

{kind=link}
Giant language fashions (LLMs) face a hurdle in dealing with lengthy contexts because of their constrained window size. Though the context window size could be prolonged by fine-tuning, this incurs important coaching and inference time prices, adversely affecting the LLM’s core capabilities.
Present LLMs, similar to Llama-1 and Llama-2, have mounted context lengths, hindering real-world purposes. Although fine-tuning can prolong context size, it’s going to lead to appreciable prices as a result of quadratic computing complexity of self-attention, impacting each coaching and inference. Steady coaching on lengthy sequences could compromise LLMs’ basic capabilities in shorter contexts. There’s a necessity for cost-effective mechanisms enabling context extension with out compromising present capabilities in pre-trained LLMs.
Researchers from the Beijing Academy of Synthetic Intelligence, Gaoling Faculty of Synthetic Intelligence, and Renmin College of China have proposed Activation Beacon. It leverages the concept LLM’s uncooked activations comprise redundant info, condensing them with minimal loss. This condensed type permits the LLM to know a broad context inside a brief window. Like sparse consideration and context compression, Activation Beacon successfully extends context high quality, helps numerous lengths, and ensures compatibility with present LLMs. Its technical designs improve coaching and inference effectivity, making it a promising resolution.
Utilizing particular tokens referred to as beacons, Activation Beacon achieves a condensing ratio (α) of L/ok (ok ≪ L), optimizing info consumption. The beacons make use of three consideration schemes, with stepwise growth proving the best. Beaconed Auto-Regression combines condensed and uncooked activations in sliding home windows, predicting the following token effectively. Beacon, a plug-and-play LLM module, is educated by auto-regression, guaranteeing minimal affect on short-context processing whereas introducing lengthy contextual info. Stepwise sampled condensing ratios improve coaching effectivity and generalize beacons for numerous context lengths.
Activation Beacon excels in long-context language modeling, surpassing Llama-2-7B and outperforming fine-tuning-free strategies. It progressively improves language modeling as context size extends from 4K to 32K, successfully using expanded info. In comparison with fine-tuned full-attention strategies, Activation Beacon achieves comparable or superior efficiency with considerably greater effectivity. The strategy maintains high quality era even at 100K and extends to 400K, marking a exceptional 100x improve over Llama-2-7B. In LongBench duties, Activation Beacon matches or surpasses fine-tuned baselines, showcasing its effectiveness in numerous real-world purposes with out compromising LLM’s authentic capabilities.
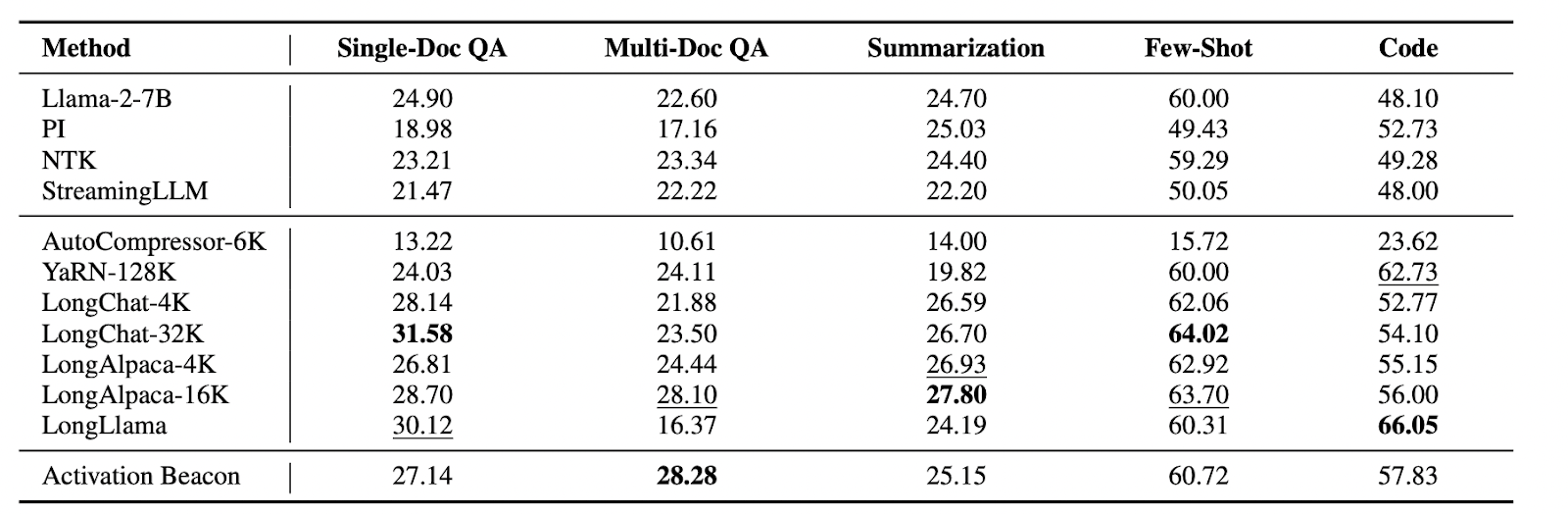
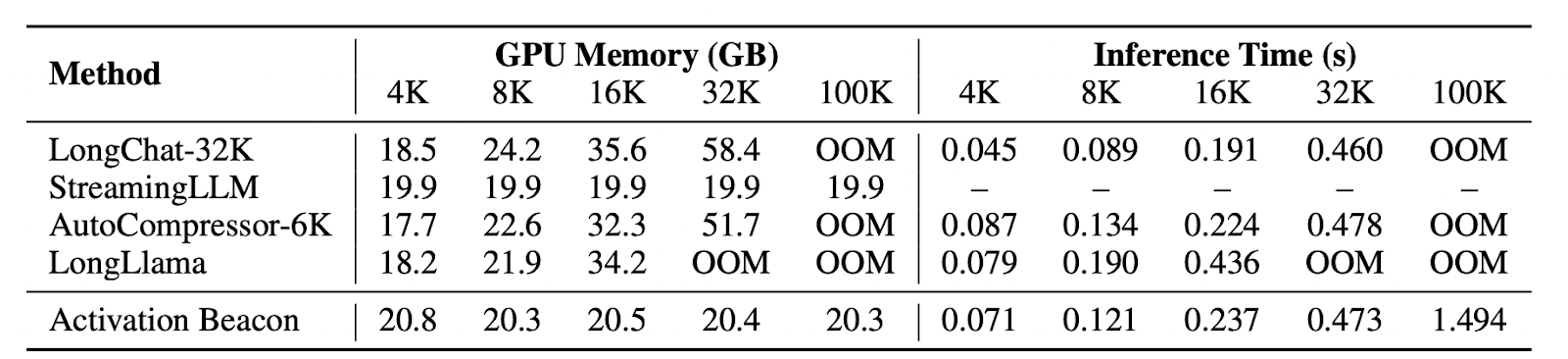
As a plug-and-play module, it introduces lengthy contextual info whereas preserving LLM’s short-context capabilities. Using sliding home windows for streaming processing enhances effectivity in each inference and coaching. Various condensing ratios, sampled throughout coaching, allow efficient assist for a broad vary of context lengths. Experimental outcomes affirm Activation Beacon is an efficient, environment friendly, and low-cost technique for extending LLM context size.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.