
{kind=link}
The tfruns bundle supplies a set of instruments for monitoring, visualizing, and managing TensorFlow coaching runs and experiments from R. Use the tfruns bundle to:
-
Observe the hyperparameters, metrics, output, and supply code of each coaching run.
-
Evaluate hyperparmaeters and metrics throughout runs to seek out one of the best performing mannequin.
-
Routinely generate reviews to visualise particular person coaching runs or comparisons between runs.
You’ll be able to set up the tfruns bundle from GitHub as follows:
devtools::install_github("rstudio/tfruns")Full documentation for tfruns is on the market on the TensorFlow for R web site.
tfruns is meant for use with the keras and/or the tfestimators packages, each of which give larger stage interfaces to TensorFlow from R. These packages could be put in with:
# keras
set up.packages("keras")
# tfestimators
devtools::install_github("rstudio/tfestimators")Coaching
Within the following sections we’ll describe the assorted capabilities of tfruns. Our instance coaching script (mnist_mlp.R) trains a Keras mannequin to acknowledge MNIST digits.
To coach a mannequin with tfruns, simply use the training_run() perform rather than the supply() perform to execute your R script. For instance:
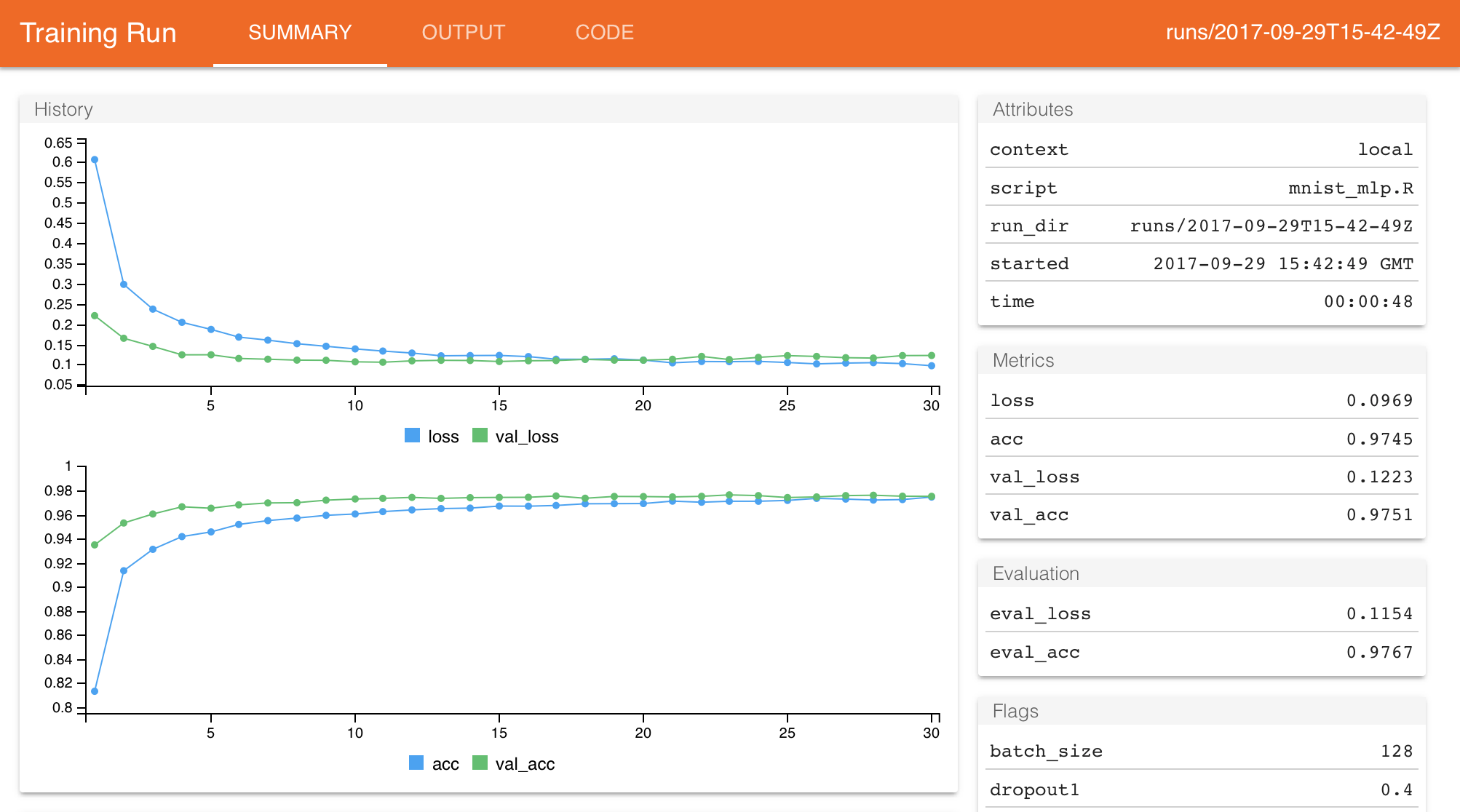
When coaching is accomplished, a abstract of the run will mechanically be displayed in case you are inside an interactive R session:

