

{kind=link}
The seamless integration of imaginative and prescient and language has been a focus of current developments in AI. The sphere has seen vital progress with the appearance of LLMs. But, creating imaginative and prescient and vision-language basis fashions important for multimodal AGI techniques nonetheless have to catch up. This hole has led to the creation of a groundbreaking mannequin proposed by researchers from Nanjing College, OpenGVLab, Shanghai AI Laboratory, The College of HongKong, The Chinese language College of Hong Kong, Tsinghua College, College of Science and Expertise of China, SenseTime Analysis generally known as InternVL, which scales up imaginative and prescient basis fashions and aligns them for generic visual-linguistic duties.
InternVL addresses a crucial challenge within the realm of synthetic intelligence: the disparity within the growth tempo between imaginative and prescient basis fashions and LLMs. Current fashions typically use primary glue layers to align imaginative and prescient and language options, leading to a mismatch in parameter scales and illustration consistency. This inadequacy can hinder the complete potential of LLMs.
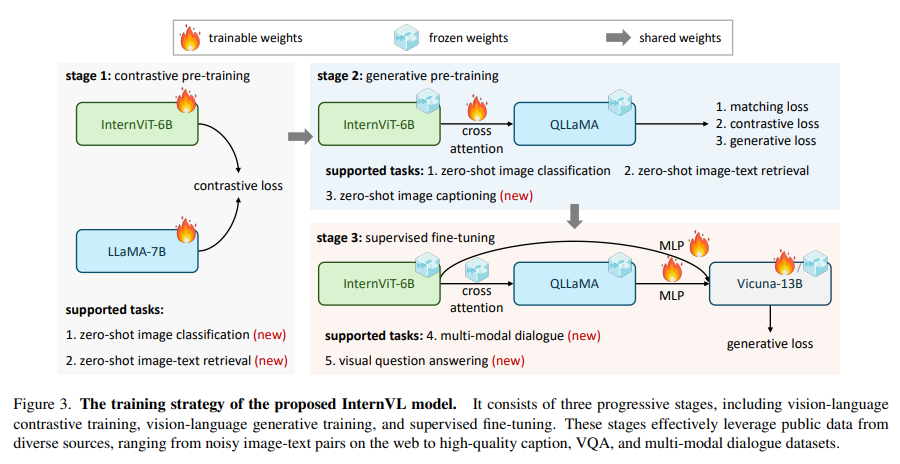
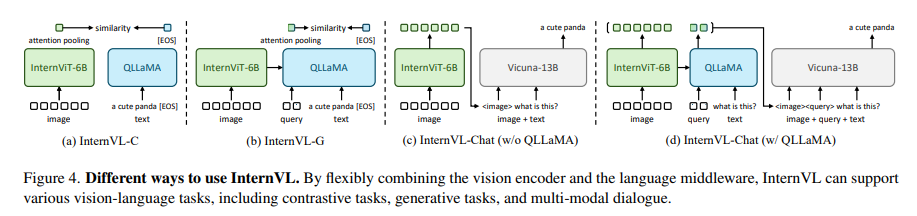
The methodology behind InternVL is each distinctive and sturdy. The mannequin employs a large-scale imaginative and prescient encoder, InternViT-6B, and a language middleware, QLLaMA, with 8 billion parameters. This construction serves a twin function: it features as an impartial imaginative and prescient encoder for notion duties. It collaborates with the language middleware for complicated vision-language duties and multimodal dialogue techniques. The mannequin’s coaching entails a progressive alignment technique, beginning with contrastive studying on intensive noisy image-text information after which shifting to generative studying with extra refined information. This progressive method constantly improves the mannequin’s efficiency throughout varied duties.
InternVL demonstrates its prowess by outperforming current strategies in 32 generic visual-linguistic benchmarks, a testomony to its sturdy visible capabilities. The mannequin excels in numerous duties comparable to picture and video classification, picture and video-text retrieval, picture captioning, seen query answering, and multimodal dialogue. This numerous vary of capabilities is attributed to the aligned characteristic house with LLMs, enabling the mannequin to deal with complicated duties with exceptional effectivity and accuracy.
Key facets of InternVL’s efficiency embody:
- The mannequin is flexible as a standalone imaginative and prescient encoder or mixed with the language middleware for varied duties.
- InternVL innovatively overcomes this by scaling the imaginative and prescient basis mannequin to a exceptional 6 billion parameters, facilitating a extra complete and efficient integration with LLMs.
- Its capability to attain state-of-the-art efficiency throughout 32 generic visual-linguistic benchmarks highlights its superior visible capabilities.
- Efficient efficiency in picture and video classification, picture and video-text retrieval, picture captioning, visible query answering, and multimodal dialogue.
- The aligned characteristic house with LLMs enhances its capability to seamlessly combine with current language fashions, additional broadening its software scope.
In conclusion, the analysis performed may be offered in a nutshell within the following factors:
- InternVL represents a significant leap in multimodal AGI techniques, bridging a vital hole in creating imaginative and prescient and vision-language basis fashions.
- Its modern scaling and alignment technique endow it with versatility and energy, enabling superior efficiency throughout varied visual-linguistic duties.
- This analysis contributes to advancing multimodal massive fashions, doubtlessly reshaping the long run panorama of AI and machine studying.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to hitch our 35k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and Electronic mail E-newsletter, the place we share the newest AI analysis information, cool AI initiatives, and extra.
If you happen to like our work, you’ll love our e-newsletter..
Howdy, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m captivated with expertise and need to create new merchandise that make a distinction.