
{kind=link}
The IMDB dataset
On this instance, we’ll work with the IMDB dataset: a set of fifty,000 extremely polarized opinions from the Web Film Database. They’re break up into 25,000 opinions for coaching and 25,000 opinions for testing, every set consisting of fifty% destructive and 50% optimistic opinions.
Why use separate coaching and check units? Since you ought to by no means check a machine-learning mannequin on the identical knowledge that you just used to coach it! Simply because a mannequin performs nicely on its coaching knowledge doesn’t imply it’s going to carry out nicely on knowledge it has by no means seen; and what you care about is your mannequin’s efficiency on new knowledge (since you already know the labels of your coaching knowledge – clearly
you don’t want your mannequin to foretell these). For example, it’s attainable that your mannequin may find yourself merely memorizing a mapping between your coaching samples and their targets, which might be ineffective for the duty of predicting targets for knowledge the mannequin has by no means seen earlier than. We’ll go over this level in far more element within the subsequent chapter.
Identical to the MNIST dataset, the IMDB dataset comes packaged with Keras. It has already been preprocessed: the opinions (sequences of phrases) have been was sequences of integers, the place every integer stands for a particular phrase in a dictionary.
The next code will load the dataset (whenever you run it the primary time, about 80 MB of knowledge will likely be downloaded to your machine).
The argument num_words = 10000 means you’ll solely hold the highest 10,000 most incessantly occurring phrases within the coaching knowledge. Uncommon phrases will likely be discarded. This lets you work with vector knowledge of manageable dimension.
The variables train_data and test_data are lists of opinions; every evaluation is a listing of phrase indices (encoding a sequence of phrases). train_labels and test_labels are lists of 0s and 1s, the place 0 stands for destructive and 1 stands for optimistic:
int [1:218] 1 14 22 16 43 530 973 1622 1385 65 ...[1] 1Since you’re limiting your self to the highest 10,000 most frequent phrases, no phrase index will exceed 10,000:
[1] 9999For kicks, right here’s how one can shortly decode one in every of these opinions again to English phrases:
# Named listing mapping phrases to an integer index.
word_index <- dataset_imdb_word_index()
reverse_word_index <- names(word_index)
names(reverse_word_index) <- word_index
# Decodes the evaluation. Notice that the indices are offset by 3 as a result of 0, 1, and
# 2 are reserved indices for "padding," "begin of sequence," and "unknown."
decoded_review <- sapply(train_data[[1]], perform(index) {
phrase <- if (index >= 3) reverse_word_index[[as.character(index - 3)]]
if (!is.null(phrase)) phrase else "?"
})
cat(decoded_review)? this movie was simply sensible casting location surroundings story course
everybody's actually suited the half they performed and you may simply think about
being there robert ? is a tremendous actor and now the identical being director
? father got here from the identical scottish island as myself so i cherished the very fact
there was an actual reference to this movie the witty remarks all through
the movie had been nice it was simply sensible a lot that i purchased the movie
as quickly because it was launched for ? and would suggest it to everybody to
watch and the fly fishing was wonderful actually cried on the finish it was so
unhappy and you already know what they are saying if you happen to cry at a movie it will need to have been
good and this undoubtedly was additionally ? to the 2 little boy's that performed'
the ? of norman and paul they had been simply sensible kids are sometimes left
out of the ? listing i feel as a result of the celebs that play all of them grown up
are such a giant profile for the entire movie however these kids are wonderful
and needs to be praised for what they've carried out do not you suppose the entire
story was so beautiful as a result of it was true and was somebody's life in any case
that was shared with us allGetting ready the information
You possibly can’t feed lists of integers right into a neural community. You must flip your lists into tensors. There are two methods to try this:
- Pad your lists in order that all of them have the identical size, flip them into an integer tensor of form
(samples, word_indices), after which use as the primary layer in your community a layer able to dealing with such integer tensors (the “embedding” layer, which we’ll cowl intimately later within the guide). - One-hot encode your lists to show them into vectors of 0s and 1s. This might imply, as an example, turning the sequence
[3, 5]into a ten,000-dimensional vector that may be all 0s apart from indices 3 and 5, which might be 1s. Then you may use as the primary layer in your community a dense layer, able to dealing with floating-point vector knowledge.
Let’s go along with the latter answer to vectorize the information, which you’ll do manually for optimum readability.
vectorize_sequences <- perform(sequences, dimension = 10000) {
# Creates an all-zero matrix of form (size(sequences), dimension)
outcomes <- matrix(0, nrow = size(sequences), ncol = dimension)
for (i in 1:size(sequences))
# Units particular indices of outcomes[i] to 1s
outcomes[i, sequences[[i]]] <- 1
outcomes
}
x_train <- vectorize_sequences(train_data)
x_test <- vectorize_sequences(test_data)Right here’s what the samples appear to be now:
num [1:10000] 1 1 0 1 1 1 1 1 1 0 ...You must also convert your labels from integer to numeric, which is easy:
Now the information is able to be fed right into a neural community.