The metrics and output of every run are mechanically captured inside a run listing which is exclusive for every run that you simply provoke. Be aware that for Keras and TF Estimator fashions this information is captured mechanically (no modifications to your supply code are required).
You’ll be able to name the latest_run() perform to view the outcomes of the final run (together with the trail to the run listing which shops all the run’s output):
$ run_dir : chr "runs/2017-10-02T14-23-38Z"
$ eval_loss : num 0.0956
$ eval_acc : num 0.98
$ metric_loss : num 0.0624
$ metric_acc : num 0.984
$ metric_val_loss : num 0.0962
$ metric_val_acc : num 0.98
$ flag_dropout1 : num 0.4
$ flag_dropout2 : num 0.3
$ samples : int 48000
$ validation_samples: int 12000
$ batch_size : int 128
$ epochs : int 20
$ epochs_completed : int 20
$ metrics : chr "(metrics information body)"
$ mannequin : chr "(mannequin abstract)"
$ loss_function : chr "categorical_crossentropy"
$ optimizer : chr "RMSprop"
$ learning_rate : num 0.001
$ script : chr "mnist_mlp.R"
$ begin : POSIXct[1:1], format: "2017-10-02 14:23:38"
$ finish : POSIXct[1:1], format: "2017-10-02 14:24:24"
$ accomplished : logi TRUE
$ output : chr "(script ouptut)"
$ source_code : chr "(supply archive)"
$ context : chr "native"
$ sort : chr "coaching"The run listing used within the instance above is “runs/2017-10-02T14-23-38Z”. Run directories are by default generated throughout the “runs” subdirectory of the present working listing, and use a timestamp because the identify of the run listing. You’ll be able to view the report for any given run utilizing the view_run() perform:
view_run("runs/2017-10-02T14-23-38Z")Evaluating Runs
Let’s make a few modifications to our coaching script to see if we are able to enhance mannequin efficiency. We’ll change the variety of items in our first dense layer to 128, change the learning_rate from 0.001 to 0.003 and run 30 somewhat than 20 epochs. After making these modifications to the supply code we re-run the script utilizing training_run() as earlier than:
training_run("mnist_mlp.R")This will even present us a report summarizing the outcomes of the run, however what we’re actually fascinated about is a comparability between this run and the earlier one. We are able to view a comparability by way of the compare_runs() perform:

