{kind=link}
Giant language fashions have emerged as highly effective instruments able to producing human-like textual content and answering a variety of questions. These fashions, reminiscent of GPT-4, LLaMA, and PaLM, have been skilled on huge quantities of information, permitting them to imitate human-like responses and supply beneficial insights. Nevertheless, you will need to perceive that whereas these language fashions are extremely spectacular, they’re restricted to answering questions based mostly on the data on which they had been skilled.
When confronted with questions that haven’t been skilled on, they both point out that they don’t possess the information or might hallucinate attainable solutions. The answer for the lack of awareness in LLMs is both finetuning the LLM by yourself information or offering factual info together with the immediate given to the mannequin, permitting it to reply based mostly on that info.
We provide a technique to leverage the facility of Generative AI, particularly an AI mannequin like ChatGPT, to work together with data-rich however historically static codecs like PDFs. Primarily, we’re making an attempt to make a PDF “conversational,” reworking it from a one-way information supply into an interactive platform.There are a number of the reason why that is each mandatory and helpful:
Giant Language Fashions Limitations: Fashions like ChatGPT have a restrict on the size of the enter textual content they will deal with – in GPT-3’s case, a most of 2048 tokens. If we wish the mannequin to reference a big doc, like a PDF, we are able to’t merely feed all the doc into the mannequin concurrently.
Making AI Extra Correct: By offering factual info from the doc within the immediate, we may also help the mannequin present extra correct and context-specific responses. That is notably necessary when coping with complicated or specialised texts, reminiscent of scientific papers or authorized paperwork.So how will we overcome these challenges? The process entails a number of steps:
1. Loading the Doc: Step one is to load and cut up the PDF into manageable sections. That is performed utilizing particular libraries and modules designed for this job.
2. Creating Embeddings and Vectorization: That is the place issues get notably fascinating. An ‘embedding’ in AI phrases is a method of representing textual content information as numerical vectors. By creating embeddings for every part of the PDF, we translate the textual content right into a language that the AI can perceive and work with extra effectively. These embeddings are then used to create a ‘vector database’ – a searchable database the place every part of the PDF is represented by its embedding vector.
3. Querying: When a question or query is posed to the system, the identical course of of making an embedding is utilized to the question. This question embedding is then in contrast with the embeddings within the vector database to seek out essentially the most related sections of the PDF. These sections are then used because the enter to ChatGPT, which generates a solution based mostly on this targeted, related information.This technique permits us to bypass the restrictions of huge language fashions and use them to work together with giant paperwork in an environment friendly and correct method. It prevents “hallucinations” and provides precise factual information. The process opens up a brand new realm of potentialities, from aiding analysis to enhancing accessibility, making the huge quantities of knowledge saved in PDFs extra approachable and usable.
On this article, we are going to delve into an instance of letting the LLM reply the questions by giving factual info together with the immediate. So, let’s dive in:
Right here we’re utilizing 8 paperwork from the Worldwide disaster group that covers numerous causes of conflicts, present detailed evaluation and provide a sensible resolution for the disaster. You may even observe this even along with your information. Additionally, One factor to bear in mind when offering information to the mannequin is that the LLMs can’t course of the massive prompts and they’ll give fault solutions if they’re so lengthy.
Tips on how to overcome this Problem?
Step 1: Add all of the PDFs into an Utility on the Clarifai’s Portal
After importing the PDF information they get transformed into chunks of 300 phrases every. This incorporates chunk supply, Web page Quantity, Chunk Index and Textual content Size.
As soon as it’s performed the Platform is ready to generate Embeddings for every one. In case you are not acquainted an Embedding is a vector that represents the which means in a given textual content. It is a good technique to discover a comparable textual content which can ultimately assist in answering a immediate.
Step 2: Ship a question to the platform and let’s see how this works.
