
{kind=link}

Picture by Editor
Information science is a discipline that has grown tremendously within the final hundred years due to developments made within the discipline of pc science. With pc and cloud storage prices getting cheaper, we are actually capable of retailer copious quantities of information at a really low price in contrast to some years in the past. With the rise in computational energy, we are able to run machine studying algorithms on giant units of information and churn it to supply insights. With developments in networking, we are able to generate and transmit knowledge over the web at lightning velocity. On account of all of this, we stay in an period with plentiful knowledge being generated each second. We’ve knowledge within the type of electronic mail, monetary transactions, social media content material, net pages on the web, buyer knowledge for companies, medical information of sufferers, health knowledge from smartwatches, video content material on Youtube, telemetry from smart-devices and the checklist goes on. This abundance of information each in structured and unstructured format has made us land in a discipline known as Information Mining.
Information Mining is the method of discovering patterns, anomalies, and correlations from giant knowledge units to foretell an final result. Whereas knowledge mining methods might be utilized to any type of knowledge, one such department of Information Mining is Textual content Mining which refers to discovering significant data from unstructured textual knowledge. On this paper, I’ll concentrate on a typical job in Textual content Mining to seek out Doc Similarity.
Doc Similarity helps in environment friendly data retrieval. Purposes of doc similarity embody – detecting plagiarism, answering net search queries successfully, clustering analysis papers by matter, discovering comparable information articles, clustering comparable questions in a Q&A website resembling Quora, StackOverflow, Reddit, and grouping product on Amazon based mostly on the outline, and so forth. Doc similarity can be utilized by firms like DropBox and Google Drive to keep away from storing duplicate copies of the identical doc thereby saving processing time and storage price.
There are a number of steps to computing doc similarity. Step one is to characterize the doc in a vector format. We will then use pairwise similarity capabilities on these vectors. A similarity perform is a perform that computes the diploma of similarity between a pair of vectors. There are a number of pairwise similarity capabilities resembling – Euclidean Distance, Cosine Similarity, Jaccard Similarity, Pearson’s correlation, Spearman’s correlation, Kendall’s Tau, and so forth [2]. A pairwise similarity perform may be utilized to 2 paperwork, two search queries, or between a doc and a search question. Whereas pairwise similarity capabilities go well with properly for evaluating a smaller variety of paperwork, there are different extra superior methods resembling Doc2Vec, BERT which might be based mostly on deep studying methods and are utilized by serps like Google for environment friendly data retrieval based mostly on the search question. On this paper, I’ll concentrate on Jaccard Similarity, Euclidean Distance, Cosine Similarity, Cosine Similarity with TF-IDF, Doc2Vec, and BERT.
