
{kind=link}
How usually have you ever needed to pause after asking your voice assistant about one thing in Spanish, your most well-liked language, after which restate your ask within the language that the voice assistant understands, seemingly English, as a result of the voice assistant didn’t perceive your request in Spanish? Or how usually have you ever needed to intentionally mis-pronounce your favourite artist A. R. Rahman’s identify when asking your voice assistant to play their music as a result of you already know that when you say their identify the proper means, the voice assistant will merely not perceive, however when you say A. R. Ramen the voice assistant will get it? Additional, how usually have you ever cringed when the voice assistant, of their soothing, all-knowing voice, butcher the identify of your favourite musical Les Misérables and distinctly pronounce it as “Les Miz-er-ables”?
Regardless of voice assistants having change into mainstream a few decade in the past, they proceed to stay simplistic, particularly of their understanding of person requests in multilingual contexts. In a world the place multi-lingual households are on the rise and the prevailing and potential person base is turning into more and more international and numerous, it’s essential for voice assistants to change into seamless in relation to understanding person requests, no matter their language, dialect, accent, tone, modulation, and different speech traits. Nevertheless, voice assistants proceed to lag woefully in relation to with the ability to easily converse with customers in a means that people do with one another. On this article, we’ll dive into what the highest challenges in making voice assistants function multi-lingually are, and what some methods to mitigate these challenges may be. We are going to use a hypothetical voice assistant, Nova, all through this text, for illustration functions.
Earlier than diving into the challenges and alternatives with respect to creating voice assistant person experiences multilingual, let’s get an summary of how voice assistants work. Utilizing Nova because the hypothetical voice assistant, we have a look at how the end-to-end movement for asking for a music observe appears to be like like (reference).
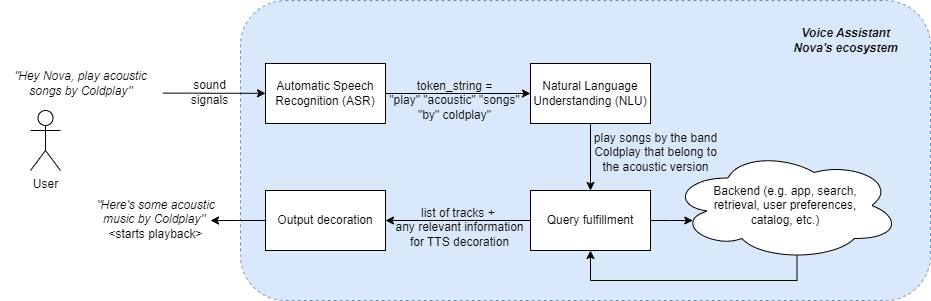
Fig. 1. Finish-to-end overview of hypothetical voice assistant Nova
As seen in Fig. 1., when a person asks Nova to play acoustic music by the favored band Coldplay, this sound sign of the person is first transformed to a string of textual content tokens, as a primary step within the human – voice assistant interplay. This stage known as Computerized Speech Recognition (ASR) or Speech to Textual content (STT). As soon as the string of tokens is offered, it’s handed on to the Pure Language Understanding step the place the voice assistant tries to grasp the semantic and syntactic which means of the person’s intent. On this case, the voice assistant’s NLU interprets that the person is searching for songs by the band Coldplay (i.e. interprets that Coldplay is a band) which can be acoustic in nature (i.e. search for meta knowledge of songs within the discography of this band and solely choose the songs with model = acoustic). This person intent understanding is then used to question the back-end to search out the content material that the person is searching for. Lastly, the precise content material that the person is searching for and every other extra info wanted to current this output to the person is carried ahead to the subsequent step. On this step, the response and every other info out there is used to brighten the expertise for the person and satisfactorily reply to the person question. On this case, it could be a Textual content To Speech (TTS) output (“right here’s some acoustic music by Coldplay”) adopted by a playback of the particular songs that have been chosen for this person question.
Multi-lingual voice assistants (VAs) suggest VAs which can be in a position to perceive and reply to a number of languages, whether or not they’re spoken by the identical particular person or individuals or if they’re spoken by the identical particular person in the identical sentence combined with one other language (e.g. “Nova, arrêt! Play one thing else”). Beneath are the highest challenges in voice assistants in relation to with the ability to function seamlessly in a multi-modal setting.
- Insufficient Amount and Amount of Language Assets
To ensure that a voice assistant to have the ability to parse and perceive a question properly, it must be educated on a major quantity of coaching knowledge in that language. This knowledge consists of speech knowledge from people, annotations for floor fact, huge quantities of textual content corpora, assets for improved pronunciation of TTS (e.g. pronunciation dictionaries) and language fashions. Whereas these assets are simply out there for common languages like English, Spanish and German, their availability is proscribed and even non-existent for languages like Swahili, Pashto or Czech. Regardless that these languages are spoken by sufficient folks, there aren’t structured assets out there for these. Creating these assets for a number of languages may be costly, advanced and manually intensive, creating headwinds to progress.
Languages have totally different dialects, accents, variations and regional diversifications. Coping with these variations is difficult for voice assistants. Until a voice assistant adapts to those linguistic nuances, it could be arduous to grasp person requests accurately or be capable of reply in the identical linguistic tone to be able to ship pure sounding and extra human-like expertise. For instance, the UK alone has greater than 40 English accents. One other instance is how the Spanish spoken in Mexico is totally different from the one spoken in Spain.
- Language Identification and Adaptation
It is not uncommon for multi-lingual customers to change between languages throughout their interactions with different people, they usually may anticipate the identical pure interactions with voice assistants. For instance, “Hinglish” is a generally used time period to explain the language of an individual who makes use of phrases from each Hindi and English whereas speaking. With the ability to establish the language(s) the person is interacting with the voice assistant in and adapting responses accordingly is a tough problem that no mainstream voice assistant can do right now.