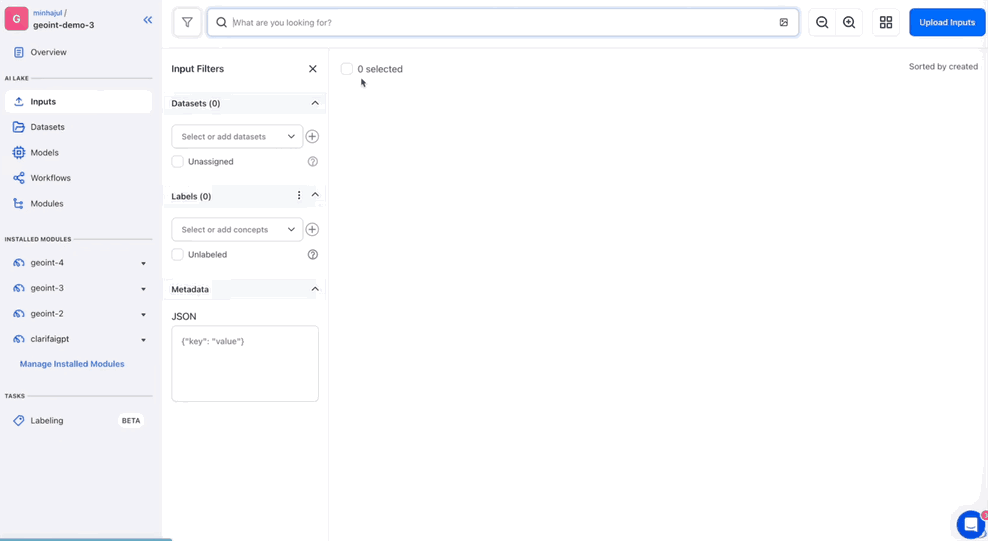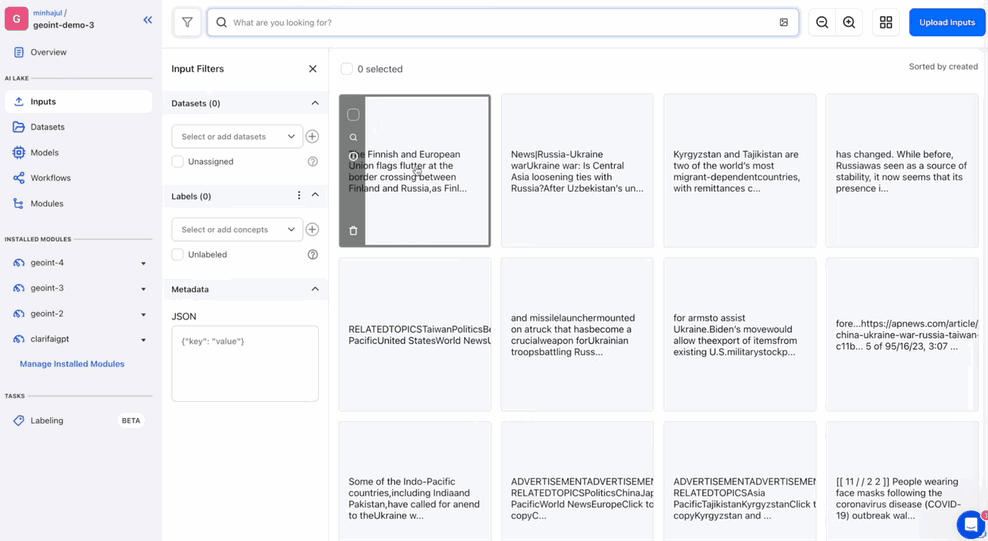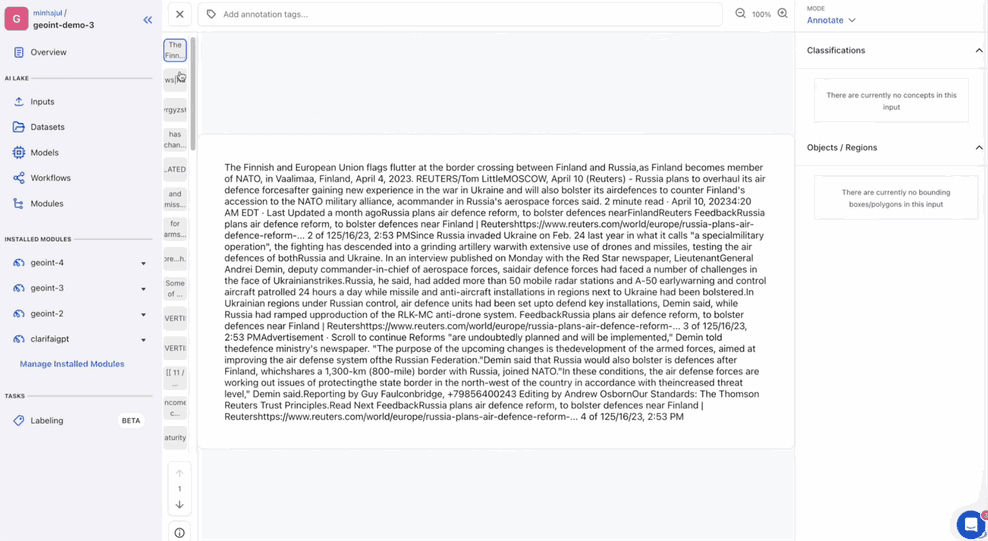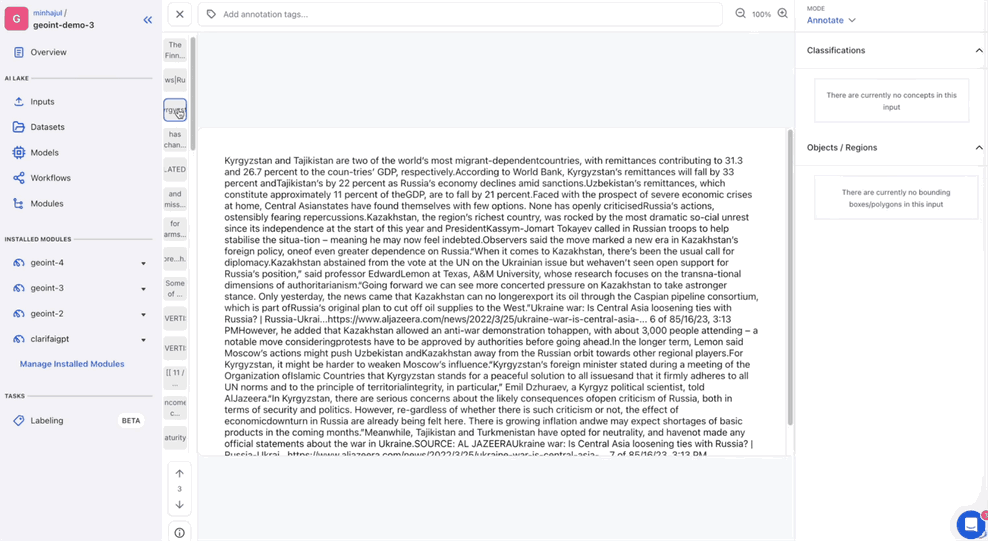
Given the question “Discover the paperwork about terrorism ” first it calculates the embedding for that question and compares this with the already current embeddings of the textual content chunks and finds