

{kind=link}
Generative fashions, equivalent to Generative Adversarial Networks (GANs), have the capability to generate lifelike photographs of objects and dressed people after being educated on an in depth picture assortment. Though the ensuing output is a 2D picture, quite a few functions necessitate various and high-quality digital 3D avatars. These avatars ought to enable pose and digital camera viewpoint management whereas guaranteeing 3D consistency. To deal with the demand for 3D avatars, the analysis neighborhood explores generative fashions able to robotically producing 3D shapes of people and clothes primarily based on enter parameters like physique pose and form. Regardless of appreciable developments, most current strategies overlook texture and depend on exact and clear 3D scans of people for coaching. Buying such scans is dear, limiting their availability and variety.
Growing a technique for studying the technology of 3D human shapes and textures from unstructured picture information presents a difficult and under-constrained downside. Every coaching occasion displays distinctive shapes and appearances, noticed solely as soon as from particular viewpoints and poses. Whereas latest progress in 3D-aware GANs has proven spectacular outcomes for inflexible objects, these strategies face difficulties in producing life like people as a result of complexity of human articulation. Though some latest work demonstrates the feasibility of studying articulated people, current approaches battle with restricted high quality, decision, and challenges in modeling free clothes.
The paper reported on this article introduces a novel methodology for 3D human technology from 2D picture collections, reaching state-of-the-art picture and geometry high quality whereas successfully modeling free clothes.
The overview of the proposed methodology is illustrated beneath.
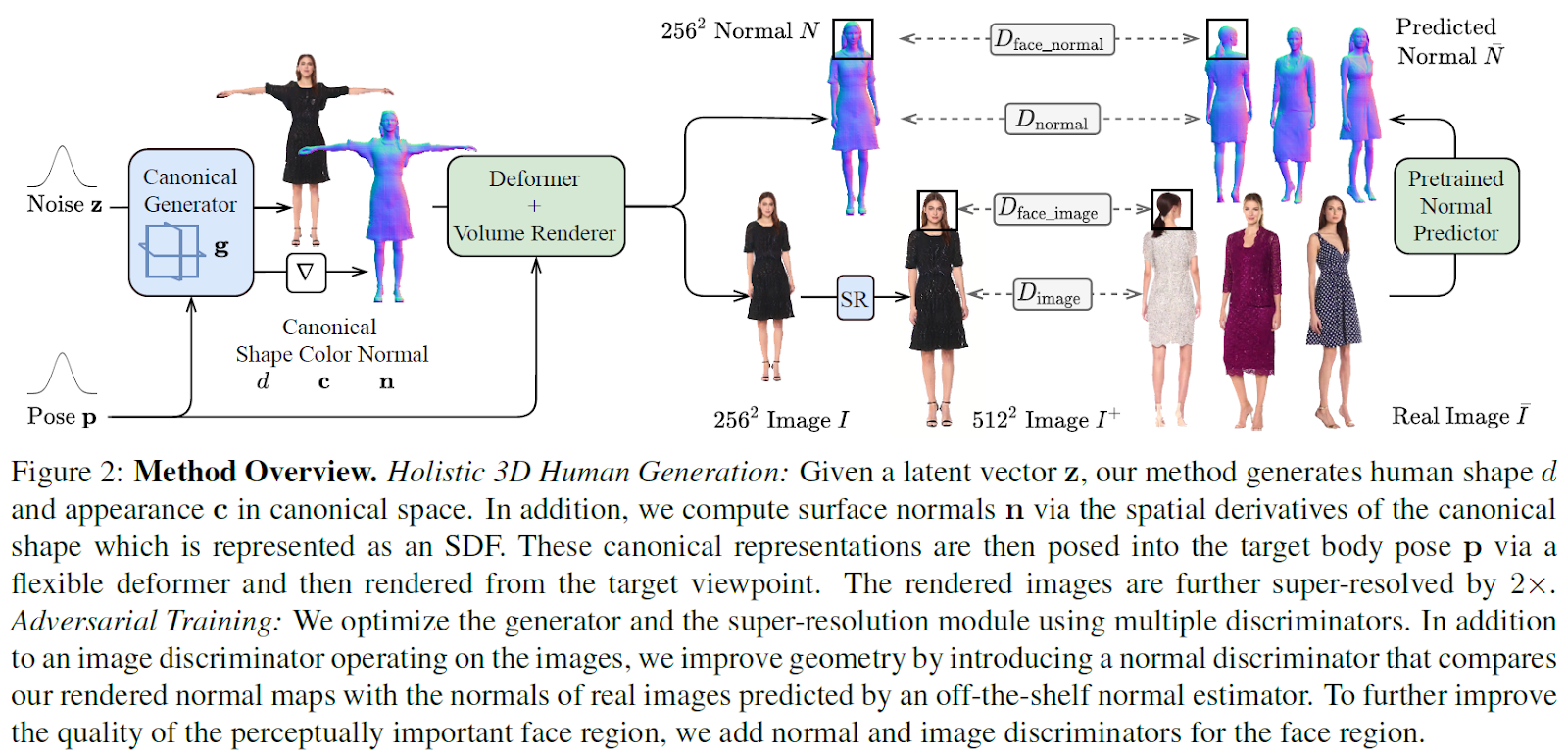
This methodology adopts a monolithic design able to modeling each the human physique and free clothes, departing from the method of representing people with separate physique elements. A number of discriminators are integrated to boost geometric element and concentrate on perceptually essential areas.
A novel generator design is proposed to deal with the aim of excessive picture high quality and versatile dealing with of free clothes, modeling 3D people holistically in a canonical area. The articulation module, Quick-SNARF, is answerable for the motion and positioning of physique elements and tailored to the generative setting. Moreover, the mannequin adopts empty-space skipping, optimizing and accelerating the rendering of areas with no vital content material to enhance general effectivity.
The modular 2D discriminators are guided by regular info, that means they contemplate the directionality of surfaces within the 3D area. This steerage helps the mannequin concentrate on areas which can be perceptually essential for human observers, contributing to a extra correct and visually pleasing consequence. Moreover, the discriminators prioritize geometric particulars, enhancing the general high quality of the generated photographs. This enchancment possible contributes to a extra life like and visually interesting illustration of the 3D human fashions.

The experimental outcomes reported above exhibit a big enchancment of the proposed methodology over earlier 3D- and articulation-aware strategies by way of geometry and texture high quality, validated quantitatively, qualitatively, and thru perceptual research.
In abstract, this contribution features a generative mannequin of articulated 3D people with state-of-the-art look and geometry, an environment friendly generator for free clothes, and specialised discriminators enhancing visible and geometric constancy. The authors plan to launch the code and fashions for additional exploration.
Try the Paper and Mission Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to affix our 33k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and Electronic mail E-newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
In the event you like our work, you’ll love our publication..
Daniele Lorenzi acquired his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Data Expertise (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s at the moment working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embody adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.