One method to scale the voice assistant to a number of languages might be translating the ASR output from a not-so-mainstream language like Luxembourgish right into a language that may be interpreted by the NLU layer extra precisely, like English. Generally used translation applied sciences embrace utilizing a number of methods like Neural Machine Translation (NMT), Statistical Machine Translation (SMT), Rule-based Machine Translation (RBMT), and others. Nevertheless, these algorithms may not scale properly for numerous language units and may additionally require intensive coaching knowledge. Additional, language-specific nuances are sometimes misplaced, and the translated variations usually appear awkward and unnatural. The standard of translations continues to be a persistent problem when it comes to with the ability to scale multi-lingual voice assistants. One other problem within the translation step is the latency it introduces, degrading the expertise of the human – voice assistant interplay.
- True Language Understanding
Languages usually have distinctive grammatical constructions. For instance, whereas English has the idea of singular and plural, Sanskrit has 3 (singular, twin, plural). There may additionally be totally different idioms that don’t translate properly to different languages. Lastly, there may additionally be cultural nuances and cultural references that may be poorly translated, until the translating approach has a top quality of semantic understanding. Growing language particular NLU fashions is dear.
The challenges talked about above are arduous issues to unravel. Nevertheless, there are methods during which these challenges may be mitigated partially, if not absolutely, instantly. Beneath are some methods that may clear up a number of of the challenges talked about above.
- Leverage Deep Studying to Detect Language
Step one in decoding the which means of a sentence is to know what language the sentence belongs to. That is the place deep studying comes into the image. Deep studying makes use of synthetic neural networks and excessive volumes of information to create output that appears human-like. Transformer-based structure (e.g. BERT) have demonstrated success in language detection, even within the instances of low useful resource languages. A substitute for transformer-based language detection mannequin is a recurrent neural community (RNN). An instance of the appliance of those fashions is that if a person who often speaks in English out of the blue talks to the voice assistant in Spanish at some point, the voice assistant can detect and ID Spanish accurately.
- Use Contextual Machine Translation to ‘Perceive’ the Request
As soon as the language has been detected, the subsequent step in the direction of decoding the sentence is to take the output of the ASR stage, i.e., the string of tokens, and translate this string, not simply actually but in addition semantically, right into a language that may be processed to be able to generate a response. As an alternative of utilizing translation APIs that may not all the time pay attention to the context and peculiarities of the voice interface and likewise introduce suboptimal delays in responses due to excessive latency, degrading the person expertise. Nevertheless, if context-aware machine translation fashions are built-in into voice assistants, the translations may be of upper high quality and accuracy due to being particular to a website or the context of the session. For instance, if a voice assistant is getting used primarily for leisure, it will probably leverage contextual machine translation to accurately perceive and reply to questions on genres and sub-genres of music, musical devices and notes, cultural relevance of sure tracks, and extra.
- Capitalize on Multi-lingual Pre-trained Fashions
Since each language has a novel construction and grammar, cultural references, phrases, idioms and expressions and different nuances, it’s difficult to course of numerous languages. Given language particular fashions are costly, pre-trained multi-lingual fashions will help seize language particular nuances. Fashions like BERT and XLM-R are good examples of pre-trained fashions that may seize language particular nuances. Lastly, these fashions may be fine-tuned to a website to additional improve their accuracy. For instance, for a mannequin educated on the music area may be capable of not simply perceive the question but in addition return a wealthy response by way of a voice assistant. If this voice assistant is requested what the which means behind the lyrics of a tune are, the voice assistant will be capable of reply the query in a a lot richer means than a easy interpretation of the phrases.
- Use Code Switching Fashions
Implementing code switching fashions for with the ability to deal with language enter that may be a combine of various languages will help within the instances the place a person makes use of a couple of language of their interactions with the voice assistant. For instance, if a voice assistant is designed particularly for a area in Canada the place customers usually combine up French and English, a code-switching mannequin can be utilized to grasp sentences directed to the voice assistant which can be a mixture of the 2 languages and the voice assistant will be capable of deal with it.
- Leverage Switch Studying and Zero Shot Studying for Low Useful resource Languages
Switch studying is a method in ML the place a mannequin is educated on one activity however is used as a place to begin for a mannequin on a second activity. It makes use of the educational from the primary activity to enhance the efficiency of the second activity, thus overcoming the cold-start drawback to an extent. Zero shot studying is when a pre-trained mannequin is used to course of knowledge it has by no means seen earlier than. Each Switch Studying and Zero Shot studying may be leveraged to switch data from high-resource languages into low-resource languages. For instance, if a voice assistant is already educated on the highest 10 languages spoken mostly on the planet, it might be leveraged to grasp queries in low useful resource languages like Swahili.
In abstract, constructing and implementing multilingual experiences on voice assistants is difficult, however there are additionally methods to mitigate a few of these challenges. By addressing the challenges referred to as out above, voice assistants will be capable of present a seamless expertise to their customers, no matter their language.
Ashlesha Kadam leads a worldwide product staff at Amazon Music that builds music experiences on Alexa and Amazon Music apps (internet, iOS, Android) for hundreds of thousands of shoppers throughout 45+ nations. She can be a passionate advocate for girls in tech, serving as co-chair for the Human Laptop Interplay (HCI) observe for Grace Hopper Celebration (largest tech convention for girls in tech with 30K+ members throughout 115 nations). In her free time, Ashlesha loves studying fiction, listening to biz-tech podcasts (present favourite – Acquired), climbing within the stunning Pacific Northwest and spending time together with her husband, son and 5yo Golden Retriever.