essentially the most related textual content to the question.
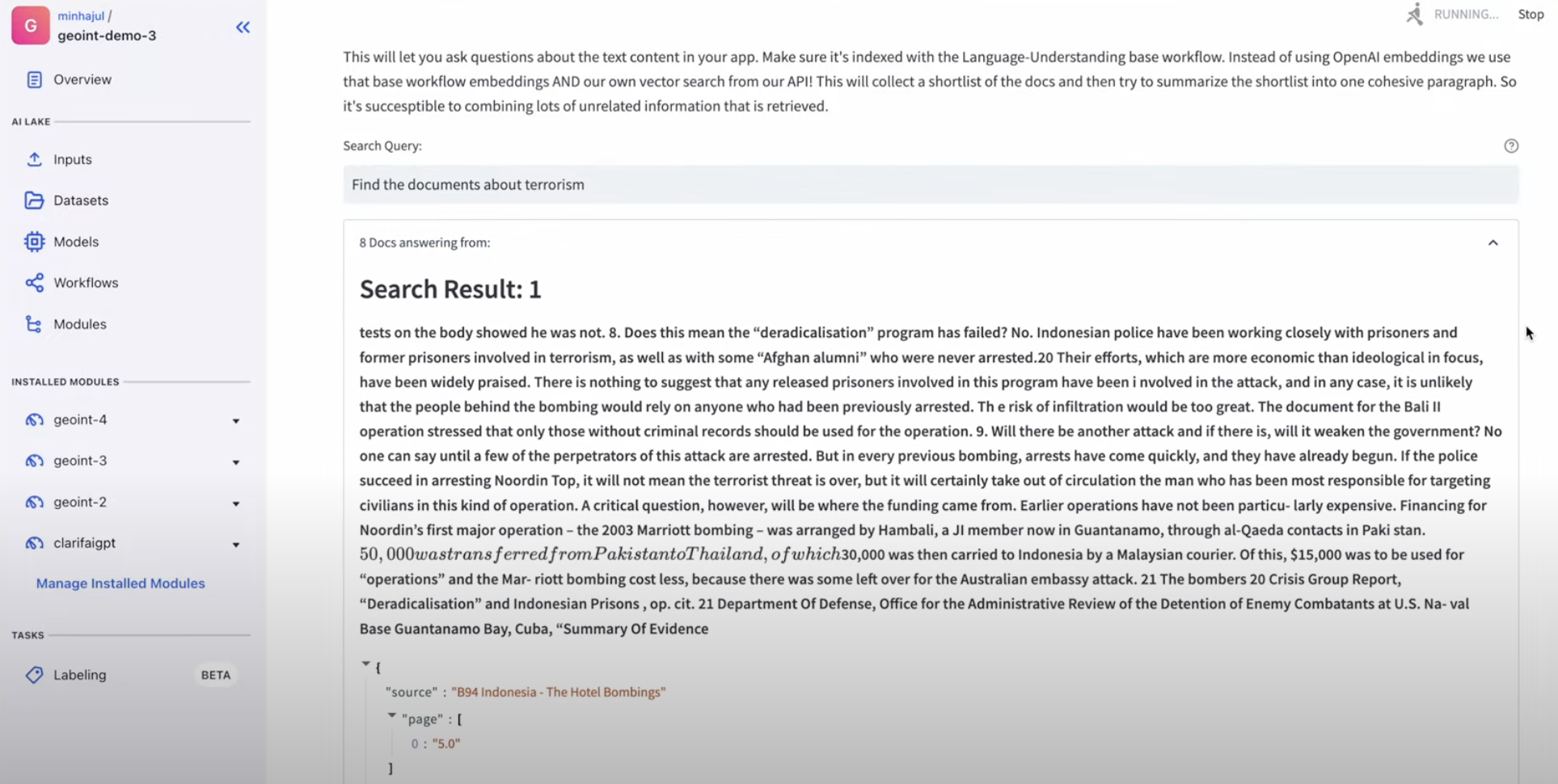
This additionally returns the supply, web page quantity and a similarity rating that represents how shut the question and the textual content chunks are. This additionally identifies the folks, organizations, places, time stamps and so on current within the textual content chunks.
