
{kind=link}
The big Language Mannequin (LLM) has modified the best way individuals work. With a mannequin such because the GPT household that’s used broadly, everybody has gotten used to those fashions. Leveraging the LLM energy, we will rapidly get our questions answered, debugging code, and others. This makes the mannequin helpful in lots of purposes.
One of many LLM challenges is that the mannequin is unsuitable for streaming purposes due to the mannequin’s lack of ability to deal with long-conversation chat exceeding the predefined coaching sequence size. Moreover, there’s a downside with the upper reminiscence consumption.
That’s the reason these issues above spawn analysis to unravel them. What is that this analysis? Let’s get into it.
StreamingLLM is a framework established by Xiao et al. (2023) analysis to sort out the streaming software points. The prevailing strategies are challenged as a result of the eye window constrains the LLMs throughout pre-training.
The eye window method is likely to be environment friendly however suffers when dealing with texts longer than its cache dimension. That’s why the researcher tried to make use of the Key and Worth states of a number of preliminary tokens (consideration sink) with the current tokens. The comparability of StreamingLLM and the opposite strategies might be seen within the picture beneath.

StreamingLLM vs Present Methodology (Xiao et al. (2023))
We will see how StreamingLLM tackles the problem utilizing the eye sink methodology. This consideration sink (preliminary tokens) is used for steady consideration computation and combines it with current tokens for effectivity and maintains steady efficiency on longer texts.
Moreover, the present strategies undergo from reminiscence optimization. Nonetheless, LLM avoids these points by sustaining a fixed-size window on the Key and Worth states of the newest tokens. The writer additionally mentions the good thing about StreamingLLM because the sliding window recomputation baseline by as much as 22.2× speedup.
Efficiency-wise, StreamingLLM gives glorious accuracy in comparison with the present methodology, as seen within the desk beneath.
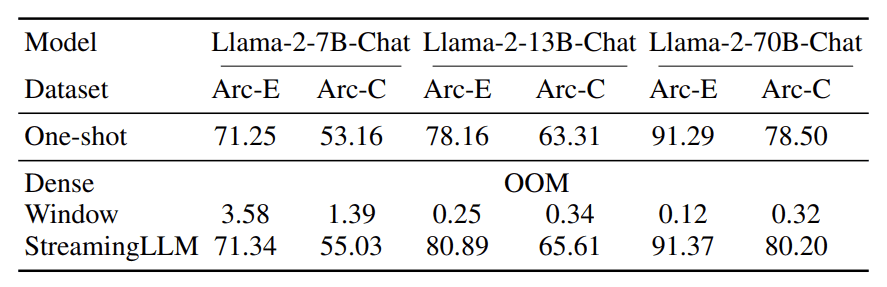
StreamingLLM accuracy (Xiao et al. (2023))
The desk above exhibits that StreamingLLM accuracy can outperform the opposite strategies within the benchmark datasets. That’s why StreamingLLM may have potential for a lot of streaming purposes.
To check out the StreamingLLM, you could possibly go to their GitHub web page. Clone the repository in your supposed listing and use the next code in your CLI to set the atmosphere.
conda create -yn streaming python=3.8
conda activate streaming
pip set up torch torchvision torchaudio
pip set up transformers==4.33.0 speed up datasets consider wandb scikit-learn scipy sentencepiece
python setup.py develop
Then, you need to use the next code to run the Llama chatbot with LLMstreaming.
CUDA_VISIBLE_DEVICES=0 python examples/run_streaming_llama.py --enable_streaming
The general pattern comparability with StreamingLLM might be proven within the picture beneath.