Constructing your community
The enter knowledge is vectors, and the labels are scalars (1s and 0s): that is the best setup you’ll ever encounter. A sort of community that performs nicely on such an issue is an easy stack of totally related (“dense”) layers with relu activations: layer_dense(items = 16, activation = "relu").
The argument being handed to every dense layer (16) is the variety of hidden items of the layer. A hidden unit is a dimension within the illustration house of the layer. Chances are you’ll bear in mind from chapter 2 that every such dense layer with a relu activation implements the next chain of tensor operations:
output = relu(dot(W, enter) + b)
Having 16 hidden items means the burden matrix W could have form (input_dimension, 16): the dot product with W will mission the enter knowledge onto a 16-dimensional illustration house (and you then’ll add the bias vector b and apply the relu operation). You possibly can intuitively perceive the dimensionality of your illustration house as “how a lot freedom you’re permitting the community to have when studying inside representations.” Having extra hidden items (a higher-dimensional illustration house) permits your community to be taught more-complex representations, nevertheless it makes the community extra computationally costly and will result in studying undesirable patterns (patterns that
will enhance efficiency on the coaching knowledge however not on the check knowledge).
There are two key structure choices to be made about such stack of dense layers:
- What number of layers to make use of
- What number of hidden items to decide on for every layer
In chapter 4, you’ll be taught formal rules to information you in making these decisions. In the interim, you’ll must belief me with the next structure selection:
- Two intermediate layers with 16 hidden items every
- A 3rd layer that may output the scalar prediction relating to the sentiment of the present evaluation
The intermediate layers will use relu as their activation perform, and the ultimate layer will use a sigmoid activation in order to output a likelihood (a rating between 0 and 1, indicating how possible the pattern is to have the goal “1”: how possible the evaluation is to be optimistic). A relu (rectified linear unit) is a perform meant to zero out destructive values.

A sigmoid “squashes” arbitrary values into the [0, 1] interval, outputting one thing that may be interpreted as a likelihood.

Right here’s what the community appears like.

Right here’s the Keras implementation, much like the MNIST instance you noticed beforehand.
Activation Capabilities
Notice that with out an activation perform like relu (additionally known as a non-linearity), the dense layer would include two linear operations – a dot product and an addition:
output = dot(W, enter) + b
So the layer may solely be taught linear transformations (affine transformations) of the enter knowledge: the speculation house of the layer could be the set of all attainable linear transformations of the enter knowledge right into a 16-dimensional house. Such a speculation house is simply too restricted and wouldn’t profit from a number of layers of representations, as a result of a deep stack of linear layers would nonetheless implement a linear operation: including extra layers wouldn’t prolong the speculation house.
To be able to get entry to a a lot richer speculation house that may profit from deep representations, you want a non-linearity, or activation perform. relu is the most well-liked activation perform in deep studying, however there are various different candidates, which all include equally unusual names: prelu, elu, and so forth.
Loss Operate and Optimizer
Lastly, it’s essential to select a loss perform and an optimizer. Since you’re going through a binary classification drawback and the output of your community is a likelihood (you finish your community with a single-unit layer with a sigmoid activation), it’s greatest to make use of the binary_crossentropy loss. It isn’t the one viable selection: you may use, as an example, mean_squared_error. However crossentropy is often the only option whenever you’re coping with fashions that output possibilities. Crossentropy is a amount from the sector of Data Concept that measures the space between likelihood distributions or, on this case, between the ground-truth distribution and your predictions.
Right here’s the step the place you configure the mannequin with the rmsprop optimizer and the binary_crossentropy loss perform. Notice that you just’ll additionally monitor accuracy throughout coaching.
mannequin %>% compile(
optimizer = "rmsprop",
loss = "binary_crossentropy",
metrics = c("accuracy")
)You’re passing your optimizer, loss perform, and metrics as strings, which is feasible as a result of rmsprop, binary_crossentropy, and accuracy are packaged as a part of Keras. Generally chances are you’ll wish to configure the parameters of your optimizer or move a customized loss perform or metric perform. The previous might be carried out by passing an optimizer occasion because the optimizer argument:
mannequin %>% compile(
optimizer = optimizer_rmsprop(lr=0.001),
loss = "binary_crossentropy",
metrics = c("accuracy")
) Customized loss and metrics capabilities might be supplied by passing perform objects because the loss and/or metrics arguments
mannequin %>% compile(
optimizer = optimizer_rmsprop(lr = 0.001),
loss = loss_binary_crossentropy,
metrics = metric_binary_accuracy
) Validating your method
To be able to monitor throughout coaching the accuracy of the mannequin on knowledge it has by no means seen earlier than, you’ll create a validation set by isolating 10,000 samples from the unique coaching knowledge.
