


{kind=link}
Introduction
Named Entity Recognition (NER) is a job in pure language processing (NLP) that entails figuring out and classifying named entities in textual content into predefined classes similar to names of individuals, organizations, areas, dates, and so forth. Whereas Giant Language Fashions (LLMs) have gained vital consideration and achieved spectacular leads to numerous NLP duties, together with few-shot NER, it is essential to acknowledge that easier options have been out there for a while. These options often require much less compute to deploy and run, and thus decrease the price of adoption (learn: cheaper! Additionally see this MLOps Neighborhood Speak by Meryem Arik). On this blogpost, we’ll discover the issue of few-shot NER and the present state-of-the-art (SOTA) strategies for this downside.
What’s NER?
A named entity means something that may be referred to with a correct title, similar to an individual (Steven Spielberg) or a metropolis (Toronto). A textbook definition of NER is the duty of finding and classifying named entities with bigger spans of texts. The commonest varieties are:
- Individual: Aragorn
- Location: Lausanne
- Group: Clarifai
- Geo-political entity: World Well being Group

Picture above taken from What is called entity recognition (NER) and the way can I take advantage of it? by Christopher Marshall
NER is broadly adopted in business functions and is commonly used as a primary step in a variety of NLP duties. For instance:
- Buyer assist: An automatic system can establish the intent of an incoming request by utilizing NER and dispatch to the suitable staff.
- Well being care: Healthcare professionals can perceive stories rapidly by utilizing NER to extract related data.
There are a number of present approaches to NER.
- The best method is dictionary-based, which entails matching vocabulary from a group throughout the given textual content. Regardless of its simplicity, the scalability of this method is restricted because the dictionary is required to be maintained at any time when there are new vocabularies.
- Dominated-based approaches, similar to pattern-based guidelines and context-based guidelines, depend on morphological sample or the a part of speech of the phrases used.
- Machine Studying primarily based approaches try and be taught some feature-based illustration from the coaching knowledge, which overcomes the challenges of dictionary-based and rule-based approaches (e.g. spelling variations).
- With deep studying primarily based approaches, extra advanced relations could be discovered. Additionally time spent on function engineering could be prevented. Are usually extra data-hungry for the system to be taught nicely.
What’s Few-Shot NER?
Whereas there’s a plethora of pre-trained NER fashions which are readily-available within the open supply group, these fashions solely cowl the fundamental entity varieties, which regularly don’t cowl all potential use instances. In these eventualities, the checklist of entity varieties must be modified or prolonged to incorporate use-case-specific entity varieties like industrial product names or chemical compounds. Sometimes there’ll solely be a number of examples of what the specified output ought to seem like, and never an abundance of knowledge to coach fashions on. Few-Shot NER approaches goal to resolve this problem.
Coaching examples are wanted for the system to be taught new entity varieties. However typical deep studying strategies require a variety of coaching examples to do their job nicely. Coaching a deep neural community with only some examples would result in overfitting: the mannequin would merely memorize the few examples it has seen and at all times give the proper solutions on these, however wouldn’t obtain the tip aim of generalizing nicely to examples it has not encountered earlier than.
To beat this problem one can use a pre-trained mannequin that has been educated to do NER on a variety of general-domain knowledge labeled with generic entity varieties, and use the few out there domain-specific examples to adapt the bottom mannequin to the textual content area and entity kinds of curiosity. Beneath we describe a number of strategies which have been used to introduce the brand new information into the mannequin whereas avoiding extreme overfitting.
Strategies
Prototypical networks
Every knowledge level (in our case a token) is internally represented inside a deep studying mannequin as vectors. Prototype-based strategies had been first launched in a paper by Jake Snell et al. and investigated for few-shot NER by Jiaxin Huang et al.. When a assist set (the few out there in-domain examples that can be utilized to adapt the mannequin) is obtained, the pre-existing generic mannequin is first used to calculate a illustration vector for every token. It’s anticipated that the extra related the that means of a pair of phrases, the smaller the gap between their representations can be.