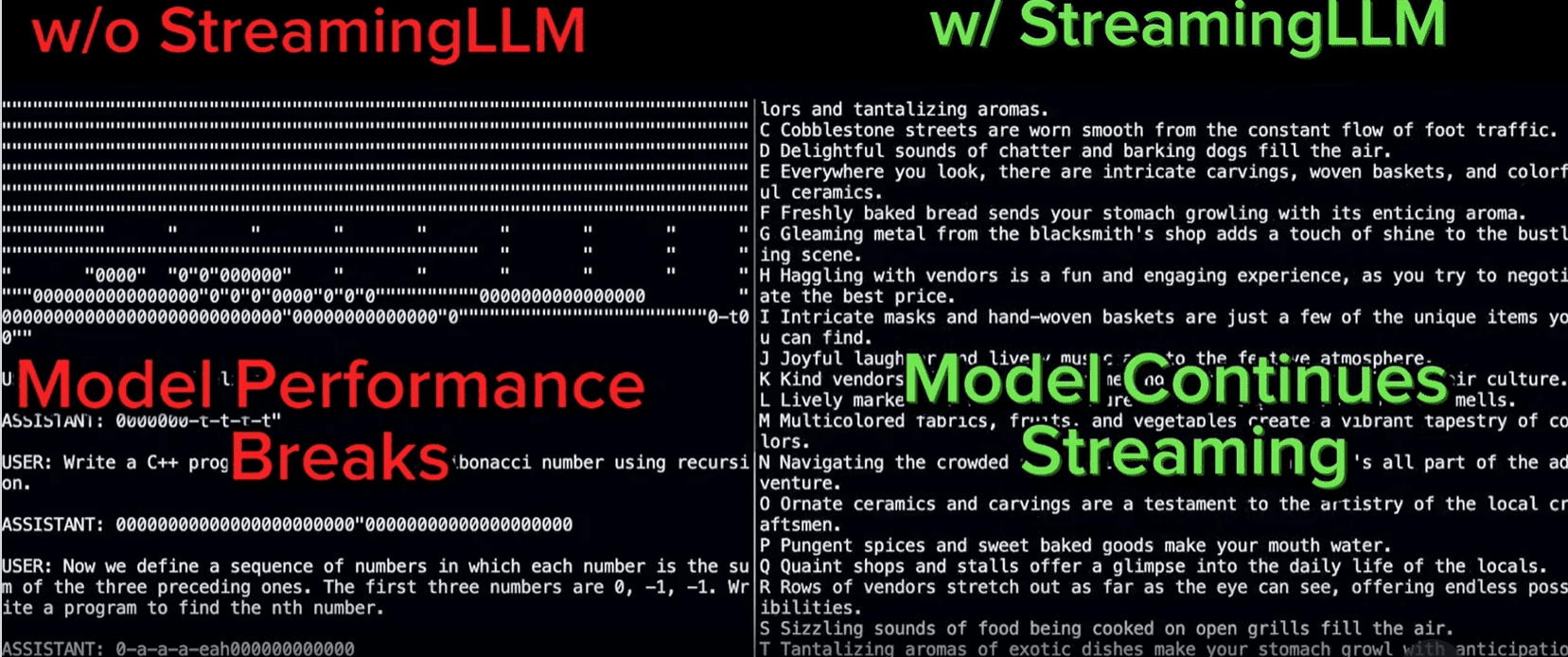
StreamingLLM confirmed excellent efficiency in additional prolonged conversations (Streaming-llm)
That’s all for the introduction of StreamingLLM. General, I consider StreamingLLM can have a spot in streaming purposes and assist change how the applying works sooner or later.
Having an LLM in streaming purposes would assist the enterprise in the long term; nonetheless, there are challenges to implement. Most LLMs can’t exceed the predefined coaching sequence size and have larger reminiscence consumption. Xiao et al. (2023) developed a brand new framework referred to as StreamingLLM to deal with these points. Utilizing the StreamingLLM, it’s now potential to have working LLM within the streaming software.
Cornellius Yudha Wijaya is a knowledge science assistant supervisor and knowledge author. Whereas working full-time at Allianz Indonesia, he likes to share Python and Information ideas by way of social media and writing media.