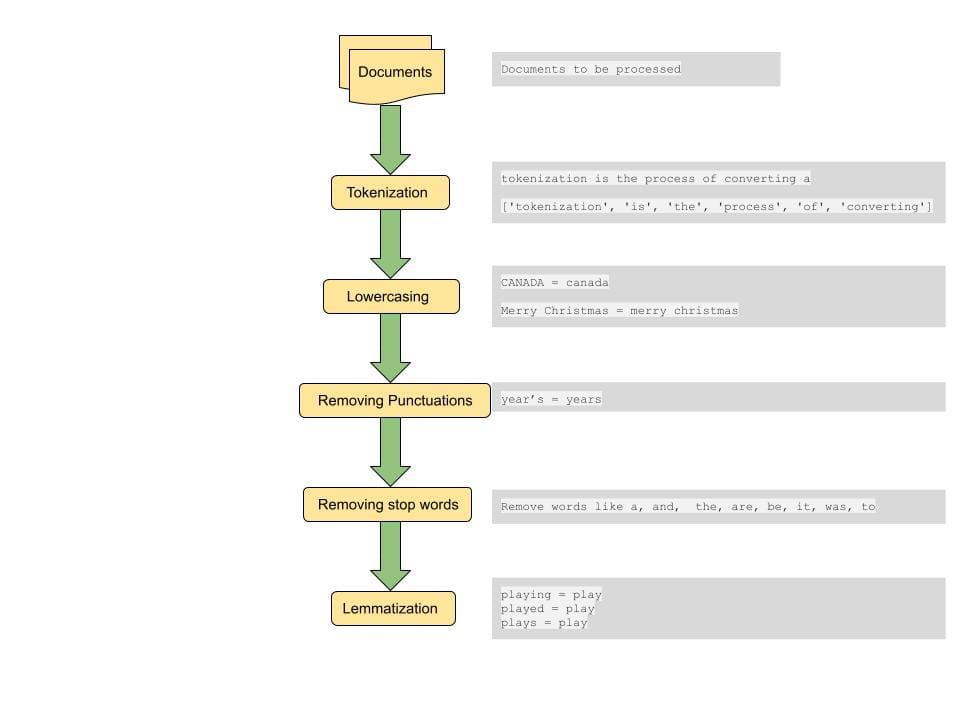
Pre-Processing
A standard step to computing distance between paperwork or similarities between paperwork is to do some pre-processing on the doc. The pre-processing step contains changing all textual content to lowercase, tokenizing the textual content, eradicating cease phrases, eradicating punctuations and lemmatizing phrases[4].
Tokenization: This step includes breaking down the sentences into smaller items for processing. A token is a smallest lexical atom {that a} sentence may be damaged down into. A sentence may be damaged down into tokens through the use of house as a delimiter. That is a method of tokenizing. For instance, a sentence of the shape “tokenization is a extremely cool step” is damaged into tokens of the shape [‘tokenization’, ‘is’, a, ‘really’, ‘cool’, ‘step’]. These tokens kind the constructing blocks of Textual content Mining and are one of many first steps in modeling textual knowledge..
Lowercasing: Whereas preserving circumstances is likely to be wanted in some particular circumstances, usually we wish to deal with phrases with completely different casing as one. This step is essential to be able to get constant outcomes from a big knowledge set. For instance if a person is looking for a phrase ‘india’, we wish to retrieve related paperwork that comprise phrases in numerous casing both as “India”, “INDIA” and “india” if they’re related to the search question.
Eradicating Punctuations: Eradicating punctuation marks and whitespaces assist focus the search on essential phrases and tokens.
Eradicating cease phrases: Cease phrases are a set of phrases which might be generally used within the English language and elimination of such phrases may help in retrieving paperwork that match extra essential phrases that convey the context of the question. This additionally helps in lowering the scale of the function vector thereby serving to with processing time.
Lemmatization: Lemmatization helps in lowering sparsity by mapping phrases to their root phrase.For instance ‘Performs’, ‘Performed’ and ‘Enjoying’ are all mapped to play. By doing this we additionally scale back the scale of the function set and match all variations of a phrase throughout completely different paperwork to deliver up essentially the most related doc.
This methodology is without doubt one of the best strategies. It tokenizes the phrases and calculates the sum of the depend of the shared phrases to the sum of the full variety of phrases in each paperwork. If the 2 paperwork are comparable the rating is one, if the 2 paperwork are completely different the rating is zero [3].
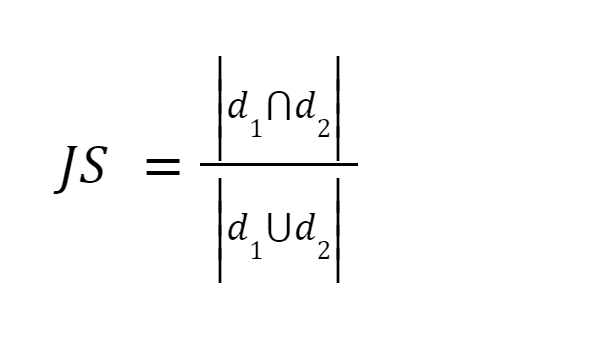
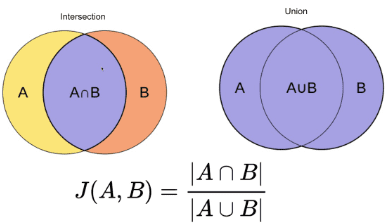
Picture supply: O’Reilly
Abstract: This methodology has some drawbacks. As the scale of the doc will increase, the variety of frequent phrases will enhance, regardless that the 2 paperwork are semantically completely different.