After acquiring the vectors, they’re grouped by entity sort (e.g. all Individual tokens), and the typical of all representations inside a gaggle is calculated. The ensuing vector is named a prototype, representing the entity sort as an entire.
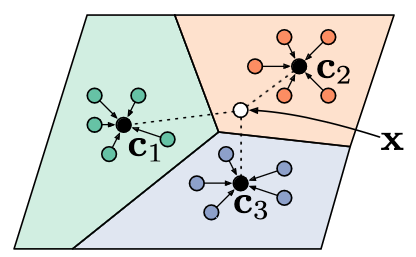
Prototypical networks within the few-shot situation. Prototypes are computed because the imply of assist instance vectors from every class (Snell et al., 2017)
When new knowledge is available in that the system must predict on, it might calculate token representations for the brand new sentence in the identical means. Within the easiest case, for every of the tokens it predicts the category of the prototype which is the closest to the vector of the token in query. When there are only some knowledge factors for coaching, the simplicity of this methodology helps to keep away from overfitting to them.
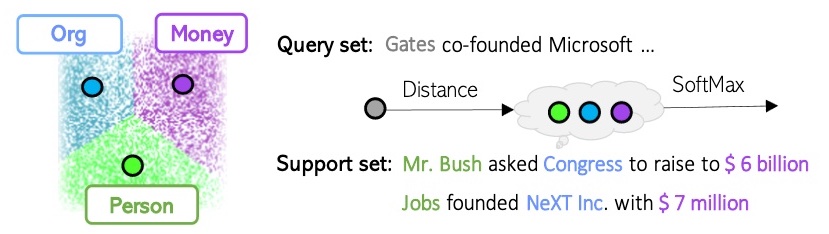
An illustration of a prototype-based methodology (Huang et al., 2021)
Variations of the prototype-based method embrace the work of Yi Yang and Arzoo Katiyar, which makes use of an instance-based as a substitute of a class-based metric. As a substitute of explicitly establishing a median prototype illustration for every class, this algorithm will merely calculate the gap from the token in query to every of the person tokens within the assist set, and predict the tag of essentially the most related assist token. This results in higher predictions of the O-class (the tokens that are not named entities).
This problem can also be handled in the paper by Meihan Tong et al., who suggest to be taught a number of prototypes for the totally different O-class phrases as a substitute of a single one to raised symbolize wealthy semantics.
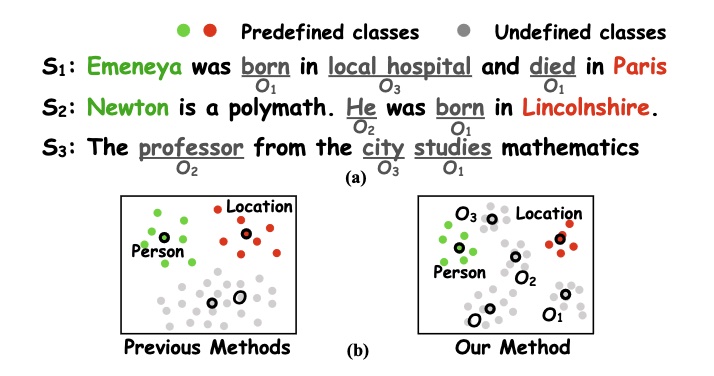
(a): Examples for undefined courses. (b): Other ways to deal with O class (single prototype vs. a number of prototypes) (Tong et al., 2021)
Contrastive studying
One other methodology typically used for few-shot NER is contrastive studying. The goal of contrastive studying is to symbolize knowledge inside a mannequin in such a means that related knowledge factors would have vectors which are shut to one another, and dissimilar knowledge factors could be additional aside. For NER, which means that throughout the means of adapting a mannequin to the brand new knowledge, tokens of the identical sort can be pushed collectively, whereas tokens of different varieties can be pulled aside. The contrastive studying method is utilized in the article by Sarkar Snigdha Sarathi Das et al. amongst a number of others.