val_indices <- 1:10000
x_val <- x_train[val_indices,]
partial_x_train <- x_train[-val_indices,]
y_val <- y_train[val_indices]
partial_y_train <- y_train[-val_indices]You’ll now practice the mannequin for 20 epochs (20 iterations over all samples within the x_train and y_train tensors), in mini-batches of 512 samples. On the similar time, you’ll monitor loss and accuracy on the ten,000 samples that you just set aside. You achieve this by passing the validation knowledge because the validation_data argument.
On CPU, this may take lower than 2 seconds per epoch – coaching is over in 20 seconds. On the finish of each epoch, there’s a slight pause because the mannequin computes its loss and accuracy on the ten,000 samples of the validation knowledge.
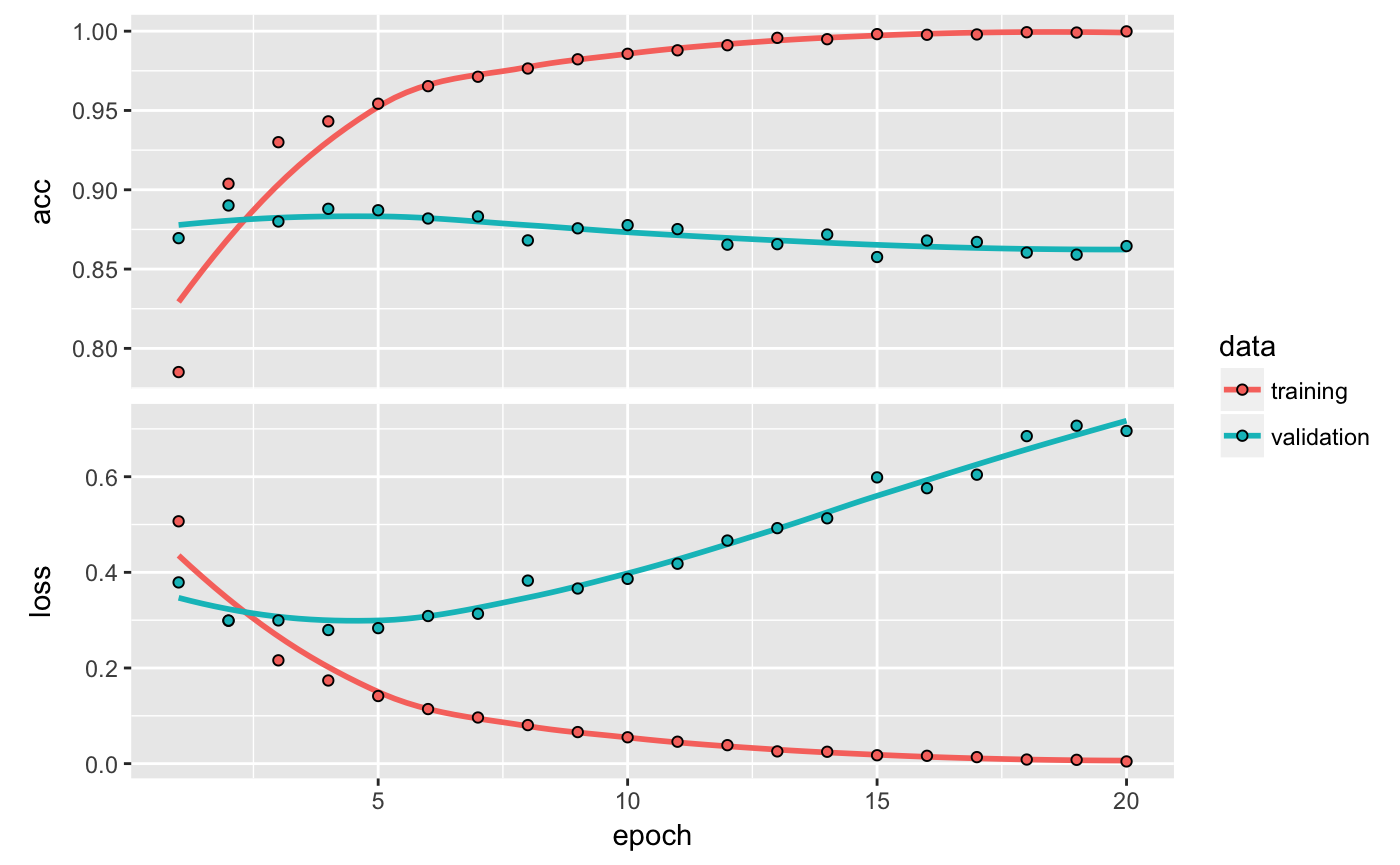
Notice that the decision to match() returns a historical past object. The historical past object has a plot() technique that permits us to visualise the coaching and validation metrics by epoch:

The accuracy is plotted on the highest panel and the loss on the underside panel. Notice that your personal outcomes might fluctuate barely on account of a unique random initialization of your community.
