
{kind=link}
Segmentation, the method of figuring out picture pixels that belong to things, is on the core of laptop imaginative and prescient. This course of is utilized in functions from scientific imaging to picture modifying, and technical specialists should possess each extremely expert talents and entry to AI infrastructure with giant portions of annotated information for correct modeling.
Meta AI just lately unveiled its Section Something challenge? which is ?a picture segmentation dataset and mannequin with the Section Something Mannequin (SAM) and the SA-1B masks dataset?—?the most important ever segmentation dataset assist additional analysis in basis fashions for laptop imaginative and prescient. They made SA-1B accessible for analysis use whereas the SAM is licensed below Apache 2.0 open license for anybody to strive SAM along with your photos utilizing this demo!

Section Something Mannequin / Picture by Meta AI
Earlier than, segmentation issues have been approached utilizing two lessons of approaches:
- Interactive segmentation wherein the customers information the segmentation job by iteratively refining a masks.
- Automated segmentation allowed selective object classes like cats or chairs to be segmented routinely however it required giant numbers of annotated objects for coaching (i.e. hundreds and even tens of hundreds of examples of segmented cats) together with computing sources and technical experience to coach a segmentation mannequin neither strategy offered a normal, totally computerized answer to segmentation.
SAM makes use of each interactive and computerized segmentation in a single mannequin. The proposed interface allows versatile utilization, making a variety of segmentation duties attainable by engineering the suitable immediate (akin to clicks, packing containers, or textual content).
SAM was developed utilizing an expansive, high-quality dataset containing a couple of billion masks collected as a part of this challenge, giving it the potential of generalizing to new kinds of objects and pictures past these noticed throughout coaching. In consequence, practitioners not want to gather their segmentation information and tailor a mannequin particularly to their use case.
These capabilities allow SAM to generalize each throughout duties and domains one thing no different picture segmentation software program has carried out earlier than.
SAM comes with highly effective capabilities that make the segmentation job more practical:
- Number of enter prompts: Prompts that direct segmentation permit customers to simply carry out completely different segmentation duties with out further coaching necessities. You possibly can apply segmentation utilizing interactive factors and packing containers, routinely phase all the pieces in a picture, and generate a number of legitimate masks for ambiguous prompts. Within the determine beneath we are able to see the segmentation is finished for sure objects utilizing an enter textual content immediate.

Bounding field utilizing textual content immediate.
- Integration with different programs: SAM can settle for enter prompts from different programs, akin to sooner or later taking the consumer’s gaze from an AR/VR headset and deciding on objects.
- Extensible outputs: The output masks can function inputs to different AI programs. For example, object masks may be tracked in movies, enabled imaging modifying functions, lifted into 3D area, and even used creatively akin to collating
- Zero-shot generalization: SAM has developed an understanding of objects which permits him to rapidly adapt to unfamiliar ones with out further coaching.
- A number of masks era: SAM can produce a number of legitimate masks when confronted with uncertainty relating to an object being segmented, offering essential help when fixing segmentation in real-world settings.
- Actual-time masks era: SAM can generate a segmentation masks for any immediate in actual time after precomputing the picture embedding, enabling real-time interplay with the mannequin.
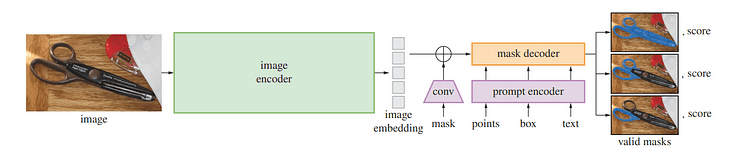
Overview of SAM mannequin / Picture by Section Something
One of many current advances in pure language processing and laptop imaginative and prescient has been basis fashions that allow zero-shot and few-shot studying for brand new datasets and duties by means of “prompting”. Meta AI researchers educated SAM to return a sound segmentation masks for any immediate, akin to foreground/background factors, tough packing containers/masks or masks, freeform textual content, or any data indicating the goal object inside a picture.
