
{kind=link}

The scraped knowledge of two.6 million DuoLingo customers was leaked on a hacking discussion board, permitting risk actors to conduct focused phishing assaults utilizing the uncovered data.
Duolingo is without doubt one of the largest language studying websites on the earth, with over 74 million month-to-month customers worldwide.
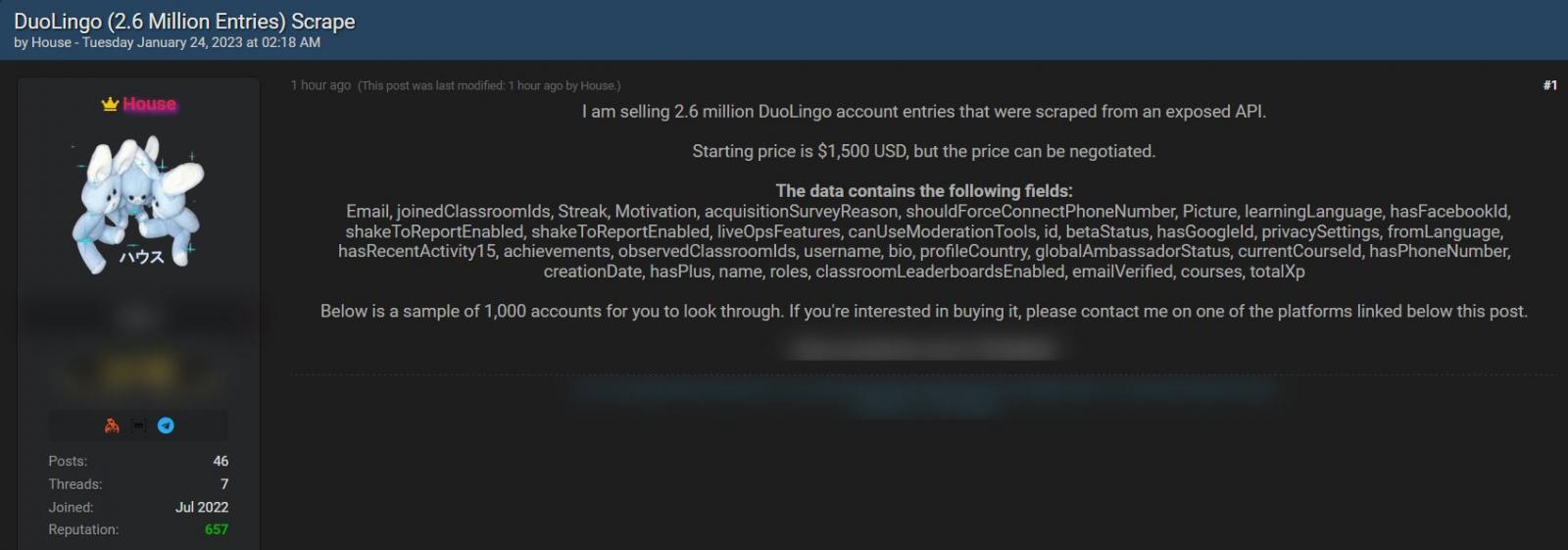
In January 2023, somebody was promoting the scraped knowledge of two.6 million DuoLingo customers on the now-shutdown Breached hacking discussion board for $1,500.
This knowledge features a combination of public login and actual names, and private data, together with e-mail addresses and inner data associated to the DuoLingo service.
Whereas the true title and login title are publicly out there as a part of a person’s Duolingo profile, the e-mail addresses are extra regarding as they permit this public knowledge for use in assaults.
Supply: Falcon Feeds
When the info was on the market, DuoLingo confirmed to TheRecord that it was scraped from public profile data and that they had been investigating whether or not additional precautions must be taken.
Nevertheless, Duolingo didn’t handle the truth that e-mail addresses had been additionally listed within the knowledge, which isn’t public data.
As first noticed by VX-Underground, the scraped 2.6 million person dataset was launched yesterday on a brand new model of the Breached hacking discussion board for 8 web site credit, value solely $2.13.
“At present I’ve uploaded the Duolingo Scrape so that you can obtain, thanks for studying and revel in!,” reads a submit on the hacking discussion board.

Supply: BleepingComputer
This knowledge was scraped utilizing an uncovered utility programming interface (API) that has been shared overtly since not less than March 2023, with researchers tweeting and publicly documenting easy methods to use the API.
The API permits anybody to submit a username and retrieve JSON output containing the person’s public profile data. Nevertheless, it’s also attainable to feed an e-mail handle into the API and make sure whether it is related to a legitimate DuoLingo account.
BleepingComputer has confirmed that this API continues to be overtly out there to anybody on the internet, even after its abuse was reported to DuoLingo in January.
This API allowed the scraper to feed tens of millions of e-mail addresses, doubtless uncovered in earlier knowledge breaches, into the API and make sure in the event that they belonged to DuoLingo accounts. These e-mail addresses had been then used to create the dataset containing public and private data.
One other risk actor shared their very own API scrape, stating that risk actors wishing to make use of the info in phishing assaults ought to take note of particular fields that point out a DuoLingo person has extra permission than a daily person and are thus extra beneficial targets.
BleepingComputer has contacted DuoLingo with questions on why the API continues to be publicly out there however didn’t obtain a reply on the time of this publication.
Scraped knowledge commonly dismissed
Firms are inclined to dismiss scraped knowledge as not a problem as many of the knowledge is already public, even when it isn’t essentially straightforward to compile.
Nevertheless, when public knowledge is blended with personal knowledge, similar to telephone numbers and e-mail addresses, it tends to make the uncovered data extra dangerous and probably violate knowledge safety legal guidelines.
For instance, in 2021, Fb suffered an enormous leak after an “Add Buddy” API bug was abused to hyperlink telephone numbers to Fb accounts for 533 million customers. The Irish knowledge safety fee (DPC) later fined Fb €265 million ($275.5 million) for this leak of scraped knowledge.
Extra lately, a Twitter API bug was used to scrape the general public knowledge and e-mail addresses of tens of millions of customers, resulting in an investigation by the DPC.