

{kind=link}
Debugging efficiency points in databases is difficult, and there’s a want for a instrument that may present helpful and in-context troubleshooting suggestions. Giant Language Fashions (LLMs) like ChatGPT can reply many questions however typically present imprecise or generic suggestions for database efficiency queries.
Whereas LLMs are skilled on huge quantities of web knowledge, their generic suggestions lack context and the multi-modal evaluation required for debugging. Retrieval Augmented Era (RAG) is proposed to reinforce prompts with related info, however making use of LLM-generated suggestions in actual databases raises issues about belief, affect, suggestions, and danger. Thus, What are the important constructing blocks wanted for safely deploying LLMs in manufacturing for correct, verifiable, actionable, and helpful suggestions? is an open and ambiguous query.
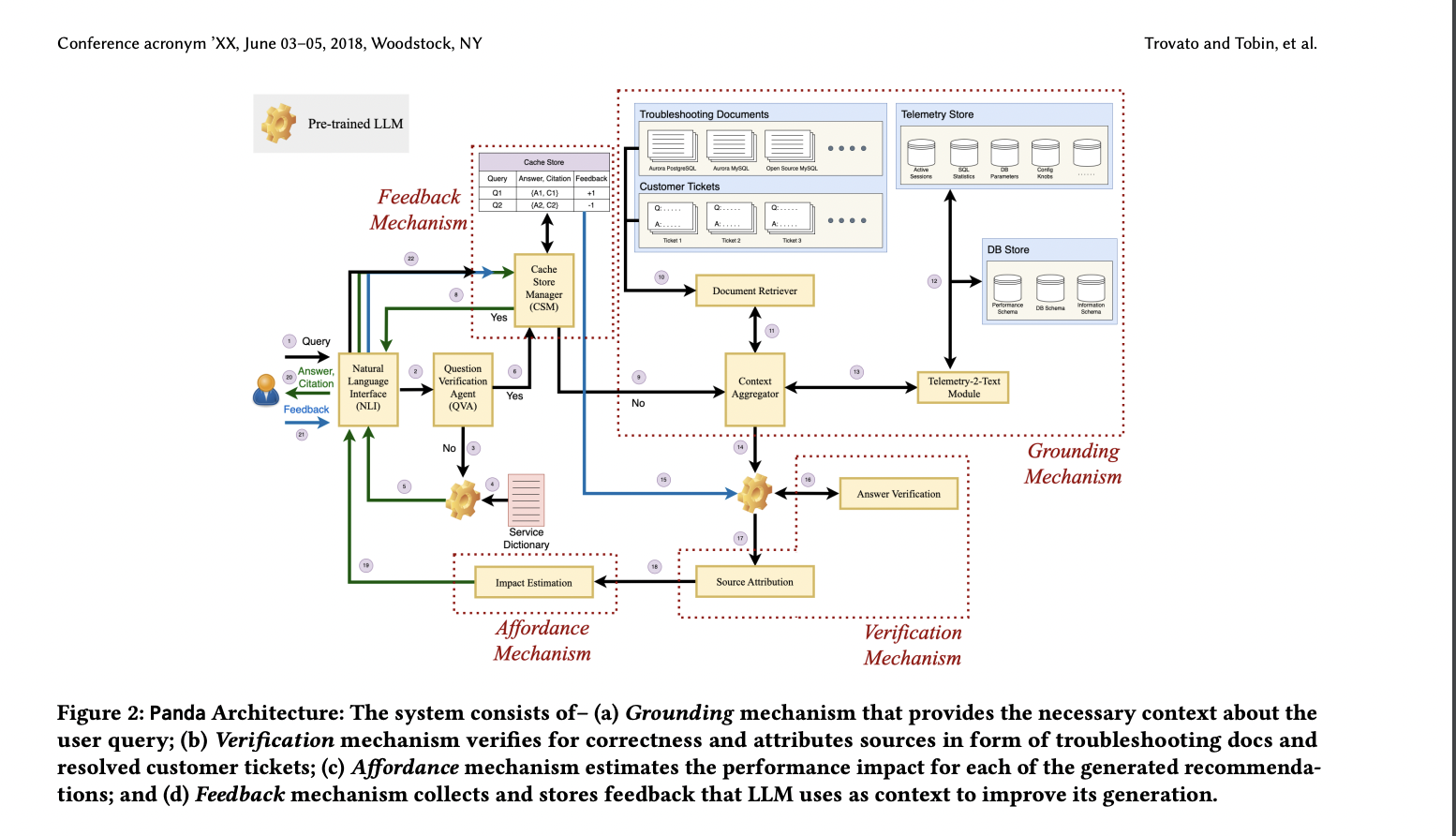
Researchers from AWS AI Labs and Amazon Net Companies have proposed Panda, which goals to supply context grounding to pre-trained LLMs for producing extra helpful and in-context troubleshooting suggestions for database efficiency debugging. Panda has a number of key parts: grounding, verification, affordability, and suggestions.
The Panda system includes 5 parts: Query Verification Agent filters queries for relevance, the Grounding Mechanism extracts world and native contexts, the Verification Mechanism ensures reply correctness, the Suggestions Mechanism incorporates consumer suggestions, and the Affordance Mechanism estimates the affect of beneficial fixes. Panda makes use of Retrieval Augmented Era for contextual question dealing with, using embeddings for similarity searches. Telemetry metrics and troubleshooting docs present multi-modal knowledge for higher understanding and extra correct suggestions, addressing the contextual challenges of database efficiency debugging.
In a small experimental examine evaluating Panda, using GPT-3.5, with GPT-4 for real-world problematic database workloads, Panda demonstrated superior reliability and usefulness in keeping with Database Engineers’ evaluations. Intermediate and Superior DBEs discovered Panda’s solutions extra reliable and helpful as a result of supply citations and correctness grounded in telemetry and troubleshooting paperwork. Newbie DBEs additionally favored Panda however highlighted issues about specificity. Statistical evaluation utilizing a two-sample T-Take a look at confirmed the statistical superiority of Panda over GPT-4.
In conclusion, the researchers introduce Panda, an progressive system for autonomous database debugging utilizing NL brokers. Panda excels in figuring out and rejecting irrelevant queries, establishing significant multi-modal contexts, estimating affect, providing citations, and studying from suggestions. It emphasizes the importance of addressing open analysis questions encountered throughout its improvement and invitations collaboration from the database and programs communities to reshape the database debugging course of collectively. The system goals to redefine and improve the general strategy to debugging databases.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our Telegram Channel
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.