After pre-processing the doc, we convert the doc right into a vector. The load of the vector can both be the time period frequency the place we depend the variety of instances the time period seems within the doc, or it may be the relative time period frequency the place we compute the ratio of the depend of the time period to the full variety of phrases within the doc [3].
Let d1 and d2 be two paperwork represented as vectors of n phrases (representing n dimensions); we are able to then compute the shortest distance between two paperwork utilizing the pythagorean theorem to discover a straight line between two vectors. The larger the gap, the decrease the similarity;the decrease the gap, the upper the similarity between two paperwork.
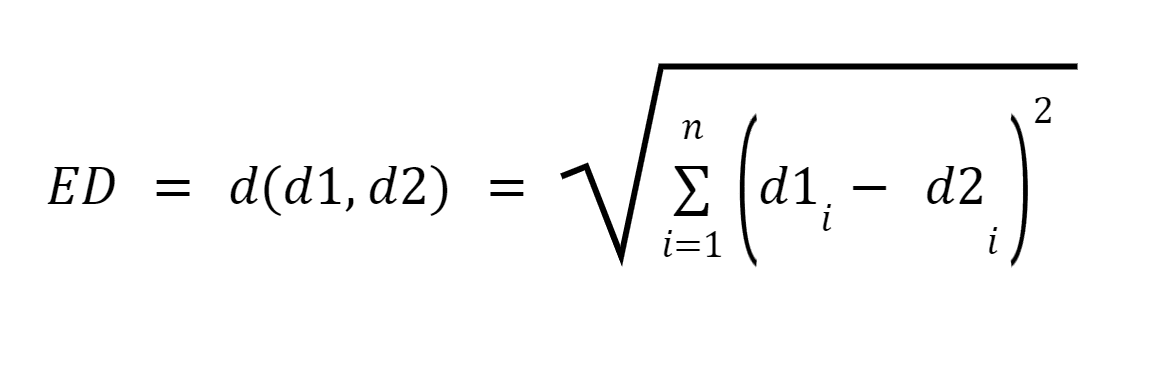
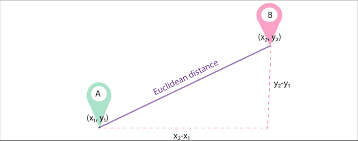
Picture Supply: Medium.com
Abstract: Main disadvantage of this strategy is that when the paperwork are differing in measurement, Euclidean Distance will give a decrease rating regardless that the 2 paperwork are comparable in nature. Smaller paperwork will lead to vectors with a smaller magnitude and bigger paperwork will lead to vectors with bigger magnitude because the magnitude of the vector is instantly proportional to the variety of phrases within the doc, thereby making the general distance bigger.
Cosine similarity measures the similarity between paperwork by measuring the cosine of the angle between the 2 vectors. Cosine similarity outcomes can take worth between 0 and 1. If the vectors level in the identical path, the similarity is 1, if the vectors level in reverse instructions, the similarity is 0. [6].