Let’s check out one particular person saefuddin zuhri and choose the doc to look at.
On this occasion, we are going to give attention to the similarity rating and choose doc 1, which can present us with a abstract and an inventory of sources associated to that abstract.
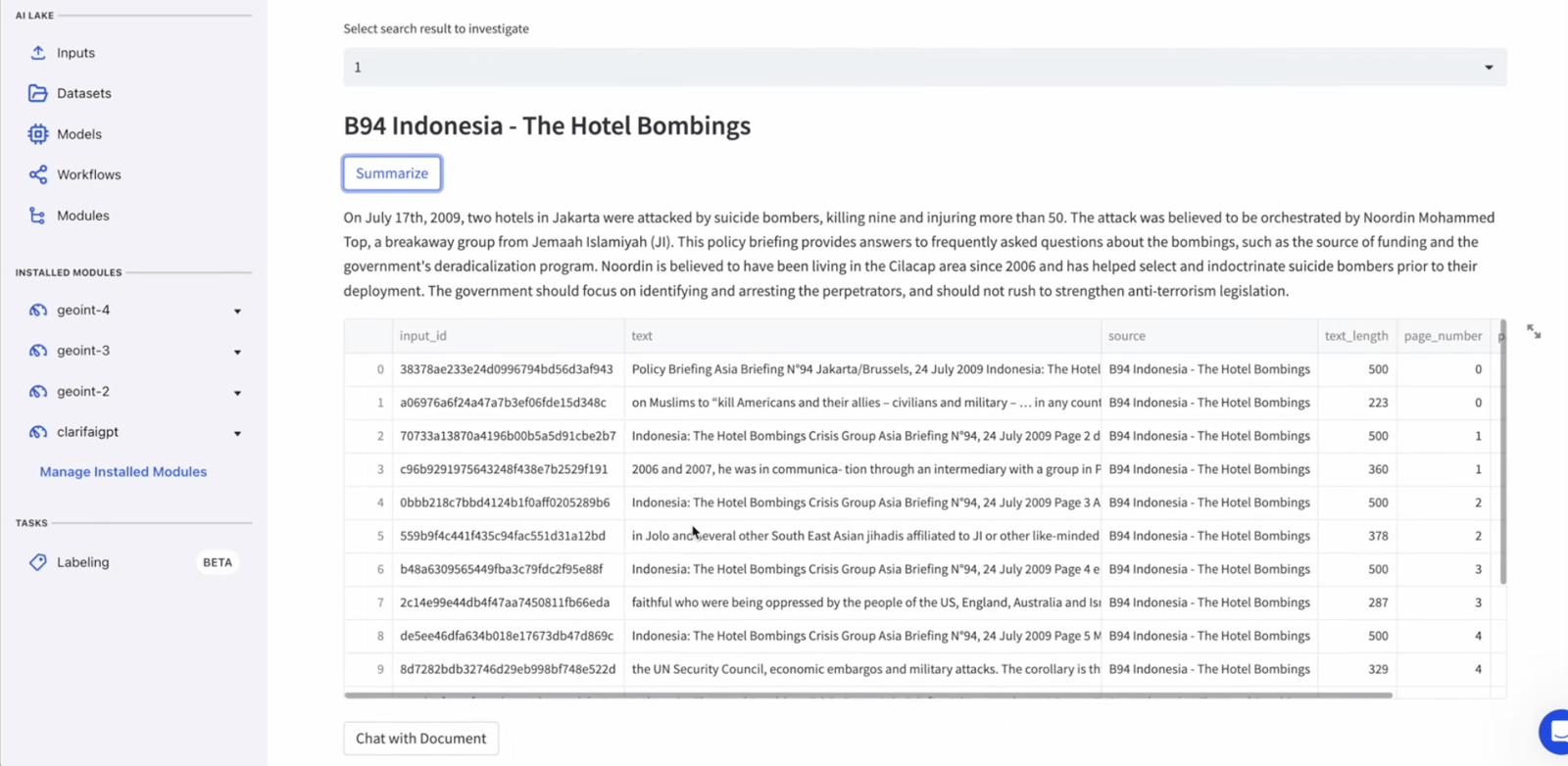
Step 3: Chat with the Doc
