
{kind=link}
Current advances within the growth of LLMs have popularized their utilization for numerous NLP duties that have been beforehand tackled utilizing older machine studying strategies. Massive language fashions are able to fixing quite a lot of language issues similar to classification, summarization, data retrieval, content material creation, query answering, and sustaining a dialog — all utilizing only one single mannequin. However how do we all know they’re doing an excellent job on all these completely different duties?
The rise of LLMs has dropped at mild an unresolved drawback: we don’t have a dependable normal for evaluating them. What makes analysis more durable is that they’re used for extremely numerous duties and we lack a transparent definition of what’s an excellent reply for every use case.
This text discusses present approaches to evaluating LLMs and introduces a brand new LLM leaderboard leveraging human analysis that improves upon current analysis strategies.
The primary and standard preliminary type of analysis is to run the mannequin on a number of curated datasets and study its efficiency. HuggingFace created an Open LLM Leaderboard the place open-access massive fashions are evaluated utilizing 4 well-known datasets (AI2 Reasoning Problem , HellaSwag , MMLU , TruthfulQA). This corresponds to automated analysis and checks the mannequin’s potential to get the info for some particular questions.
That is an instance of a query from the MMLU dataset.
Topic: college_medicine
Query: An anticipated aspect impact of creatine supplementation is.
- A) muscle weak spot
- B) acquire in physique mass
- C) muscle cramps
- D) lack of electrolytes
Reply: (B)
Scoring the mannequin on answering this sort of query is a vital metric and serves properly for fact-checking nevertheless it doesn’t take a look at the generative potential of the mannequin. That is in all probability the most important drawback of this analysis methodology as a result of producing free textual content is without doubt one of the most vital options of LLMs.
There appears to be a consensus inside the neighborhood that to guage the mannequin correctly we want human analysis. That is usually completed by evaluating the responses from completely different fashions.
Evaluating two immediate completions within the LMSYS challenge – screenshot by the Creator
Annotators determine which response is best, as seen within the instance above, and typically quantify the distinction in high quality of the immediate completions. LMSYS Org has created a leaderboard that makes use of this sort of human analysis and compares 17 completely different fashions, reporting the Elo ranking for every mannequin.
As a result of human analysis will be laborious to scale, there have been efforts to scale and velocity up the analysis course of and this resulted in an fascinating challenge referred to as AlpacaEval. Right here every mannequin is in comparison with a baseline (text-davinci-003 supplied by GPT-4) and human analysis is changed with GPT-4 judgment. This certainly is quick and scalable however can we belief the mannequin right here to carry out the scoring? We’d like to concentrate on mannequin biases. The challenge has truly proven that GPT-4 could favor longer solutions.
LLM analysis strategies are persevering with to evolve because the AI neighborhood searches for straightforward, truthful, and scalable approaches. The most recent growth comes from the workforce at Toloka with a brand new leaderboard to additional advance present analysis requirements.
The brand new leaderboard compares mannequin responses to real-world person prompts which might be categorized by helpful NLP duties as outlined in this InstructGPT paper. It additionally reveals every mannequin’s total win price throughout all classes.