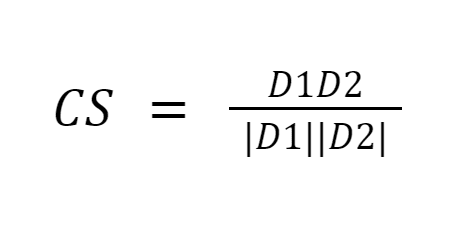
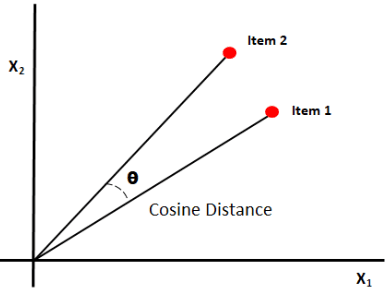
Picture Supply: Medium.com
Abstract: The advantage of cosine similarity is that it computes the orientation between vectors and never the magnitude. Thus it is going to seize similarity between two paperwork which might be comparable regardless of being completely different in measurement.
The elemental disadvantage of the above three approaches is that the measurement misses out on discovering comparable paperwork by semantics. Additionally, all of those methods can solely be completed pairwise, thus requiring extra comparisons .
This methodology of discovering doc similarity is utilized in default search implementations of ElasticSearch and it has been round since 1972 [4]. tf-idf stands for time period frequency-inverse doc frequency. We first compute the time period frequency utilizing this components
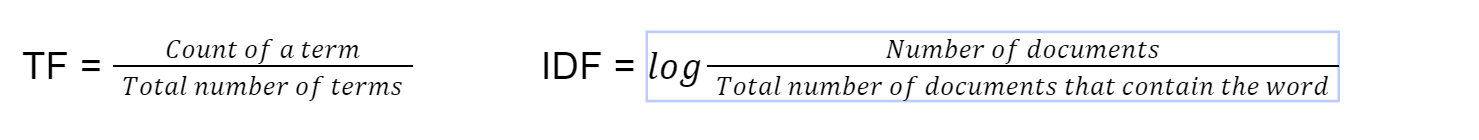
Lastly we compute tf-idf by multiplying TF*IDF. We then use cosine similarity on the vector with tf-idf as the load of the vector.
Abstract: Multiplying the time period frequency with the inverse doc frequency helps offset some phrases which seem extra regularly generally throughout paperwork and concentrate on phrases that are completely different between paperwork. This method helps find paperwork that match a search question by focussing the search on essential key phrases.
Though utilizing particular person phrases (BOW – Bag of Phrases) from paperwork to transform to vectors is likely to be simpler to implement, it doesn’t give any significance to the order of phrases in a sentence. Doc2Vec is constructed on high of Word2Vec. Whereas Word2Vec represents the which means of a phrase, Doc2Vec represents the which means of a doc or paragraph [5].
This methodology is used for changing a doc into its vector illustration whereas preserving the semantic which means of the doc. This strategy converts variable-length texts resembling sentences or paragraphs or paperwork to vectors [5]. The doc2vec mode is then skilled. The coaching of the fashions is just like coaching different machine studying fashions by selecting coaching units and take a look at set paperwork and adjusting the tuning parameters to realize higher outcomes.
Abstract: Such a vectorised type of the doc preserves the semantic which means of the doc as paragraphs with comparable context or which means will likely be nearer collectively whereas changing to vector.
BERT is a transformer based mostly machine studying mannequin utilized in NLP duties, developed by Google.
With the arrival of BERT (Bidirectional Encoder Representations from Transformers), NLP fashions are skilled with enormous, unlabeled textual content corpora which seems to be at a textual content each from proper to left and left to proper. BERT makes use of a method known as “Consideration” to enhance outcomes. Google’s search rating improved by an enormous margin after utilizing BERT [4]. A few of the distinctive options of BERT embody
- Pre-trained with Wikipedia articles from 104 languages.
- Appears to be like at textual content each left to proper and proper to left
- Helps in understanding context
Abstract: Consequently, BERT may be fine-tuned for lots of functions resembling question-answering, sentence paraphrasing, Spam Classifier, Construct language detector with out substantial task-specific structure modifications.