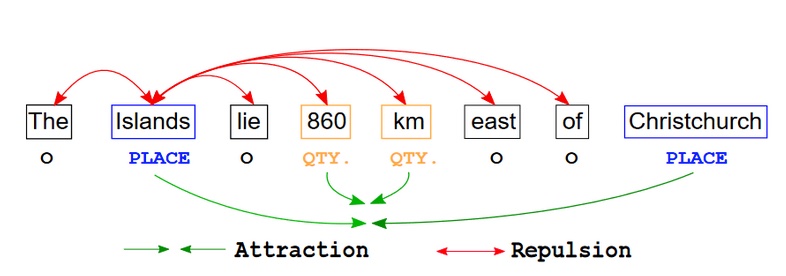
Contrastive studying dynamics of a token (Islands) in an instance sentence. Distance between tokens of the identical class is decreased (attraction), whereas distance between totally different classes is elevated (repulsion) (Das et al., 2022)
Meta-learning
The goal of meta-learning is to learn to be taught: a mannequin is educated on totally different duties such that it might adapt rapidly to a brand new job and a small variety of new coaching samples would suffice. Mannequin-agnostic meta-learning (MAML), launched by Finn et al., additionally trains the fashions to be simply and rapidly fine-tuned. It does so by aiming to seek out task-sensitive mannequin parameters: a small change to the parameters can considerably enhance efficiency on a brand new job.
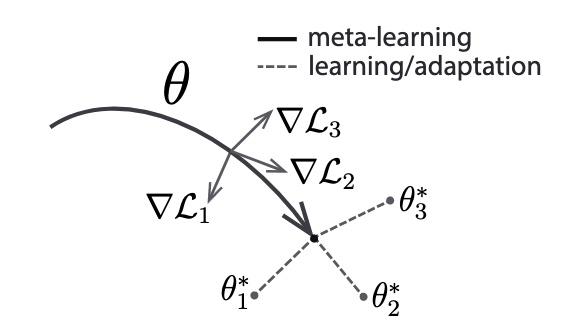
Diagram of the model-agnostic meta-learning algorithm (MAML), which optimizes for a illustration θ that may rapidly adapt to new duties (Finn et al., 2017)
An method by Ma et al. applies MAML to few-shot NER and makes use of it to seek out preliminary mannequin parameters that might simply adapt to new title id courses. It combines MAML with prototypical networks to realize SOTA outcomes on the Few-NERD dataset.
LLMs
Not too long ago, growing focus has been placed on LLMs. They’re used to resolve an increasing number of duties, and NER is just not an exception. Trendy LLMs are superb at studying from only some examples, which is definitely helpful in a few-shot setting.
Nonetheless, NER is a token-level labeling job (every particular person token in a sentence must be assigned a category), whereas LLMs are generative (they produce new textual content primarily based on a immediate). This has led researchers to research greatest use the skills of LLMs on this situation, the place explicitly querying the mannequin with templates many instances per sentence is impractical. For instance, the work of Ruotian Ma et al.tries to resolve this by prompting NER with out templates, fine-tuning a mannequin to foretell label phrases consultant of a category the place named entities seem within the textual content.
Not too long ago, GPT-NER by Shuhe Wang et al. proposed to rework the NER sequence labeling job (assigning courses to tokens) right into a era job (producing textual content), which ought to make it simpler to take care of for LLMs, and, specifically, GPT fashions. The article means that within the few-shot situation, when only some coaching examples can be found, GPT-NER is healthier than fashions educated utilizing supervised studying. Nonetheless, the supervised baseline doesn’t use any strategies particular to few-shot NER similar to ones talked about above, and it’s to be anticipated {that a} general-purpose mannequin educated on solely a handful of examples performs poorly. This leaves open questions for this explicit comparability.
Few-Shot NER Datasets
As in all synthetic intelligence duties, knowledge availability is an important consideration. Excessive-quality coaching knowledge is required to create the fashions, however no much less crucially, publicly out there high-quality take a look at knowledge is required to check the standard of various fashions and to judge the progress in a controllable, reproducible means.
