

{kind=link}
By extra pre-training utilizing image-text pairings or fine-tuning them with specialised visible instruction tuning datasets, Massive Language Fashions might dive into the multimodal area, giving rise to potent Massive Multimodal Fashions. Nonetheless, there are obstacles to constructing LMMs, chief amongst them the disparity between the amount and high quality of multimodal information and text-only datasets. Take the LLaVA mannequin, initialized from a pre-trained visible encoder and a language mannequin tweaked for directions. It’s skilled on far fewer cases than text-only fashions, which use over 100M examples over 1800 duties. It is just skilled on 150K synthetic image-based conversations. Resulting from such information restrictions, the visible and language modalities might not be aligned.
Consequently, LMMs may generate hallucinatory outputs which might be inaccurately tied to the context that photos give. Researchers from UC Berkeley, CMU, UIUC, UW–Madison, UMass Amherst Microsoft Analysis, and MIT-IBM Watson AI Lab current LLaVA-RLHF, a vision-language mannequin skilled for enhanced multimodal alignment, to handle the problems introduced on by the absence of high-quality visible instruction tuning information for LMM coaching. One in every of their main contributions is adapting the multimodal alignment for LMMs to the common and scalable alignment paradigm referred to as Reinforcement Studying from Human Suggestions, which has demonstrated outstanding effectiveness for text-based AI brokers. To fine-tune LMM, it collects human preferences specializing in recognizing hallucinations and makes use of these preferences in reinforcement studying.
This technique might enhance the multimodal alignment at a comparatively low cost annotation price, reminiscent of $3000 for gathering 10K human preferences for image-based discussions. So far as they know, this technique is the primary efficient use of RLHF for multimodal alignment. Gaining excessive scores from the reward mannequin solely typically equates to enhancing human judgments, which is reward hacking. It’s a attainable downside with the current RLHF paradigm. Earlier analysis recommended iteratively gathering “contemporary” human suggestions to cease incentive hacking, however this technique is usually costly and can’t correctly use present human choice information. This research suggests a extra data-efficient choice, making an attempt to make the reward mannequin able to utilizing the information and information already current in larger language fashions that people have annotated.
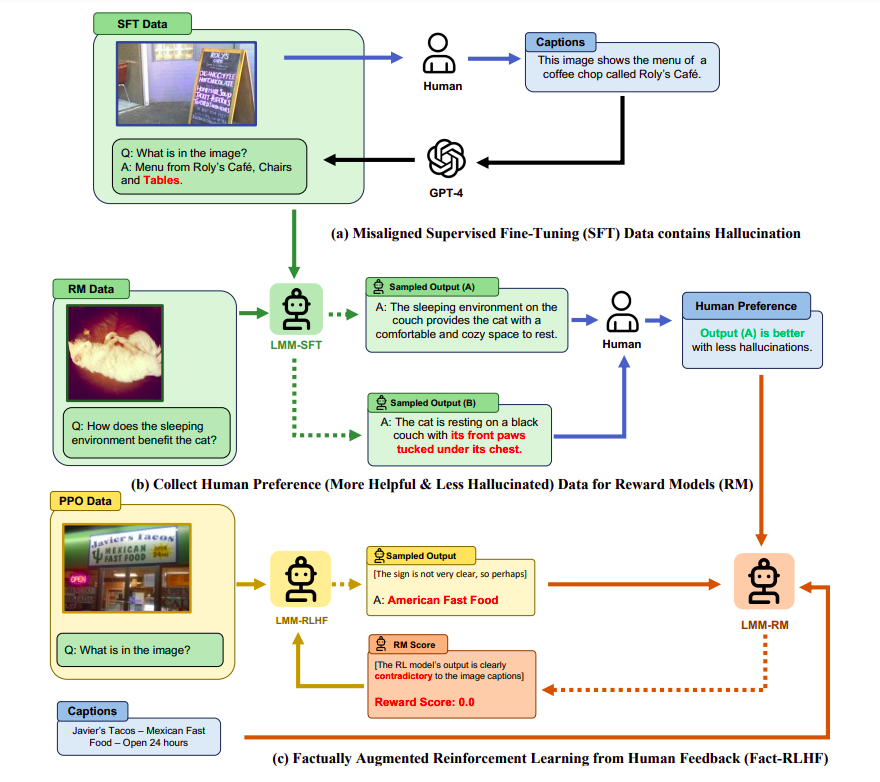
Determine 1: A diagram illustrating the potential for hallucinations through the Supervised Tremendous-Tuning (SFT) part of LMM coaching and the way in which Factually Augmented RLHF addresses the issue of low capability within the reward mannequin, which is initialized from the SFT mannequin.
First, they use a superior visible encoder with greater resolutions and a much bigger language mannequin to boost the reward mannequin’s total performance. Second, they current the Factually Augmented RLHF algorithm, which, as proven in Fig. 1, calibrates the reward alerts by supplementing them with additional info like image descriptions or a ground-truth multi-choice choice. They additional increase the artificial imaginative and prescient instruction tuning information with present high-quality human-annotated multimodal information within the dialog format to boost the final capabilities of LMMs through the Supervised Tremendous-Tuning stage. They particularly rework Flickr30k right into a Recognizing Captioning task, VQA-v2, and A-OKVQA right into a multi-round QA job, and each prepare the LLaVA-SFT+ fashions utilizing the brand new information set.
Lastly, they contemplate how one can consider the multimodal alignment of LMMs in conditions of real-world creation, paying specific consideration to penalizing any hallucinations. The benchmark questions they develop, MMHAL-BENCH, cowl all 12 of COCO’s key object classes and comprise eight job sorts. In line with their evaluation, this benchmark dataset carefully matches human assessments, particularly if scores are thought-about for anti-hallucinations. As the primary LMM skilled with RLHF, LLaVA-RLHF performs admirably of their experimental evaluation. They noticed an enchancment of 94% on the LLaVA-Bench, a 60% enchancment on the MMHAL-BENCH, they usually set new efficiency data for LLaVA with 52.4% on MMBench and 82.7% F1 on POPE. On GitHub, they’ve made their code, mannequin, and information accessible to the general public.
Try the Paper and Mission. All Credit score For This Analysis Goes To the Researchers on This Mission. Additionally, don’t overlook to hitch our 31k+ ML SubReddit, 40k+ Fb Group, Discord Channel, and E mail Publication, the place we share the newest AI analysis information, cool AI tasks, and extra.
When you like our work, you’ll love our e-newsletter..
Aneesh Tickoo is a consulting intern at MarktechPost. He’s at present pursuing his undergraduate diploma in Information Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on tasks aimed toward harnessing the ability of machine studying. His analysis curiosity is picture processing and is enthusiastic about constructing options round it. He loves to attach with folks and collaborate on attention-grabbing tasks.