Let’s ask the query Who’s Saefuddin Zuhri? behind the scenes this may ultimately prepend the above summarized textual content together with the question, In order that the mannequin can solely reply based mostly on the factual info given.
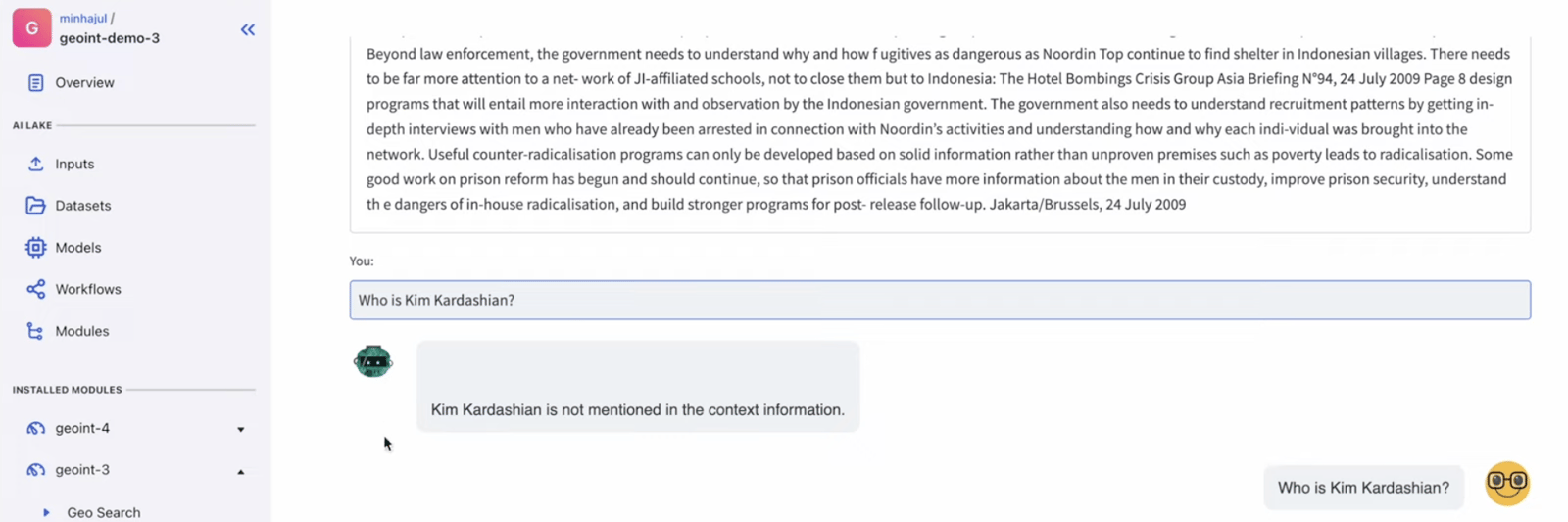
Right here is the reply from the mannequin which it didn’t have any concept earlier than.