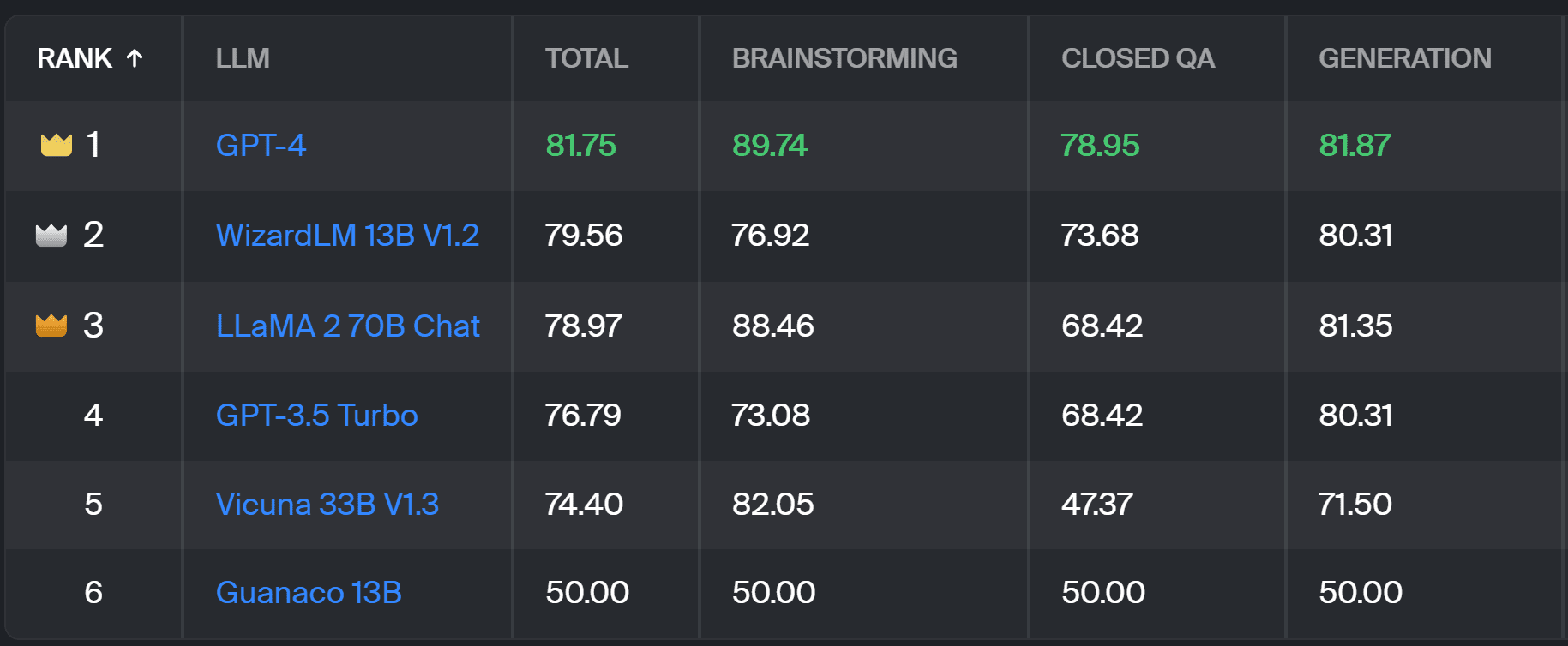
Toloka leaderboard – screenshot by the Creator
The analysis used for this challenge is just like the one carried out in AlpacaEval. The scores on the leaderboard signify the win price of the respective mannequin compared to the Guanaco 13B mannequin, which serves right here as a baseline comparability. The selection of Guanaco 13B is an enchancment to the AlpacaEval methodology, which makes use of the soon-to-be outdated text-davinci-003 mannequin because the baseline.
The precise analysis is completed by human professional annotators on a set of real-world prompts. For every immediate, annotators are given two completions and requested which one they like. You will discover particulars concerning the methodology right here.
One of these human analysis is extra helpful than every other automated analysis methodology and will enhance on the human analysis used for the LMSYS leaderboard. The draw back of the LMSYS methodology is that anyone with the hyperlink can participate within the analysis, elevating severe questions concerning the high quality of knowledge gathered on this method. A closed crowd of professional annotators has higher potential for dependable outcomes, and Toloka applies extra high quality management strategies to make sure knowledge high quality.
On this article, we now have launched a promising new resolution for evaluating LLMs — the Toloka Leaderboard. The method is revolutionary, combines the strengths of current strategies, provides task-specific granularity, and makes use of dependable human annotation strategies to check the fashions.
Discover the board, and share your opinions and solutions for enhancements with us.
Magdalena Konkiewicz is a Information Evangelist at Toloka, a world firm supporting quick and scalable AI growth. She holds a Grasp’s diploma in Synthetic Intelligence from Edinburgh College and has labored as an NLP Engineer, Developer, and Information Scientist for companies in Europe and America. She has additionally been concerned in educating and mentoring Information Scientists and often contributes to Information Science and Machine Studying publications.