
{kind=link}
Time-series knowledge, collected practically each second from a multiplicity of sources, is commonly subjected to a number of knowledge high quality points, amongst which lacking knowledge.
Within the context of sequential knowledge, lacking data can come up because of a number of causes, specifically errors occurring on acquisition techniques (e.g. malfunction sensors), errors in the course of the transmission course of (e.g., defective community connections), or errors throughout knowledge assortment (e.g., human error throughout knowledge logging). These conditions usually generate sporadic and specific lacking values in our datasets, equivalent to small gaps within the stream of collected knowledge.
Moreover, lacking data also can come up naturally because of the traits of the area itself, creating bigger gaps within the knowledge. As an example, a function that stops being collected for a sure time period, producing non-explicit lacking knowledge.
Whatever the underlying trigger, having lacking knowledge in our time-series sequences is very prejudicial for forecasting and predictive modeling and should have severe penalties for each people (e.g., misguided threat evaluation) and enterprise outcomes (e.g., biased enterprise selections, lack of income and alternatives).
When getting ready the info for modeling approaches, an essential step is due to this fact with the ability to determine these patterns of unknown data, as they’ll assist us resolve on the greatest strategy to deal with the info effectively and enhance its consistency, both by means of some type of alignment correction, knowledge interpolation, knowledge imputation, or in some instances, casewise deletion (i.e., omit instances with lacking values for a function utilized in a selected evaluation).
For that purpose, performing a radical exploratory knowledge evaluation and knowledge profiling is indispensable not solely to grasp the info traits but additionally to make knowledgeable selections on the right way to greatest put together the info for evaluation.
On this hands-on tutorial, we’ll discover how ydata-profiling may also help us kind out these points with the options just lately launched within the new launch. We’ll be utilizing the U.S. Air pollution Dataset, out there in Kaggle (License DbCL v1.0), that particulars data relating to NO2, O3, SO2, and CO pollution throughout U.S. states.
To kickstart our tutorial, we first want to put in the most recent model of ydata-profiling:
pip set up ydata-profiling==4.5.1
Then, we are able to load the info, take away pointless options, and concentrate on what we purpose to research. For the aim of this instance, we’ll concentrate on the actual conduct of air pollution’ measurements taken on the station of Arizona, Maricopa, Scottsdale:
import pandas as pd
knowledge = pd.read_csv("knowledge/pollution_us_2000_2016.csv")