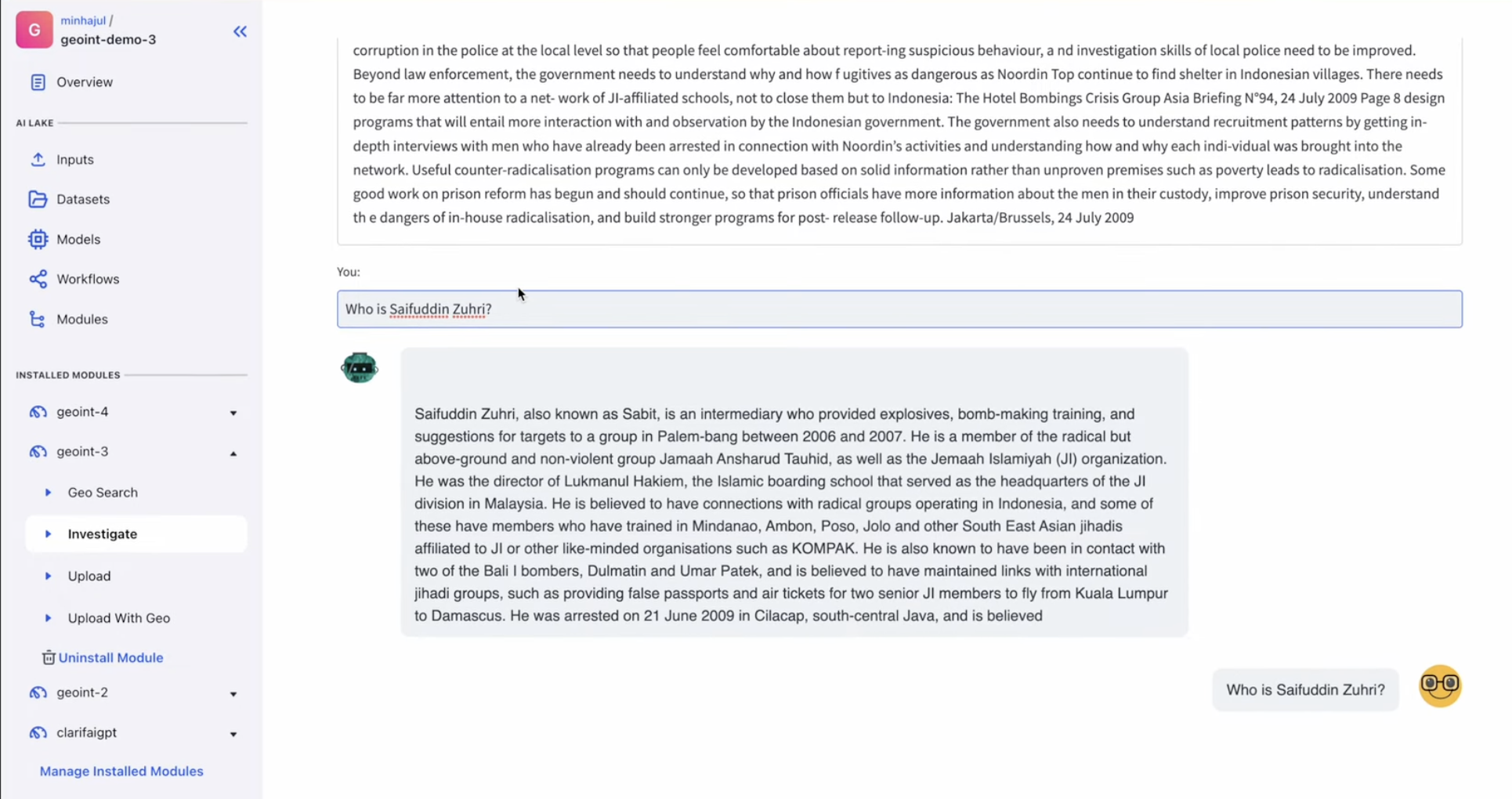
Additionally if we attempt to ask the mannequin the query outdoors the context of given information it merely return that it isn’t talked about within the context info.