As you possibly can see, the coaching loss decreases with each epoch, and the coaching accuracy will increase with each epoch. That’s what you’d anticipate when operating a gradient-descent optimization – the amount you’re making an attempt to attenuate needs to be much less with each iteration. However that isn’t the case for the validation loss and accuracy: they appear to peak on the fourth epoch. That is an instance of what we warned in opposition to earlier: a mannequin that performs higher on the coaching knowledge isn’t essentially a mannequin that may do higher on knowledge it has by no means seen earlier than. In exact phrases, what you’re seeing is overfitting: after the second epoch, you’re overoptimizing on the coaching knowledge, and you find yourself studying representations which might be particular to the coaching knowledge and don’t generalize to knowledge exterior of the coaching set.
On this case, to forestall overfitting, you may cease coaching after three epochs. Generally, you should utilize a spread of strategies to mitigate overfitting,which we’ll cowl in chapter 4.
Let’s practice a brand new community from scratch for 4 epochs after which consider it on the check knowledge.
mannequin <- keras_model_sequential() %>%
layer_dense(items = 16, activation = "relu", input_shape = c(10000)) %>%
layer_dense(items = 16, activation = "relu") %>%
layer_dense(items = 1, activation = "sigmoid")
mannequin %>% compile(
optimizer = "rmsprop",
loss = "binary_crossentropy",
metrics = c("accuracy")
)
mannequin %>% match(x_train, y_train, epochs = 4, batch_size = 512)
outcomes <- mannequin %>% consider(x_test, y_test)$loss
[1] 0.2900235
$acc
[1] 0.88512This pretty naive method achieves an accuracy of 88%. With state-of-the-art approaches, you need to be capable of get near 95%.
Producing predictions
After having skilled a community, you’ll wish to use it in a sensible setting. You possibly can generate the probability of opinions being optimistic through the use of the predict technique:
[1,] 0.92306918
[2,] 0.84061098
[3,] 0.99952853
[4,] 0.67913240
[5,] 0.73874789
[6,] 0.23108074
[7,] 0.01230567
[8,] 0.04898361
[9,] 0.99017477
[10,] 0.72034937As you possibly can see, the community is assured for some samples (0.99 or extra, or 0.01 or much less) however much less assured for others (0.7, 0.2).
Additional experiments
The next experiments will assist persuade you that the structure decisions you’ve made are all pretty affordable, though there’s nonetheless room for enchancment.
- You used two hidden layers. Attempt utilizing one or three hidden layers, and see how doing so impacts validation and check accuracy.
- Attempt utilizing layers with extra hidden items or fewer hidden items: 32 items, 64 items, and so forth.
- Attempt utilizing the
mseloss perform as an alternative ofbinary_crossentropy. - Attempt utilizing the
tanhactivation (an activation that was fashionable within the early days of neural networks) as an alternative ofrelu.
Wrapping up
Right here’s what you need to take away from this instance:
- You often have to do fairly a little bit of preprocessing in your uncooked knowledge so as to have the ability to feed it – as tensors – right into a neural community. Sequences of phrases might be encoded as binary vectors, however there are different encoding choices, too.
- Stacks of dense layers with
reluactivations can clear up a variety of issues (together with sentiment classification), and also you’ll possible use them incessantly. - In a binary classification drawback (two output lessons), your community ought to finish with a dense layer with one unit and a
sigmoidactivation: the output of your community needs to be a scalar between 0 and 1, encoding a likelihood. - With such a scalar sigmoid output on a binary classification drawback, the loss perform you need to use is
binary_crossentropy. - The
rmspropoptimizer is mostly a adequate selection, no matter your drawback. That’s one much less factor so that you can fear about. - As they get higher on their coaching knowledge, neural networks ultimately begin overfitting and find yourself acquiring more and more worse outcomes on knowledge they’ve
by no means seen earlier than. Remember to all the time monitor efficiency on knowledge that’s exterior of the coaching set.