It was nice to study how similarity capabilities are utilized in discovering doc similarity. At the moment it’s as much as to the developer to select a similarity perform that most accurately fits the state of affairs. For instance tf-idf is at the moment the cutting-edge for matching paperwork whereas BERT is the cutting-edge for question searches. It might be nice to construct a instrument that auto-detects which similarity perform is finest suited based mostly on the state of affairs and thus choose a similarity perform that’s optimized for reminiscence and processing time. This might tremendously assist in situations like auto-matching resumes to job descriptions, clustering paperwork by class, classifying sufferers to completely different classes based mostly on affected person medical information and so forth.
On this paper, I lined some notable algorithms to calculate doc similarity. It’s no method an exhaustive checklist. There are a number of different strategies for locating doc similarity and the choice to select the suitable one is dependent upon the actual state of affairs and use-case. Easy statistical strategies like tf-idf, Jaccard, Euclidien, Cosine similarity are properly suited to easier use-cases. One can simply get setup with current libraries accessible in Python, R and calculate the similarity rating with out requiring heavy machines or processing capabilities. Extra superior algorithms like BERT rely upon pre-training neural networks that may take hours however produce environment friendly outcomes for evaluation requiring understanding of the context of the doc.
Reference
[1] Heidarian, A., & Dinneen, M. J. (2016). A Hybrid Geometric Strategy for Measuring Similarity Degree Amongst Paperwork and Doc Clustering. 2016 IEEE Second Worldwide Convention on Huge Information Computing Service and Purposes (BigDataService), 1–5. https://doi.org/10.1109/bigdataservice.2016.14
[2] Kavitha Karun A, Philip, M., & Lubna, Okay. (2013). Comparative evaluation of similarity measures in doc clustering. 2013 Worldwide Convention on Inexperienced Computing, Communication and Conservation of Vitality (ICGCE), 1–4. https://doi.org/10.1109/icgce.2013.6823554
[3] Lin, Y.-S., Jiang, J.-Y., & Lee, S.-J. (2014). A Similarity Measure for Textual content Classification and Clustering. IEEE Transactions on Data and Information Engineering, 26(7), 1575–1590. https://doi.org/10.1109/tkde.2013.19
[4] Nishimura, M. (2020, September 9). The Greatest Doc Similarity Algorithm in 2020: A Newbie’s Information – In the direction of Information Science. Medium. https://towardsdatascience.com/the-best-document-similarity-algorithm-in-2020-a-beginners-guide-a01b9ef8cf05
[5] Sharaki, O. (2020, July 10). Detecting Doc Similarity With Doc2vec – In the direction of Information Science. Medium. https://towardsdatascience.com/detecting-document-similarity-with-doc2vec-f8289a9a7db7
[6] Lüthe, M. (2019, November 18). Calculate Similarity — essentially the most related Metrics in a Nutshell – In the direction of Information Science. Medium. https://towardsdatascience.com/calculate-similarity-the-most-relevant-metrics-in-a-nutshell-9a43564f533e
[7] S. (2019, October 27). Similarity Measures — Scoring Textual Articles – In the direction of Information Science. Medium. https://towardsdatascience.com/similarity-measures-e3dbd4e58660
Poornima Muthukumar is a Senior Technical Product Supervisor at Microsoft with over 10 years of expertise in creating and delivering progressive options for varied domains resembling cloud computing, synthetic intelligence, distributed and massive knowledge methods. I’ve a Grasp’s Diploma in Information Science from the College of Washington. I maintain 4 Patents at Microsoft specializing in AI/ML and Huge Information Methods and was the winner of the World Hackathon in 2016 within the Synthetic Intelligence Class. I used to be honored to be on the Grace Hopper Convention reviewing panel for the Software program Engineering class this yr 2023. It was a rewarding expertise to learn and consider the submissions from proficient girls in these fields and contribute to the development of girls in expertise, in addition to to be taught from their analysis and insights. I used to be additionally a committee member for the Microsoft Machine Studying AI and Information Science (MLADS) June 2023 convention. I’m additionally an Ambassador on the Girls in Information Science Worldwide Group and Girls Who Code Information Science Group.