

{kind=link}
Within the evolving panorama of synthetic intelligence and machine studying, the combination of visible notion with language processing has turn into a frontier of innovation. This integration is epitomized within the improvement of Multimodal Giant Language Fashions (MLLMs), which have proven exceptional prowess in a variety of vision-language duties. Nonetheless, these fashions usually falter in fundamental object notion duties, akin to precisely figuring out and counting objects inside a visible scene. This discrepancy factors to a crucial want for enchancment within the perceptual capabilities of MLLMs, significantly in precisely recognizing each salient and background entities.
The principle problem this analysis confronts is enhancing the MLLMs’ skill to understand objects in a visible scene precisely. Present MLLMs, whereas adept at advanced reasoning duties, usually overlook finer particulars and background components, resulting in inaccuracies in object notion. This concern is additional compounded when fashions are required to depend objects or establish much less outstanding entities in a picture. The objective is to refine these fashions to attain a extra holistic and correct understanding of visible scenes with out compromising their reasoning skills.
The Versatile imaginative and prescient enCoders (VCoder) methodology launched by researchers from Georgia Tech, Microsoft Analysis, and Picsart AI Analysis represents an progressive answer to this problem. VCoder improves MLLMs by incorporating further notion modalities, akin to segmentation or depth maps, into the fashions. This strategy goals to reinforce the mannequin’s understanding of the visible world, thereby enhancing their notion and reasoning capabilities. VCoder operates by utilizing further imaginative and prescient encoders that venture data from notion modalities into the LLM’s area. This entails figuring out and decreasing higher-order elements in weight matrices, specializing in particular layers inside the Transformer mannequin. The strategy is designed to sharpen the fashions’ object-level notion expertise, together with counting, with out the necessity for extra coaching or parameters.
VCoder’s efficiency was rigorously evaluated in opposition to varied benchmarks to evaluate its effectiveness in enhancing object notion duties. It demonstrated notable enhancements in accuracy, significantly in eventualities involving much less regularly represented data in coaching knowledge. This development within the fashions’ robustness and factuality is a major step ahead within the improvement of MLLMs which are equally adept at notion and reasoning.
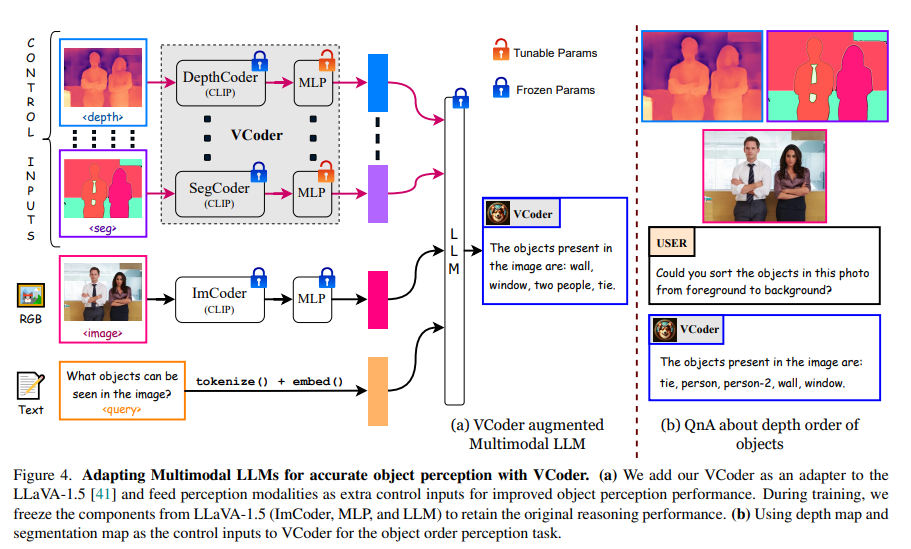
The examine illustrates that whereas MLLMs have made vital strides in advanced visible reasoning duties, they usually show subpar efficiency in easier duties like counting objects. VCoder, by feeding further notion modalities as management inputs by way of further imaginative and prescient encoders, supplies a novel answer to this downside. The researchers used photographs from the COCO dataset and outputs from off-the-shelf imaginative and prescient notion fashions to create a COCO Segmentation Textual content dataset for coaching and evaluating MLLMs on object notion duties. They launched metrics like depend rating, hallucination rating, and depth rating to evaluate object notion skills in MLLMs.
In depth experimental proof proved VCoder’s improved object-level notion expertise over current Multimodal LLMs, together with GPT-4V. VCoder was efficient in enhancing mannequin efficiency on much less regularly represented data within the coaching knowledge, indicating a rise within the mannequin’s robustness and factuality. The strategy allowed MLLMs to deal with nuanced and fewer widespread knowledge higher, thus broadening their applicability and effectiveness.
In conclusion, the VCoder method marks a major advance within the optimization of MLLMs. Adopting a selective strategy to decreasing elements in weight matrices efficiently enhances these fashions’ effectivity with out imposing further computational burdens. This strategy not solely elevates the efficiency of MLLMs in acquainted duties but additionally expands their capabilities in processing and understanding advanced visible scenes. The analysis opens new avenues for creating extra refined and environment friendly language fashions which are proficient in each notion and reasoning.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to affix our 35k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and Electronic mail E-newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
Should you like our work, you’ll love our e-newsletter..
Hey, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m keen about know-how and wish to create new merchandise that make a distinction.