knowledge = knowledge.drop('Unnamed: 0', axis = 1) # dropping pointless index
# Choose knowledge from Arizona, Maricopa, Scottsdale (Website Num: 3003)
data_scottsdale = knowledge[data['Site Num'] == 3003].reset_index(drop=True)
Now, we’re prepared to start out profiling our dataset! Recall that, to make use of the time-series profiling, we have to move the parameter tsmode=True in order that ydata-profiling can determine time-dependent options:
# Change 'Knowledge Native' to datetime
data_scottsdale['Date Local'] = pd.to_datetime(data_scottsdale['Date Local'])
# Create the Profile Report
profile_scottsdale = ProfileReport(data_scottsdale, tsmode=True, sortby="Date Native")
profile_scottsdale.to_file('profile_scottsdale.html')
Time-Sequence Overview
The output report might be acquainted to what we already know, however with an improved expertise and new abstract statistics for time-series knowledge:
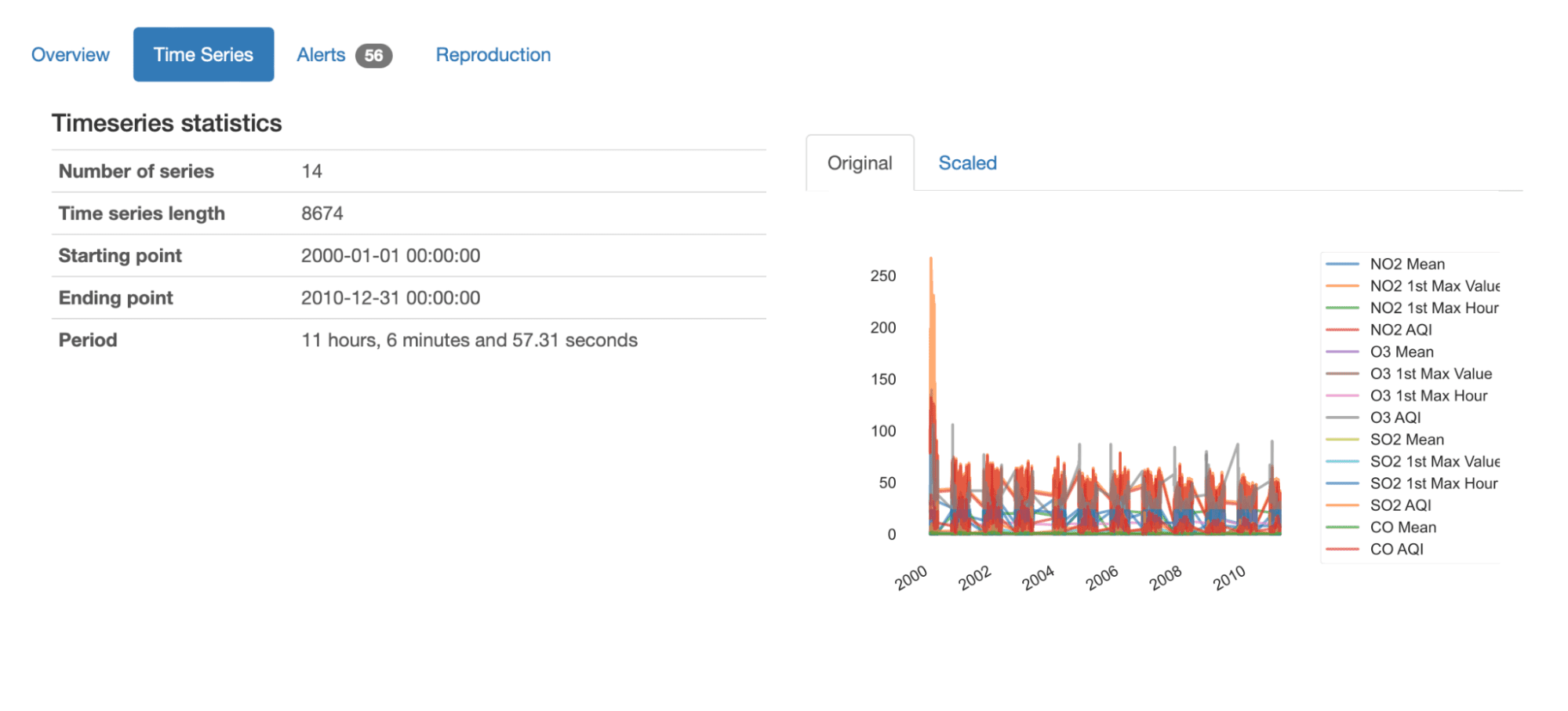
Instantly from the overview, we are able to get an total understanding of this dataset by trying on the offered abstract statistics:
- It comprises 14 totally different time-series, every with 8674 recorded values;
- The dataset studies on 10 years of information from January 2000 to December 2010;
- The typical time period sequences is 11 hours and (practically) 7 minutes. Because of this on common, we’ve got measures being taken each 11 hours.
We will additionally get an outline plot of all sequence in knowledge, both of their authentic or scaled values: we are able to simply grasp the general variation of the sequences, in addition to the parts (NO2, O3, SO2, CO) and traits (Imply, 1st Max Worth, 1st Max Hour, AQI) being measured.
Inspecting Lacking Knowledge
After having an total view of the info, we are able to concentrate on the specifics of every time sequence.
Within the newest launch of ydata-profiling, the profiling report was considerably improved with devoted evaluation for time-series knowledge, specifically reporting on the “Time Sequence” and “Hole Evaluation”’ metrics. The identification of developments and lacking patterns is extraordinarily facilitated by these new options, the place particular abstract statistics and detailed visualizations at the moment are out there.
One thing that stands out instantly is the flaky sample that each one time sequence current, the place sure “jumps” appear to happen between consecutive measurements. This means the presence of lacking knowledge (“gaps” of lacking data) that needs to be studied extra intently. Let’s check out the S02 Imply for example.

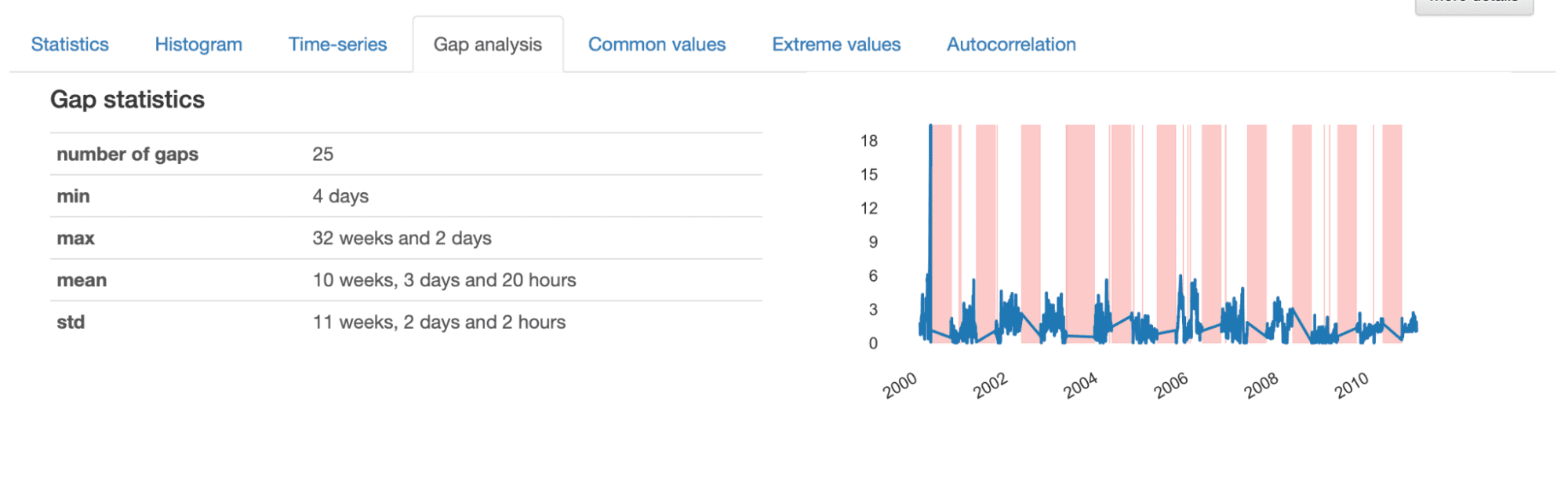
When investigating the small print given within the Hole Evaluation, we get an informative description of the traits of the recognized gaps. Total, there are 25 gaps within the time-series, with a minimal size of 4 days, a most of 32 weeks, and a mean of 10 weeks.
