars=OPENAI_API_KEY=your_key
LangServe offers assist for Pydantic 2 with some limitations. OpenAPI docs is not going to be generated for invoke/batch/stream/stream_log when utilizing Pydantic V2. Quick API doesn’t assist mixing pydantic v1 and v2 namespaces. LangChain makes use of the v1 namespace in Pydantic v2. Please learn the next tips to make sure compatibility with LangChain. Aside from these limitations, we count on the API endpoints, the playground, and every other options to work as anticipated.
LLM purposes typically take care of information. There are completely different architectures that may be made to implement file processing; at a excessive stage:
- The file could also be uploaded to the server through a devoted endpoint and processed utilizing a separate endpoint.
- The file could also be uploaded by both worth (bytes of file) or reference (e.g., s3 url to file content material).
- The processing endpoint could also be blocking or non-blocking.
- If vital processing is required, the processing could also be offloaded to a devoted course of pool.
It is best to decide what’s the applicable structure on your software. At the moment, to add information by worth to a runnable, use base64 encoding for the file (multipart/form-data just isn’t supported but).
Here is an instance that exhibits learn how to use base64 encoding to ship a file to a distant runnable. Bear in mind, you may all the time add information by reference (e.g., s3 url) or add them as multipart/form-data to a devoted endpoint.
Enter and Output sorts are outlined on all runnables. You’ll be able to entry them through the input_schema and output_schema properties. LangServe makes use of these sorts for validation and documentation. If you wish to override the default inferred sorts, you should use the with_types methodology.
Here is a toy instance as an example the concept:
from typing import Any
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
app = FastAPI()
def func(x: Any) -> int:
"""Mistyped perform that ought to settle for an int however accepts something."""
return x + 1
runnable = RunnableLambda(func).with_types(
input_schema=int,
)
add_routes(app, runnable)
Inherit from CustomUserType if you need the info to deserialize right into a pydantic mannequin fairly than the equal dict illustration. For the time being, this sort solely works server-side and is used to specify desired decoding habits. If inheriting from this sort, the server will hold the decoded sort as a pydantic mannequin as a substitute of changing it right into a dict.
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
from langserve import add_routes
from langserve.schema import CustomUserType
app = FastAPI()
class Foo(CustomUserType):
bar: int
def func(foo: Foo) -> int:
"""Pattern perform that expects a Foo sort which is a pydantic mannequin"""
assert isinstance(foo, Foo)
return foo.bar
add_routes(app, RunnableLambda(func), path="/foo")
The playground lets you outline customized widgets on your runnable from the backend. A widget is specified on the area stage and shipped as a part of the JSON schema of the enter sort. A widget should comprise a key referred to as sort with the worth being considered one of a widely known listing of widgets. Different widget keys can be related to values that describe paths in a JSON object.
Common schema:
sort JsonPath = quantity | string | (quantity | string)[];
sort NameSpacedPath = { title: string; path: JsonPath }; // Utilizing title to imitate json schema, however can use namespace
sort OneOfPath = { oneOf: JsonPath[] };
sort Widget = OneOfPath;
;
Permits the creation of a file add enter within the UI playground for information which can be uploaded as base64 encoded strings. Here is the total instance.
strive:
from pydantic.v1 import Subject
besides ImportError:
from pydantic import Subject
from langserve import CustomUserType
# ATTENTION: Inherit from CustomUserType as a substitute of BaseModel in any other case
# the server will decode it right into a dict as a substitute of a pydantic mannequin.
class FileProcessingRequest(CustomUserType):
"""Request together with a base64 encoded file."""
# The additional area is used to specify a widget for the playground UI.
file: str = Subject(..., additional={"widget": {"sort": "base64file"}})
num_chars: int = 100
Automate guide duties and workflows with our AI-driven workflow builder, designed by Nanonets for you and your groups.
Introduction to LangSmith
LangChain makes it straightforward to prototype LLM purposes and Brokers. Nevertheless, delivering LLM purposes to manufacturing could be deceptively troublesome. You’ll doubtless need to closely customise and iterate in your prompts, chains, and different parts to create a high-quality product.
To assist on this course of, LangSmith was launched, a unified platform for debugging, testing, and monitoring your LLM purposes.
When may this turn out to be useful? You could discover it helpful whenever you wish to rapidly debug a brand new chain, agent, or set of instruments, visualize how parts (chains, llms, retrievers, and many others.) relate and are used, consider completely different prompts and LLMs for a single part, run a given chain a number of occasions over a dataset to make sure it constantly meets a top quality bar, or seize utilization traces and use LLMs or analytics pipelines to generate insights.
Stipulations:
- Create a LangSmith account and create an API key (see backside left nook).
- Familiarize your self with the platform by wanting by way of the docs.
Now, let’s get began!
