

{kind=link}
Multimodal Massive Language Fashions (MLLMs) are pivotal in integrating visible and linguistic parts. These fashions, basic to creating refined AI optical assistants, excel in deciphering and synthesizing data from textual content and imagery. Their evolution marks a major stride in AI’s capabilities, bridging the hole between visible notion and language comprehension. The worth of those fashions lies of their capability to course of and perceive multimodal information, an important facet of AI functions in numerous fields like robotics, automated programs, and clever information evaluation.
A central problem on this area is the necessity for present MLLMs to realize detailed vision-language alignment, notably on the pixel degree. Most current fashions are proficient in deciphering pictures at a broader, extra basic degree, utilizing image-level or box-level understanding. Whereas efficient for general picture comprehension, this method wants to enhance in duties that demand a extra granular, detailed evaluation of particular picture areas. This hole in functionality limits the fashions’ utility in functions requiring intricate and exact picture understanding, resembling medical imaging evaluation, detailed object recognition, and superior visible information interpretation.
The prevalent methodologies in MLLMs usually contain utilizing image-text pairs for vision-language alignment. This method is well-suited for basic picture understanding duties however wants extra finesse for region-specific evaluation. In consequence, whereas these fashions can successfully interpret the general content material of a picture, they need assistance with extra nuanced duties resembling detailed area classification, particular object captioning, or in-depth reasoning primarily based on explicit areas inside a picture. This limitation underscores the need for extra superior fashions able to dissecting and understanding pictures at a a lot finer degree.
Researchers from Zhejiang College, Ant Group, Microsoft, and The Hong Kong Polytechnic College have developed Osprey, an modern method designed to reinforce MLLMs by incorporating pixel-level instruction tuning to deal with this problem. This methodology goals to realize an in depth, pixel-wise visible understanding. Osprey’s method is groundbreaking, enabling a deeper, extra nuanced understanding of pictures and permitting for exact evaluation and interpretation of particular picture areas on the pixel degree.
On the core of Osprey is the convolutional CLIP spine, used as its imaginative and prescient encoder, together with a mask-aware visible extractor. This mix is a key innovation, permitting Osprey to seize and interpret visible masks options from high-resolution inputs precisely. The mask-aware optical extractor can discern and analyze particular areas inside a picture with excessive precision, enabling the mannequin to grasp and describe these areas intimately. This characteristic makes Osprey notably adept at duties requiring fine-grained picture evaluation, resembling detailed object description and high-resolution picture interpretation.
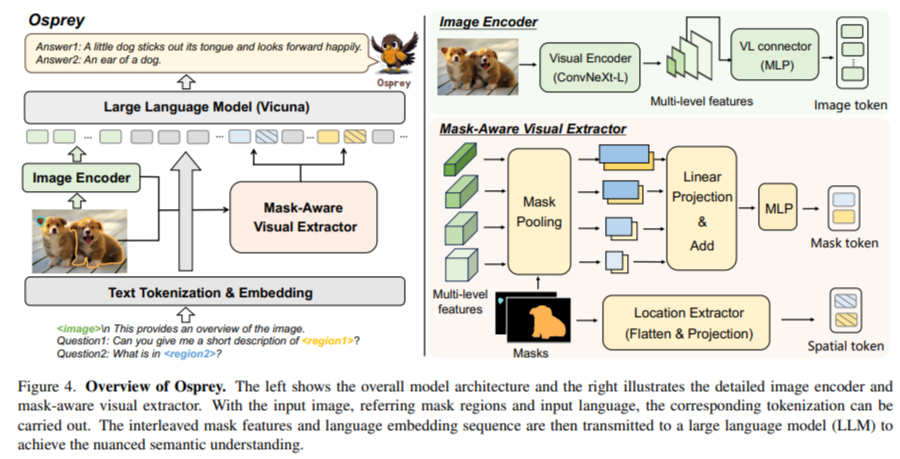
Osprey has demonstrated distinctive efficiency and understanding of duties throughout numerous areas. Its capability to excel in open-vocabulary recognition, referring object classification, and detailed area description is especially noteworthy. The mannequin showcases its functionality to provide fine-grained semantic outputs primarily based on class-agnostic masks. This functionality signifies Osprey’s superior proficiency in detailed picture evaluation, surpassing current fashions’ capability to interpret and describe particular picture areas with outstanding accuracy and depth.

In conclusion, the analysis could be summarized within the following factors:
- The event of Osprey is a landmark achievement within the MLLM panorama, notably addressing the problem of pixel-level picture understanding.
- The mixing of mask-text instruction tuning with a convolutional CLIP spine in Osprey represents a major technological innovation, enhancing the mannequin’s capability to course of and interpret detailed visible data precisely.
- Osprey’s adeptness in dealing with duties requiring intricate visible comprehension marks an important development in AI’s capability to have interaction with and interpret advanced visible information, paving the best way for brand spanking new functions and developments within the area.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to affix our 35k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and E-mail Publication, the place we share the newest AI analysis information, cool AI initiatives, and extra.
In the event you like our work, you’ll love our publication..
Good day, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at the moment pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m obsessed with expertise and need to create new merchandise that make a distinction.