The comparability report exhibits the mannequin attributes and metrics side-by-side, in addition to variations within the supply code and output of the coaching script.
Be aware that compare_runs() will by default examine the final two runs, nevertheless you possibly can go any two run directories you wish to be in contrast.
Utilizing Flags
Tuning a mannequin typically requires exploring the impression of modifications to many hyperparameters. One of the simplest ways to method that is usually not by altering the supply code of the coaching script as we did above, however as a substitute by defining flags for key parameters you could wish to differ. Within the instance script you possibly can see that we now have finished this for the dropout layers:
FLAGS <- flags(
flag_numeric("dropout1", 0.4),
flag_numeric("dropout2", 0.3)
)These flags are then used within the definition of our mannequin right here:
mannequin <- keras_model_sequential()
mannequin %>%
layer_dense(items = 128, activation = 'relu', input_shape = c(784)) %>%
layer_dropout(fee = FLAGS$dropout1) %>%
layer_dense(items = 128, activation = 'relu') %>%
layer_dropout(fee = FLAGS$dropout2) %>%
layer_dense(items = 10, activation = 'softmax')As soon as we’ve outlined flags, we are able to go alternate flag values to training_run() as follows:
training_run('mnist_mlp.R', flags = c(dropout1 = 0.2, dropout2 = 0.2))You aren’t required to specify all the flags (any flags excluded will merely use their default worth).
Flags make it very easy to systematically discover the impression of modifications to hyperparameters on mannequin efficiency, for instance:
Flag values are mechanically included in run information with a “flag_” prefix (e.g. flag_dropout1, flag_dropout2).
See the article on coaching flags for added documentation on utilizing flags.
Analyzing Runs
We’ve demonstrated visualizing and evaluating one or two runs, nevertheless as you accumulate extra runs you’ll usually wish to analyze and examine runs many runs. You should utilize the ls_runs() perform to yield a knowledge body with abstract info on all the runs you’ve performed inside a given listing:
# A tibble: 6 x 27
run_dir eval_loss eval_acc metric_loss metric_acc metric_val_loss
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 runs/2017-10-02T14-56-57Z 0.1263 0.9784 0.0773 0.9807 0.1283
2 runs/2017-10-02T14-56-04Z 0.1323 0.9783 0.0545 0.9860 0.1414
3 runs/2017-10-02T14-55-11Z 0.1407 0.9804 0.0348 0.9914 0.1542
4 runs/2017-10-02T14-51-44Z 0.1164 0.9801 0.0448 0.9882 0.1396
5 runs/2017-10-02T14-37-00Z 0.1338 0.9750 0.1097 0.9732 0.1328
6 runs/2017-10-02T14-23-38Z 0.0956 0.9796 0.0624 0.9835 0.0962
# ... with 21 extra variables: metric_val_acc <dbl>, flag_dropout1 <dbl>,
# flag_dropout2 <dbl>, samples <int>, validation_samples <int>, batch_size <int>,
# epochs <int>, epochs_completed <int>, metrics <chr>, mannequin <chr>, loss_function <chr>,
# optimizer <chr>, learning_rate <dbl>, script <chr>, begin <dttm>, finish <dttm>,
# accomplished <lgl>, output <chr>, source_code <chr>, context <chr>, sort <chr>Since ls_runs() returns a knowledge body you may as well render a sortable, filterable model of it inside RStudio utilizing the View() perform:

The ls_runs() perform additionally helps subset and order arguments. For instance, the next will yield all runs with an eval accuracy higher than 0.98:
ls_runs(eval_acc > 0.98, order = eval_acc)You’ll be able to go the outcomes of ls_runs() to match runs (which is able to all the time examine the primary two runs handed). For instance, it will examine the 2 runs that carried out greatest when it comes to analysis accuracy:
compare_runs(ls_runs(eval_acc > 0.98, order = eval_acc))
RStudio IDE
When you use RStudio with tfruns, it’s strongly really helpful that you simply replace to the present Preview Launch of RStudio v1.1, as there are are numerous factors of integration with the IDE that require this newer launch.
Addin
The tfruns bundle installs an RStudio IDE addin which supplies fast entry to often used features from the Addins menu:

Be aware that you should use Instruments -> Modify Keyboard Shortcuts inside RStudio to assign a keyboard shortcut to a number of of the addin instructions.
Background Coaching
RStudio v1.1 features a Terminal pane alongside the Console pane. Since coaching runs can grow to be fairly prolonged, it’s typically helpful to run them within the background with a view to maintain the R console free for different work. You are able to do this from a Terminal as follows:

In case you are not operating inside RStudio then you possibly can after all use a system terminal window for background coaching.
Publishing Studies
Coaching run views and comparisons are HTML paperwork which could be saved and shared with others. When viewing a report inside RStudio v1.1 it can save you a replica of the report or publish it to RPubs or RStudio Join:

In case you are not operating inside RStudio then you should use the save_run_view() and save_run_comparison() features to create standalone HTML variations of run reviews.
Managing Runs
There are a selection of instruments accessible for managing coaching run output, together with:
-
Exporting run artifacts (e.g. saved fashions).
-
Copying and purging run directories.
-
Utilizing a customized run listing for an experiment or different set of associated runs.
The Managing Runs article supplies further particulars on utilizing these options.