First, configure your surroundings variables to inform LangChain to log traces. That is finished by setting the LANGCHAIN_TRACING_V2 surroundings variable to true. You’ll be able to inform LangChain which undertaking to log to by setting the LANGCHAIN_PROJECT surroundings variable (if this is not set, runs can be logged to the default undertaking). This can routinely create the undertaking for you if it does not exist. You need to additionally set the LANGCHAIN_ENDPOINT and LANGCHAIN_API_KEY surroundings variables.
NOTE: You too can use a context supervisor in python to log traces utilizing:
from langchain.callbacks.supervisor import tracing_v2_enabled
with tracing_v2_enabled(project_name="My Challenge"):
agent.run("How many individuals dwell in canada as of 2023?")
Nevertheless, on this instance, we’ll use surroundings variables.
%pip set up openai tiktoken pandas duckduckgo-search --quiet
import os
from uuid import uuid4
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-API-KEY>" # Replace to your API key
# Utilized by the agent on this tutorial
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
Create the LangSmith consumer to work together with the API:
from langsmith import Shopper
consumer = Shopper()
Create a LangChain part and log runs to the platform. On this instance, we’ll create a ReAct-style agent with entry to a normal search instrument (DuckDuckGo). The agent’s immediate could be seen within the Hub right here:
from langchain import hub
from langchain.brokers import AgentExecutor
from langchain.brokers.format_scratchpad import format_to_openai_function_messages
from langchain.brokers.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.instruments import DuckDuckGoSearchResults
from langchain.instruments.render import format_tool_to_openai_function
# Fetches the most recent model of this immediate
immediate = hub.pull("wfh/langsmith-agent-prompt:newest")
llm = ChatOpenAI(
mannequin="gpt-3.5-turbo-16k",
temperature=0,
)
instruments = [
DuckDuckGoSearchResults(
name="duck_duck_go"
), # General internet search using DuckDuckGo
]
llm_with_tools = llm.bind(features=[format_tool_to_openai_function(t) for t in tools])
runnable_agent = (
{
"enter": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| immediate
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
agent_executor = AgentExecutor(
agent=runnable_agent, instruments=instruments, handle_parsing_errors=True
)
We’re working the agent concurrently on a number of inputs to cut back latency. Runs get logged to LangSmith within the background, so execution latency is unaffected:
inputs = [
"What is LangChain?",
"What's LangSmith?",
"When was Llama-v2 released?",
"What is the langsmith cookbook?",
"When did langchain first announce the hub?",
]
outcomes = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True)
outcomes[:2]
Assuming you have efficiently arrange your surroundings, your agent traces ought to present up within the Tasks part within the app. Congrats!
It appears just like the agent is not successfully utilizing the instruments although. Let’s consider this so we now have a baseline.
Along with logging runs, LangSmith additionally lets you check and consider your LLM purposes.
On this part, you’ll leverage LangSmith to create a benchmark dataset and run AI-assisted evaluators on an agent. You’ll accomplish that in a number of steps:
- Create a LangSmith dataset:
Under, we use the LangSmith consumer to create a dataset from the enter questions from above and a listing labels. You’ll use these later to measure efficiency for a brand new agent. A dataset is a group of examples, that are nothing greater than input-output pairs you should use as check circumstances to your software:
outputs = [
"LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.",
"LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain",
"July 18, 2023",
"The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.",
"September 5, 2023",
]
dataset_name = f"agent-qa-{unique_id}"
dataset = consumer.create_dataset(
dataset_name,
description="An instance dataset of questions over the LangSmith documentation.",
)
for question, reply in zip(inputs, outputs):
consumer.create_example(
inputs={"enter": question}, outputs={"output": reply}, dataset_id=dataset.id
)
- Initialize a brand new agent to benchmark:
LangSmith helps you to consider any LLM, chain, agent, or perhaps a customized perform. Conversational brokers are stateful (they’ve reminiscence); to make sure that this state is not shared between dataset runs, we’ll go in a chain_factory (
aka a constructor) perform to initialize for every name:
# Since chains could be stateful (e.g. they will have reminiscence), we offer
# a approach to initialize a brand new chain for every row within the dataset. That is finished
# by passing in a manufacturing facility perform that returns a brand new chain for every row.
def agent_factory(immediate):
llm_with_tools = llm.bind(
features=[format_tool_to_openai_function(t) for t in tools]
)
runnable_agent = (
{
"enter": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_function_messages(
x["intermediate_steps"]
),
}
| immediate
| llm_with_tools
| OpenAIFunctionsAgentOutputParser()
)
return AgentExecutor(agent=runnable_agent, instruments=instruments, handle_parsing_errors=True)
Manually evaluating the outcomes of chains within the UI is efficient, however it may be time-consuming. It may be useful to make use of automated metrics and AI-assisted suggestions to guage your part’s efficiency:
from langchain.analysis import EvaluatorType
from langchain.smith import RunEvalConfig
evaluation_config = RunEvalConfig(
evaluators=[
EvaluatorType.QA,
EvaluatorType.EMBEDDING_DISTANCE,
RunEvalConfig.LabeledCriteria("helpfulness"),
RunEvalConfig.LabeledScoreString(
{
"accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference."""
