
{kind=link}

Photograph by Roberto Nickson
Web of Automobiles, or IoV, is the product of the wedding between the automotive business and IoT. IoV knowledge is predicted to get bigger and bigger, particularly with electrical automobiles being the brand new progress engine of the auto market. The query is: Is your knowledge platform prepared for that? This publish exhibits you what an OLAP resolution for IoV appears like.
The thought of IoV is intuitive: to create a community so automobiles can share data with one another or with city infrastructure. What‘s usually under-explained is the community inside every automobile itself. On every automobile, there’s something known as Controller Space Community (CAN) that works because the communication middle for the digital management programs. For a automobile touring on the street, the CAN is the assure of its security and performance, as a result of it’s liable for:
- Automobile system monitoring: The CAN is the heartbeat of the automobile system. For instance, sensors ship the temperature, strain, or place they detect to the CAN; controllers problem instructions (like adjusting the valve or the drive motor) to the executor through the CAN.
- Actual-time suggestions: By way of the CAN, sensors ship the pace, steering angle, and brake standing to the controllers, which make well timed changes to the automobile to make sure security.
- Knowledge sharing and coordination: The CAN permits for knowledge alternate (similar to standing and instructions) between varied gadgets, so the entire system could be extra performant and environment friendly.
- Community administration and troubleshooting: The CAN retains an eye fixed on gadgets and parts within the system. It acknowledges, configures, and screens the gadgets for upkeep and troubleshooting.
With the CAN being that busy, you may think about the info measurement that’s touring by the CAN daily. Within the case of this publish, we’re speaking a couple of automobile producer who connects 4 million automobiles collectively and has to course of 100 billion items of CAN knowledge daily.
To show this big knowledge measurement into worthwhile data that guides product growth, manufacturing, and gross sales is the juicy half. Like most knowledge analytic workloads, this comes all the way down to knowledge writing and computation, that are additionally the place challenges exist:
- Knowledge writing at scale: Sensors are all over the place in a automobile: doorways, seats, brake lights… Plus, many sensors accumulate a couple of sign. The 4 million automobiles add up to an information throughput of thousands and thousands of TPS, which implies dozens of terabytes daily. With rising automobile gross sales, that quantity continues to be rising.