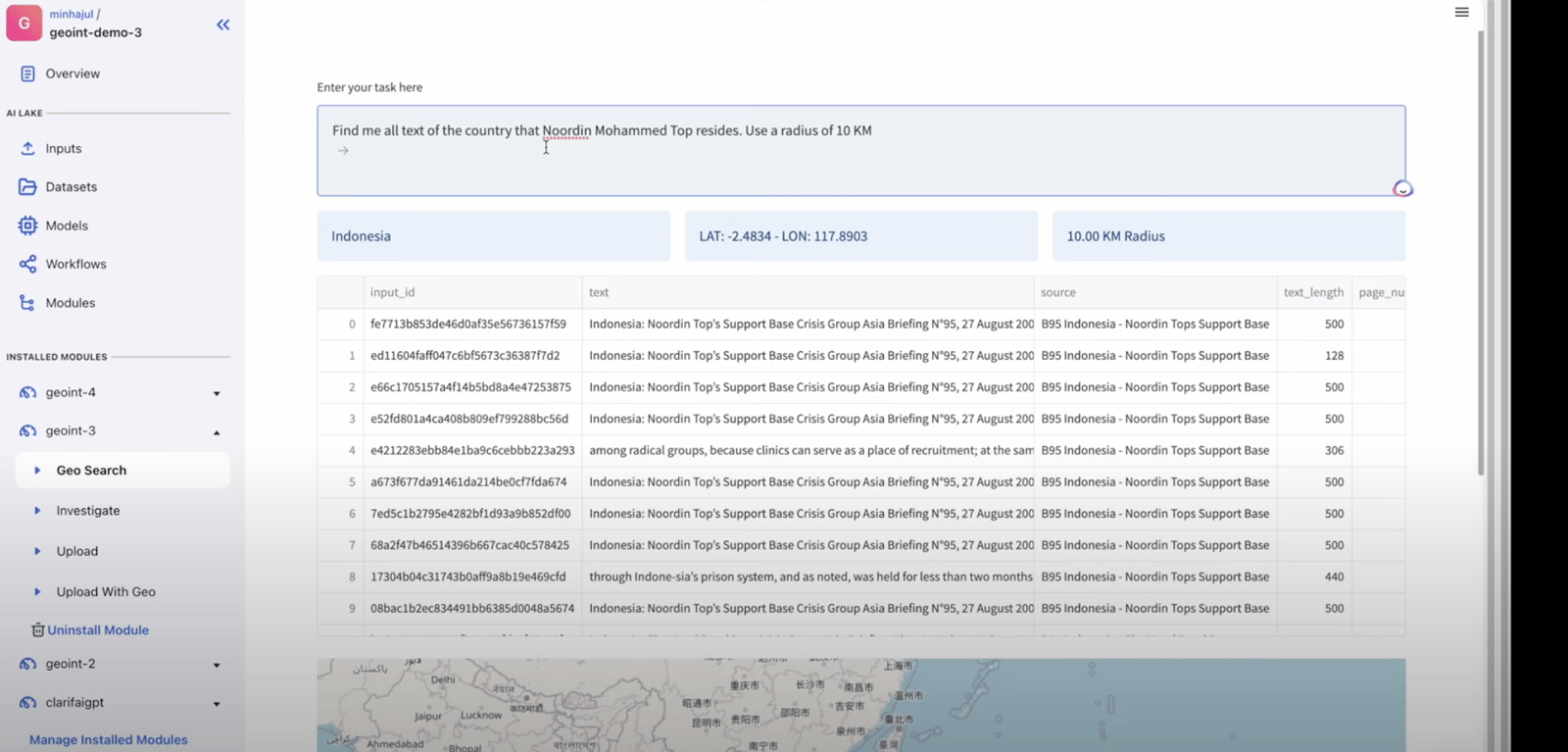
The opposite necessary capability of the platform is to analyze geographical places and plot them on a map, Right here is the way it works:
Given a question to seek out the situation the place the “Noordin Mohammed” resides utilizing the radius of 10KM. Right here is the consequence as we will likely be supplied with the record of supply chunks the place the situation information was discovered.