Efficiency on few-shot NER was evaluated on subsets of in style NER datasets, e.g. by sampling 5 sentences from every entity sort in CoNLL 2003 as coaching examples. A complete analysis could be present in a research by Huang et al.
In 2021, Ding et al. launched Few-NERD (Few-shot Named Entity Recognition Dataset), a dataset particularly designed for the duty of few-shot NER. Named entities on this dataset are labeled with 8 coarse-grained entity varieties, that are additional divided into 66 fine-grained varieties. Every occasion sort (both coarse- or fine-grained) solely seems in one of many subsets: practice (used for coaching the mannequin), validation (used for assessing coaching progress), or take a look at (handled as unseen knowledge on which ends up are reported). This fashion, Few-NERD is turning into a well-liked selection for assessing the generalization and information switch talents of few-shot NER techniques.
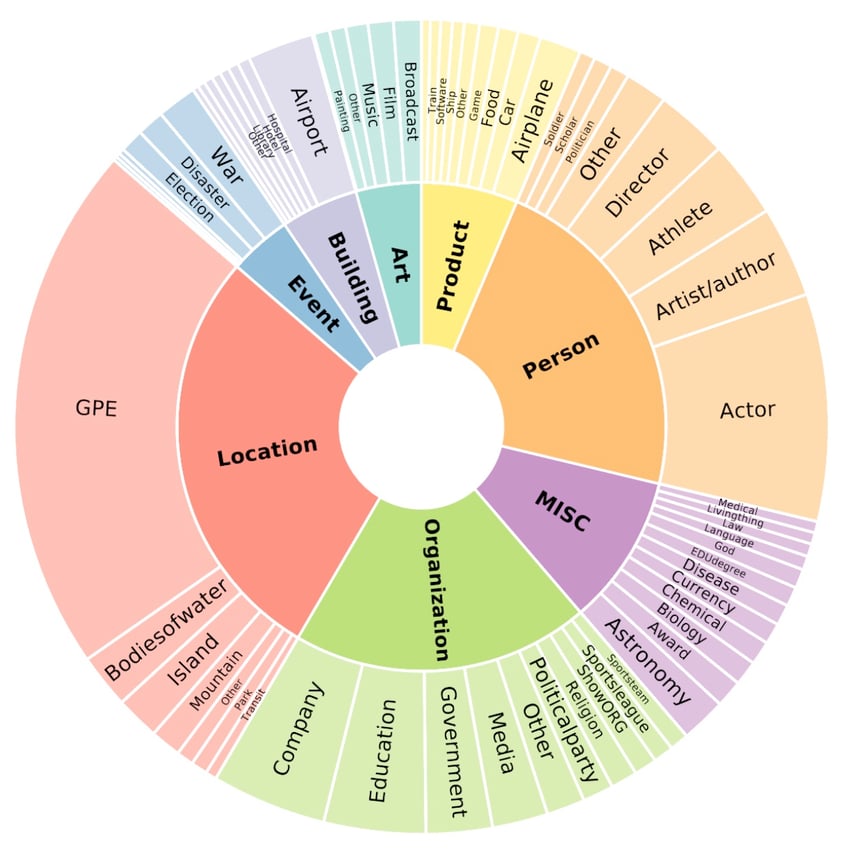
Coarse- and fine-grained entity varieties within the Few-NERD dataset (Ding et al., 2021)
Abstract
The primary problem of few-shot NER is studying from a small quantity of obtainable in-domain knowledge whereas retaining the flexibility to generalize to new knowledge. A couple of kinds of approaches, which we describe on this weblog put up, are utilized in analysis to resolve this downside. With the latest deal with LLMs, that are exceptionally robust few-shot learners, it definitely is thrilling to see future progress on few-shot NER benchmarks.
Check out one of many NER fashions on the Clarifai platform at present! Can’t discover what you want? Seek the advice of our Docs web page or ship us a message in our Neighborhood Slack Channel.