- Actual-time evaluation: That is maybe one of the best manifestation of “time is life”. Automobile producers accumulate the real-time knowledge from their automobiles to establish potential malfunctions, and repair them earlier than any harm occurs.
- Low-cost computation and storage: It is exhausting to speak about big knowledge measurement with out mentioning its prices. Low price makes large knowledge processing sustainable.
Like Rome, a real-time knowledge processing platform is just not in-built a day. The automobile producer used to depend on the mix of a batch analytic engine (Apache Hive) and a few streaming frameworks and engines (Apache Flink, Apache Kafka) to achieve close to real-time knowledge evaluation efficiency. They did not notice they wanted real-time that unhealthy till real-time was an issue.
Close to Actual-Time Knowledge Evaluation Platform
That is what used to work for them:
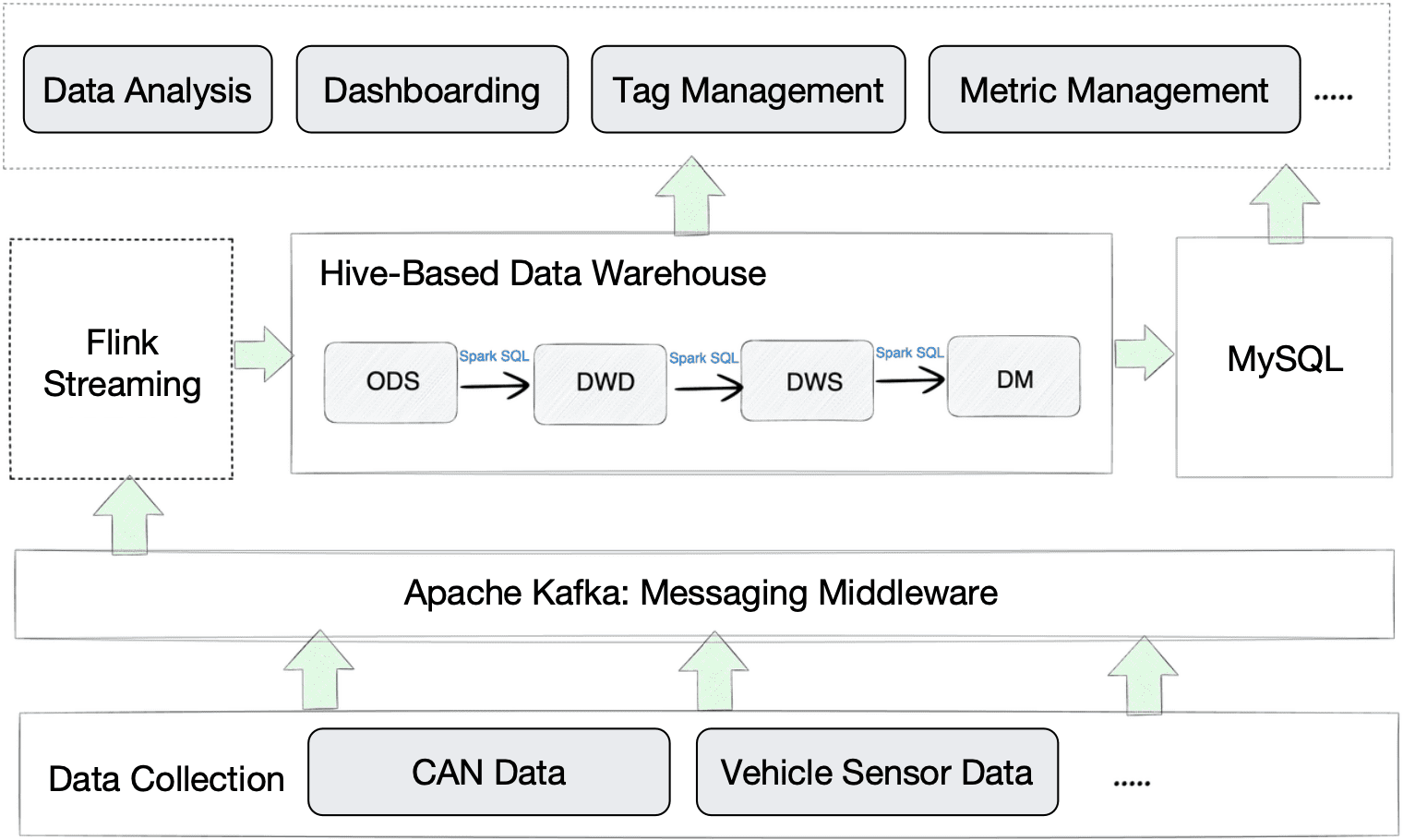
Knowledge from the CAN and automobile sensors are uploaded through 4G community to the cloud gateway, which writes the info into Kafka. Then, Flink processes this knowledge and forwards it to Hive. Going by a number of knowledge warehousing layers in Hive, the aggregated knowledge is exported to MySQL. On the finish, Hive and MySQL present knowledge to the appliance layer for knowledge evaluation, dashboarding, and so on.
Since Hive is primarily designed for batch processing reasonably than real-time analytics, you may inform the mismatch of it on this use case.
- Knowledge writing: With such an enormous knowledge measurement, the info ingestion time from Flink into Hive was noticeably lengthy. As well as, Hive solely helps knowledge updating on the granularity of partitions, which isn’t sufficient for some circumstances.
- Knowledge evaluation: The Hive-based analytic resolution delivers excessive question latency, which is a multi-factor problem. Firstly, Hive was slower than anticipated when dealing with giant tables with 1 billion rows. Secondly, inside Hive, knowledge is extracted from one layer to a different by the execution of Spark SQL, which may take some time. Thirdly, as Hive must work with MySQL to serve all wants from the appliance facet, knowledge switch between Hive and MySQL additionally provides to the question latency.
Actual-Time Knowledge Evaluation Platform
That is what occurs after they add a real-time analytic engine to the image:
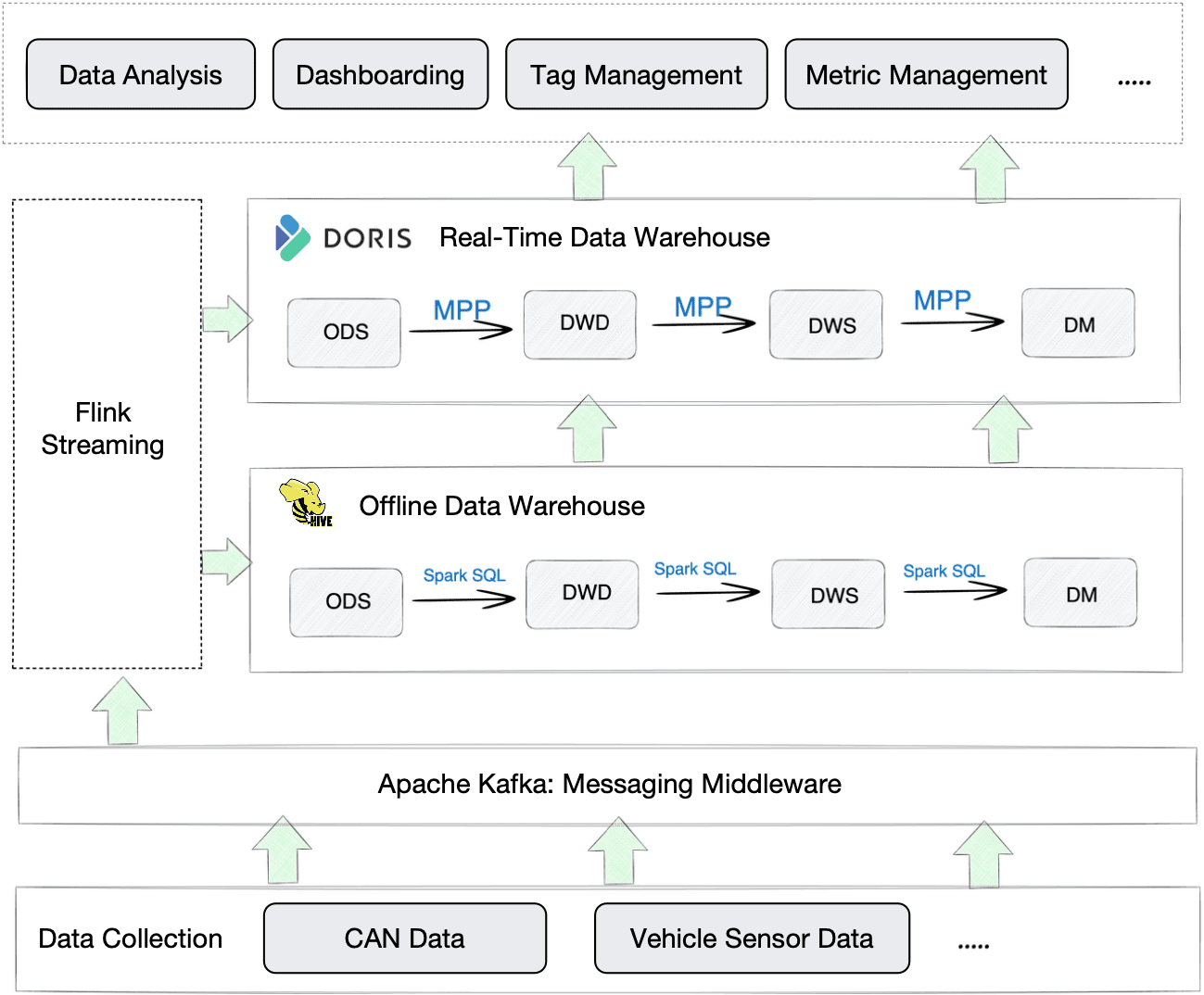
In comparison with the outdated Hive-based platform, this new one is extra environment friendly in 3 ways:
- Knowledge writing: Knowledge ingestion into Apache Doris is fast and simple, with out difficult configurations and the introduction of additional parts. It helps quite a lot of knowledge ingestion strategies. For instance, on this case, knowledge is written from Kafka into Doris through Stream Load, and from Hive into Doris through Dealer Load.
- Knowledge evaluation: To showcase the question pace of Apache Doris by instance, it will probably return a 10-million-row consequence set inside seconds in a cross-table be a part of question. Additionally, it will probably work as a unified question gateway with its fast entry to exterior knowledge (Hive, MySQL, Iceberg, and so on.), so analysts do not must juggle between a number of parts.
- Computation and storage prices: Apache Doris makes use of the Z-Customary algorithm that may carry a 3~5 occasions larger knowledge compression ratio. That is the way it helps scale back prices in knowledge computation and storage. Furthermore, the compression could be finished solely in Doris so it will not devour sources from Flink.
A great real-time analytic resolution not solely stresses knowledge processing pace, it additionally considers all the best way alongside your knowledge pipeline and smoothens each step of it. Listed here are two examples:
1. The association of CAN knowledge
In Kafka, CAN knowledge was organized by the dimension of CAN ID. Nonetheless, for the sake of knowledge evaluation, analysts needed to examine alerts from varied automobiles, which meant to concatenate knowledge of various CAN ID right into a flat desk and align it by timestamp. From that flat desk, they might derive completely different tables for various analytic functions. Such transformation was carried out utilizing Spark SQL, which was time-consuming within the outdated Hive-based structure, and the SQL statements are high-maintenance. Furthermore, the info was up to date by batch each day, which meant they might solely get knowledge from a day in the past.
In Apache Doris, all they want is to construct the tables with the Combination Key mannequin, specify VIN (Automobile Identification Quantity) and timestamp because the Combination Key, and outline different knowledge fields by REPLACE_IF_NOT_NULL. With Doris, they do not must maintain the SQL statements or the flat desk, however are capable of extract real-time insights from real-time knowledge.

