

{kind=link}
Multimodal datasets, which mix numerous knowledge sorts, corresponding to photographs and textual content, have performed a vital position in advancing synthetic intelligence. These datasets allow AI fashions to grasp and generate content material throughout totally different modalities, resulting in vital progress in picture recognition, language comprehension, and cross-modal duties. As the necessity for complete AI methods will increase, exploring and harnessing the potential of multimodal datasets has grow to be important in pushing the boundaries of machine studying capabilities. Researchers from Apple and the College of Washington have launched DATACOMP, a multimodal dataset testbed that comprises 12.8 billion pairs of photographs and textual content knowledge from Frequent Crawl.
Classical analysis focuses on enhancing mannequin efficiency by means of dataset cleansing, outlier elimination, and coreset choice. Current efforts in subset choice function on smaller curated datasets, not reflecting noisy image-text pairs and large-scale datasets in fashionable coaching paradigms. Current benchmarks for data-centric investigations are restricted in comparison with bigger datasets like LAION-2B. Earlier work highlights the advantages of dataset pruning, deduplication, and CAT filtering for image-text datasets. Challenges come up as a result of proprietary nature of large-scale multimodal datasets, hindering complete data-centric investigations.
Current strides in multimodal studying, impacting zero-shot classification and picture technology, depend on massive datasets like CLIPs (400 million pairs) and Steady Diffusions (two billion from LAION-2B). Regardless of their significance, little is thought about these proprietary datasets, usually handled with out detailed investigation. DATACOMP addresses this hole, serving as a testbed for multimodal dataset experiments. DATACOMP permits researchers to design and consider new filtering strategies, advancing understanding and bettering dataset design for multimodal fashions.
DATACOMP is a dataset experiment testbed that includes 12.8 billion image-text pairs from Frequent Crawl. Researchers design and consider new filtering strategies or knowledge sources through the use of standardized CLIP coaching code and testing on 38 downstream units. ViT structure, chosen for its favorable CLIP scaling tendencies over ResNets, is employed in experiments. Medium-scale experiments contain substituting the ViT-B32 structure with a ConvNeXt mannequin. DATACOMP facilitates innovation and analysis in multimodal dataset analysis, enhancing understanding and refining fashions for improved efficiency.
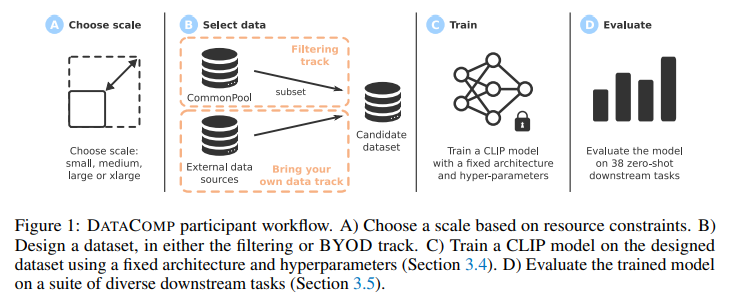
DATACOMP’s workflow yields superior coaching units, with DATACOMP-1B attaining a 3.7 share level enchancment over OpenAI’s CLIP ViT-L/14 in zero-shot accuracy on ImageNet (79.2%). Using the identical coaching process and computation showcases the efficacy of DATACOMP. The benchmark encompasses numerous compute scales, facilitating the examine of scaling tendencies throughout 4 orders of magnitude and accommodating researchers with various sources. The expansive image-text pair pool, COMMONPOOL, derived from Frequent Crawl, proves helpful for dataset experiments, enhancing accessibility and contributing to developments in multimodal studying.
In conclusion, the analysis may be summarized within the following factors:
- DATACOMP is a dataset experiment testbed.
- The platform contains a pool of 12.8 billion image-text pairs from Frequent Crawl.
- Researchers can use this platform to design filtering strategies, curate knowledge, and assess datasets.
- Standardized CLIP coaching with downstream testing is used to judge the datasets.
- This benchmark facilitates finding out scaling tendencies throughout various sources and compute scales.
- DATACOMP-1B, the very best baseline, surpasses OpenAI’s CLIP ViT-L/14 by 3.7 share factors in zero-shot accuracy on ImageNet.
- DATACOMP and its code are launched for widespread analysis and experimentation.
Try the Paper, Code, and Undertaking. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to hitch our 34k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and E mail Publication, the place we share the newest AI analysis information, cool AI tasks, and extra.
In the event you like our work, you’ll love our publication..
Hey, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m at the moment pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m captivated with know-how and need to create new merchandise that make a distinction.