A sound masks merely implies that even when the immediate may confer with a number of objects (for example: one level on a shirt could signify each itself or somebody sporting it), its output ought to present an affordable masks for one object solely?—?thus pre-training the mannequin and fixing normal downstream segmentation duties by way of prompting.
The researchers noticed that pretraining duties and interactive information assortment imposed particular constraints on mannequin design. Most importantly, real-time simulation should run effectively on a CPU in an internet browser to permit annotators to make use of SAM interactively in real-time for environment friendly annotation. Though runtime constraints resulted in tradeoffs between high quality and runtime constraints, easy designs produced passable leads to observe.
Beneath SAM’s hood, a picture encoder generates a one-time embedding for photos whereas a light-weight encoder converts any immediate into an embedding vector in real-time. These data sources are then mixed by a light-weight decoder that predicts segmentation masks based mostly on picture embeddings computed with SAM, so SAM can produce segments in simply 50 milliseconds for any given immediate in an internet browser.
Constructing and coaching the mannequin requires entry to an unlimited and numerous pool of information that didn’t exist firstly of coaching. In the present day’s segmentation dataset launch is by far the most important so far. Annotators used SAM interactively annotate photos earlier than updating SAM with this new information?—?repeating this cycle many instances to constantly refine each the mannequin and dataset.
SAM makes amassing segmentation masks quicker than ever, taking solely 14 seconds per masks annotated interactively; that course of is barely two instances slower than annotating bounding packing containers which take solely 7 seconds utilizing quick annotation interfaces. Comparable large-scale segmentation information assortment efforts embody COCO totally guide polygon-based masks annotation which takes about 10 hours; SAM model-assisted annotation efforts have been even quicker; its annotation time per masks annotated was 6.5x quicker versus 2x slower by way of information annotation time than earlier mannequin assisted giant scale information annotations efforts!
Interactively annotating masks is inadequate to generate the SA-1B dataset; thus an information engine was developed. This information engine comprises three “gears”, beginning with assisted annotators earlier than transferring onto totally automated annotation mixed with assisted annotation to extend the variety of collected masks and at last totally computerized masks creation for the dataset to scale.
SA-1B’s last dataset options greater than 1.1 billion segmentation masks collected on over 11 million licensed and privacy-preserving photos, making up 4 instances as many masks than any present segmentation dataset, in accordance with human analysis research. As verified by these human assessments, these masks exhibit prime quality and variety in contrast with earlier manually annotated datasets with a lot smaller pattern sizes.
Photographs for SA-1B have been obtained by way of a picture supplier from a number of nations that represented completely different geographic areas and earnings ranges. Whereas sure geographic areas stay underrepresented, SA-1B offers larger illustration as a result of its bigger variety of photos and general higher protection throughout all areas.
Researchers carried out exams geared toward uncovering any biases within the mannequin throughout gender presentation, pores and skin tone notion, the age vary of individuals in addition to the perceived age of individuals introduced, discovering that the SAM mannequin carried out equally throughout numerous teams. They hope it will make the ensuing work extra equitable when utilized in real-world use circumstances.
Whereas SA-1B enabled the analysis output, it will possibly additionally allow different researchers to coach basis fashions for picture segmentation. Moreover, this information could turn into the muse for brand new datasets with further annotations.
Meta AI researchers hope that by sharing their analysis and dataset, they’ll speed up the analysis in picture segmentation and picture and video understanding. Since this segmentation mannequin can carry out this operate as a part of bigger programs.
On this article, we coated what’s SAM and its functionality and use circumstances. After that, we went by means of the way it works, and the way it was educated in order to offer an summary of the mannequin. Lastly, we conclude the article with the long run imaginative and prescient and work. If you want to know extra about SAM make sure that to learn the paper and take a look at the demo.
Youssef Rafaat is a pc imaginative and prescient researcher & information scientist. His analysis focuses on growing real-time laptop imaginative and prescient algorithms for healthcare functions. He additionally labored as an information scientist for greater than 3 years within the advertising and marketing, finance, and healthcare area.