},
normalize_by=10,
),
],
custom_evaluators=[],
)
- Run the agent and evaluators:
Use the run_on_dataset (or asynchronous arun_on_dataset) perform to guage your mannequin. This can:
- Fetch instance rows from the required dataset.
- Run your agent (or any customized perform) on every instance.
- Apply evaluators to the ensuing run traces and corresponding reference examples to generate automated suggestions.
The outcomes can be seen within the LangSmith app:
chain_results = run_on_dataset(
dataset_name=dataset_name,
llm_or_chain_factory=functools.partial(agent_factory, immediate=immediate),
analysis=evaluation_config,
verbose=True,
consumer=consumer,
project_name=f"runnable-agent-test-5d466cbc-{unique_id}",
tags=[
"testing-notebook",
"prompt:5d466cbc",
],
)
Now that we now have our check run outcomes, we will make modifications to our agent and benchmark them. Let’s do that once more with a special immediate and see the outcomes:
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0")
chain_results = run_on_dataset(
dataset_name=dataset_name,
llm_or_chain_factory=functools.partial(agent_factory, immediate=candidate_prompt),
analysis=evaluation_config,
verbose=True,
consumer=consumer,
project_name=f"runnable-agent-test-39f3bbd0-{unique_id}",
tags=[
"testing-notebook",
"prompt:39f3bbd0",
],
)
LangSmith helps you to export knowledge to frequent codecs reminiscent of CSV or JSONL straight within the net app. You too can use the consumer to fetch runs for additional evaluation, to retailer in your individual database, or to share with others. Let’s fetch the run traces from the analysis run:
runs = consumer.list_runs(project_name=chain_results["project_name"], execution_order=1)
# After a while, these can be populated.
consumer.read_project(project_name=chain_results["project_name"]).feedback_stats
This was a fast information to get began, however there are a lot of extra methods to make use of LangSmith to hurry up your developer movement and produce higher outcomes.
For extra info on how one can get essentially the most out of LangSmith, try LangSmith documentation.
Degree up with Nanonets
Whereas LangChain is a precious instrument for integrating language fashions (LLMs) together with your purposes, it might face limitations in relation to enterprise use circumstances. Let’s discover how Nanonets goes past LangChain to deal with these challenges:
1. Complete Knowledge Connectivity:
LangChain affords connectors, however it might not cowl all of the workspace apps and knowledge codecs that companies depend on. Nanonets offers knowledge connectors for over 100 extensively used workspace apps, together with Slack, Notion, Google Suite, Salesforce, Zendesk, and lots of extra. It additionally helps all unstructured knowledge sorts like PDFs, TXTs, photos, audio information, and video information, in addition to structured knowledge sorts like CSVs, spreadsheets, MongoDB, and SQL databases.

2. Activity Automation for Workspace Apps:
Whereas textual content / response technology works nice, LangChain’s capabilities are restricted in relation to utilizing pure language to carry out duties in numerous purposes. Nanonets affords set off/motion brokers for the most well-liked workspace apps, permitting you to arrange workflows that hear for occasions and carry out actions. For instance, you may automate e-mail responses, CRM entries, SQL queries, and extra, all by way of pure language instructions.

3. Actual-time Knowledge Sync:
LangChain fetches static knowledge with knowledge connectors, which can not sustain with knowledge modifications within the supply database. In distinction, Nanonets ensures real-time synchronization with knowledge sources, making certain that you simply’re all the time working with the most recent info.

3. Simplified Configuration:
Configuring the weather of the LangChain pipeline, reminiscent of retrievers and synthesizers, could be a complicated and time-consuming course of. Nanonets streamlines this by offering optimized knowledge ingestion and indexing for every knowledge sort, all dealt with within the background by the AI Assistant. This reduces the burden of fine-tuning and makes it simpler to arrange and use.
4. Unified Answer:
In contrast to LangChain, which can require distinctive implementations for every process, Nanonets serves as a one-stop resolution for connecting your knowledge with LLMs. Whether or not it’s essential to create LLM purposes or AI workflows, Nanonets affords a unified platform on your various wants.
Nanonets AI Workflows
Nanonets Workflows is a safe, multi-purpose AI Assistant that simplifies the combination of your information and knowledge with LLMs and facilitates creation of no-code purposes and workflows. It affords an easy-to-use person interface, making it accessible for each people and organizations.
To get began, you may schedule a name with considered one of our AI consultants, who can present a personalised demo and trial of Nanonets Workflows tailor-made to your particular use case.
As soon as arrange, you should use pure language to design and execute complicated purposes and workflows powered by LLMs, integrating seamlessly together with your apps and knowledge.

Supercharge your groups with Nanonets AI to create apps and combine your knowledge with AI-driven purposes and workflows, permitting your groups to deal with what actually issues.
Automate guide duties and workflows with our AI-driven workflow builder, designed by Nanonets for you and your groups.