From the visualization offered, we word considerably “random” gaps represented by thinner stripes, and bigger gaps which appear to comply with a repetitive sample. This means that we appear to have two totally different patterns of lacking knowledge in our dataset.
Smaller gaps correspond to sporadic occasions producing lacking knowledge, most definitely occurring because of errors within the acquisition course of, and might usually be simply interpolated or deleted from the dataset. In flip, bigger gaps are extra complicated and must be analyzed in additional element, as they could reveal an underlying sample that must be addressed extra completely.
In our instance, if we have been to research the bigger gaps, we’d the truth is uncover that they replicate a seasonal sample:
df = data_scottsdale.copy()
for yr in df["Date Local"].dt.yr.distinctive():
for month in vary(1,13):
if ((df["Date Local"].dt.yr == yr) & (df["Date Local"].dt.month ==month)).sum() == 0:
print(f'12 months {yr} is lacking month {month}.')
# 12 months 2000 is lacking month 4.
# 12 months 2000 is lacking month 5.
# 12 months 2000 is lacking month 6.
# 12 months 2000 is lacking month 7.
# 12 months 2000 is lacking month 8.
# (...)
# 12 months 2007 is lacking month 5.
# 12 months 2007 is lacking month 6.
# 12 months 2007 is lacking month 7.
# 12 months 2007 is lacking month 8.
# (...)
# 12 months 2010 is lacking month 5.
# 12 months 2010 is lacking month 6.
# 12 months 2010 is lacking month 7.
# 12 months 2010 is lacking month 8.
As suspected, the time-series presents some massive data gaps that appear to be repetitive, even seasonal: in most years, the info was not collected between Might to August (months 5 to eight). This may increasingly have occurred because of unpredictable causes, or identified enterprise selections, for instance, associated to reducing prices, or just associated to seasonal differences of pollution related to climate patterns, temperature, humidity, and atmospheric situations.
Primarily based on these findings, we may then examine why this occurred, if one thing needs to be completed to forestall it sooner or later, and the right way to deal with the info we at the moment have.
All through this tutorial, we’ve seen how essential it’s to grasp the patterns of lacking knowledge in time-series and the way an efficient profiling can reveal the mysteries behind gaps of lacking data. From telecom, healthcare, power, and finance, all sectors amassing time-series knowledge will face lacking knowledge sooner or later and might want to resolve one of the simplest ways to deal with and extract all doable information from them.
With a complete knowledge profiling, we are able to make an knowledgeable and environment friendly determination relying on the info traits at hand:
- Gaps of data may be brought on by sporadic occasions that derive from errors in acquisition, transmission, and assortment. We will repair the problem to forestall it from occurring once more and interpolate or impute the lacking gaps, relying on the size of the hole;
- Gaps of data also can signify seasonal or repeated patterns. We might select to restructure our pipeline to start out amassing the lacking data or exchange the lacking gaps with exterior data from different distributed techniques. We will additionally determine if the method of retrieval was unsuccessful (possibly a fat-finger question on the info engineering facet, all of us have these days!).
I hope this tutorial has shed some gentle on the right way to determine and characterize lacking knowledge in your time-series knowledge appropriately and I can’t wait to see what you’ll discover in your personal hole evaluation! Drop me a line within the feedback for any questions or recommendations or discover me on the Knowledge-Centric AI Group!
Fabiana Clemente is cofounder and CDO of YData, combining knowledge understanding, causality, and privateness as her important fields of labor and analysis, with the mission of constructing knowledge actionable for organizations. As an enthusiastic knowledge practitioner she hosts the podcast When Machine Studying Meets Privateness and is a visitor speaker on the Datacast and Privateness Please podcasts. She additionally speaks at conferences comparable to ODSC and PyData.