3. DTC knowledge question
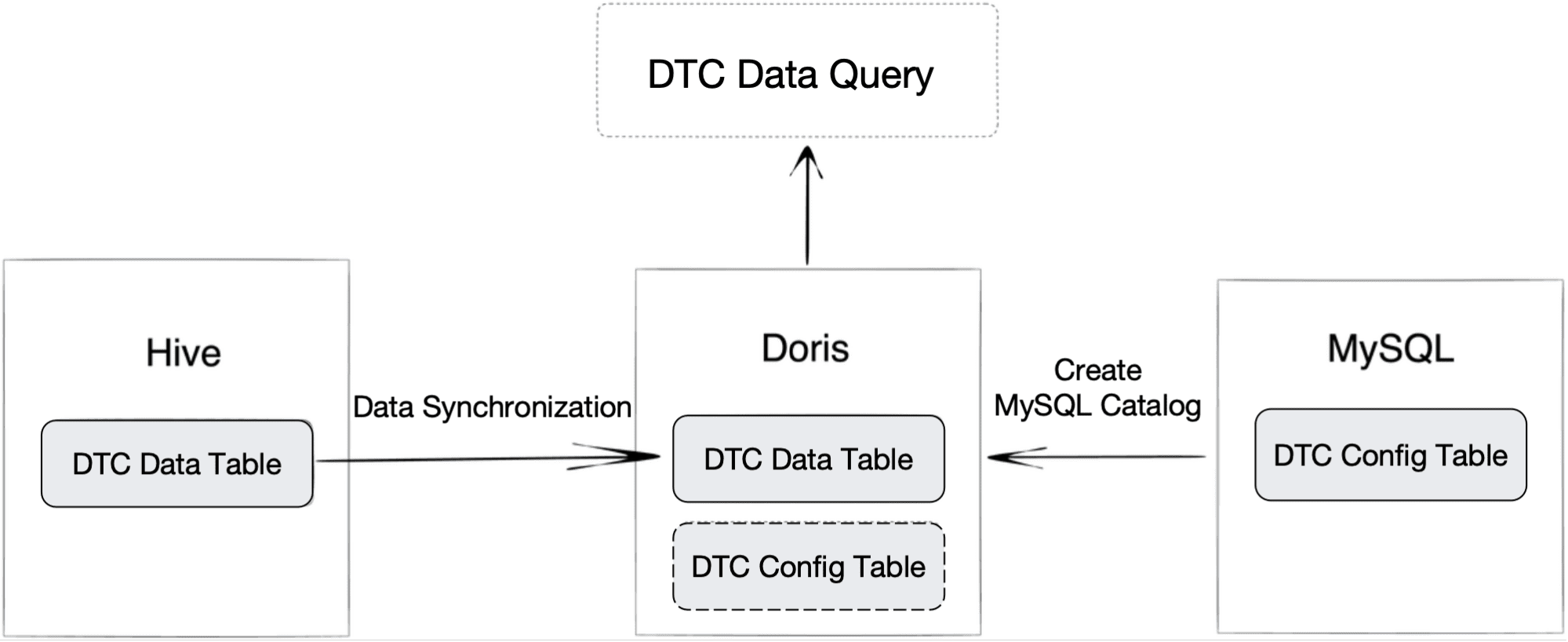
Of all CAN knowledge, DTC (Diagnostic Hassle Code) deserves excessive consideration and separate storage, as a result of it tells you what is improper with a automobile. Every day, the producer receives round 1 billion items of DTC. To seize life-saving data from the DTC, knowledge engineers must relate the DTC knowledge to a DTC configuration desk in MySQL.
What they used to do was to jot down the DTC knowledge into Kafka daily, course of it in Flink, and retailer the leads to Hive. On this manner, the DTC knowledge and the DTC configuration desk had been saved in two completely different parts. That prompted a dilemma: a 1-billion-row DTC desk was exhausting to jot down into MySQL, whereas querying from Hive was gradual. Because the DTC configuration desk was additionally consistently up to date, engineers may solely import a model of it into Hive frequently. That meant they did not at all times get to narrate the DTC knowledge to the most recent DTC configurations.
As is talked about, Apache Doris can work as a unified question gateway. That is supported by its Multi-Catalog characteristic. They import their DTC knowledge from Hive into Doris, after which they create a MySQL Catalog in Doris to map to the DTC configuration desk in MySQL. When all that is finished, they’ll merely be a part of the 2 tables inside Doris and get real-time question response.
That is an precise real-time analytic resolution for IoV. It’s designed for knowledge at actually giant scale, and it’s now supporting a automobile producer who receives 10 billion rows of latest knowledge daily in enhancing driving security and expertise.
Constructing an information platform to fit your use case is just not straightforward, I hope this publish helps you in constructing your individual analytic resolution.
Zaki Lu is a former product supervisor at Baidu and now DevRel for the Apache Doris open supply group.