
{kind=link}

Picture by Editor
The MLOps market was estimated at $23.2billion in 2019 and is projected to achieve $126 billion by 2025 attributable to speedy adoption.
Many information science tasks don’t see the sunshine of the day. MLOps is a course of that spans from the info stage to deployment stage and ensures the success of machine studying fashions. On this publish, you’ll find out about the important thing levels in MLOps (from a knowledge scientist’s perspective) together with some widespread pitfalls.
MLOps is a observe that focuses on operationalizing information science fashions. Normally, in most enterprises, information scientists are answerable for creating the modeling datasets, pre-processing the info, characteristic engineering, and at last constructing the mannequin. Then the mannequin is “thrown” over the wall to the engineering workforce to be deployed into the API/Endpoint. The science and engineering usually instances occur in silos, which ends up in delays in deployment or incorrect deployments within the worst case.
MLOps addresses the problem of deploying enterprise scale ML fashions precisely and rapidly.
The information science equal of the saying “Simpler mentioned than achieved” ought to most likely be “Simpler constructed than deployed”.
MLOps may be the silver bullet to the difficulties enterprises face placing machine studying fashions into manufacturing. For these of us information scientists, the discovering that ~90% of ML fashions don’t make it to manufacturing, shouldn’t come as a shock. MLOps brings the self-discipline and course of to the info science and engineering groups to make sure that they collaborate intently and repeatedly. This collaboration is essential to make sure profitable mannequin deployment.
For these acquainted with DevOps, MLOps is to machine studying purposes that DevOps is to software program purposes.
MLOps is available in a number of flavors relying on who you ask. Nonetheless, there are a 5 key levels which can be crucial to a profitable MLOps technique. As a facet be aware, a vital ingredient that must be part of every of those levels is communication with stakeholders.
Downside framing
Perceive the enterprise drawback inside out. This is without doubt one of the key steps to profitable mannequin deployment and utilization. Interact with all of the stakeholders at this stage to get buy-in for the challenge. It might be engineering, product, compliance and many others.
Resolution framing
Solely and Solely after the issue assertion is hashed out, proceed to fascinated about the “How”. Is machine studying required to sort out this enterprise drawback? On the onset, it may appear bizarre that as a knowledge scientist, I’m suggesting to steer away from machine studying. That’s solely as a result of with “nice energy comes nice duty”. Duty on this case could be to ensure that the machine studying mannequin is constructed, deployed and monitored fastidiously to make sure that it satisfies and continues to fulfill the enterprise requirement. The timelines and assets also needs to be mentioned at this stage with the stakeholders.
Knowledge preparation
Upon getting determined to go down the route of machine studying, begin pondering of the “Knowledge”. This stage contains steps akin to information gathering, information cleansing, information transformation, characteristic engineering and labeling (for supervised studying). Right here the adage that must be remembered is “rubbish in rubbish out”. This step is often probably the most painstaking step within the course of and is crucial to make sure mannequin success. Guarantee to validate the info and options a number of instances to ensure that they’re aligned with the enterprise drawback. Doc all of your many assumptions that you just take whereas making a dataset. Ex: Are the outliers for a characteristic really outliers?
Mannequin constructing and evaluation
On this stage, construct and consider a number of fashions and choose the mannequin structure that greatest solves the issue at hand. The chosen metric for optimization ought to replicate the enterprise requirement. Right this moment, there are quite a few machine studying libraries that assist expedite this step. Keep in mind to log and observe your experiments to make sure reproducibility of your machine studying pipeline.
Mannequin serving and monitoring
As soon as we’ve the mannequin object constructed from the earlier stage, we have to consider how we’re going to make it “useable” by our end-users. Response latency must be minimized whereas maximizing throughput. Some common choices to serve the mannequin are – REST API endpoint, as a docker container on the cloud or on an edge system. We are able to’t but rejoice as soon as we’ve deployed the mannequin object, as they’re very dynamic in nature. For instance, the info may drift in manufacturing inflicting mannequin decay or there might be adversarial assaults on the mannequin. We have to have a sturdy monitoring infrastructure in place for the machine studying software. Two issues have to be monitored right here:
- The well being of the surroundings the place we deploy (eg: load, utilization, latency)
- The well being of the mannequin itself (eg: efficiency metrics, output distribution).
The cadence of the monitoring course of additionally must be decided at this stage. Are you going to observe your ML software day by day, weekly or month-to-month?
Now, you’ve got a sturdy machine studying software constructed, deployed and monitored. However alas, the wheel doesn’t cease spinning, because the above steps have to be iterated upon repeatedly.
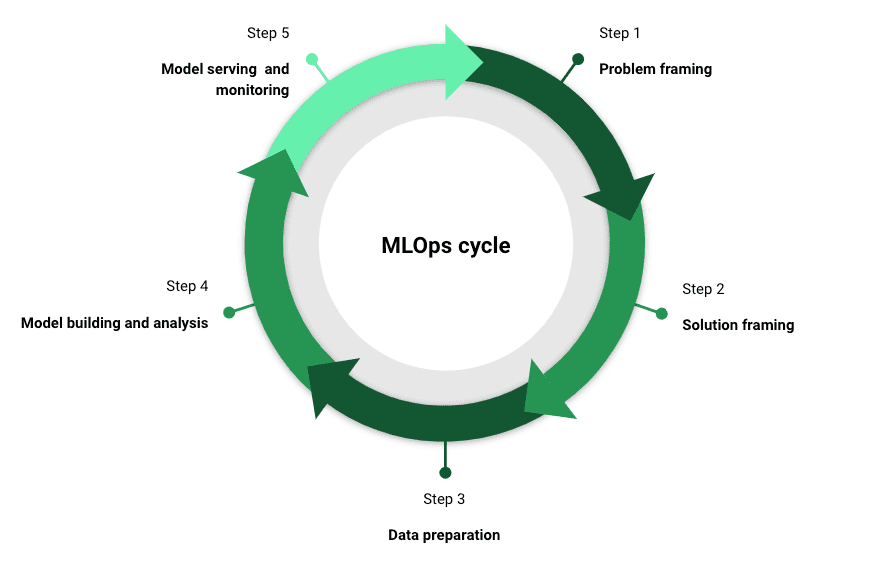
MLOps cycle for profitable information science tasks | Picture by Writer
To place the above 5 levels in observe, let’s assume for this part that you’re a information scientist at a FinTech firm answerable for deploying a fraud mannequin to detect fraudulent transactions.
On this case, begin with a deep dive into the kind of fraud (first celebration or third celebration?) you are attempting to detect. How are transactions recognized as fraud or not? Are they reported by the tip person or do it’s a must to use heuristics to determine fraud? Who could be consuming the mannequin? Is it going for use in actual time or in batch mode? Solutions to the above questions are essential to fixing this enterprise drawback.
Subsequent, take into consideration what answer greatest addresses this drawback. Do you want machine studying to deal with this or are you able to begin with a easy heuristic to sort out fraud? Is all of the fraud coming from a small set of IP addresses?
For those who determine to construct a machine studying mannequin (assume supervised studying for this case), you have to labels and options. How will you deal with lacking variables? What about outliers? What’s the statement window for fraud labels? i.e how lengthy does it take for a person to report a fraud transaction? Is there a knowledge warehouse you need to use to construct options? Be sure that to validate the info and options earlier than shifting forward. That is additionally a superb time to have interaction with the stakeholders in regards to the course of the challenge.
Upon getting the info wanted, construct the mannequin and carry out the mandatory evaluation. Be sure that the mannequin metric is aligned with the enterprise utilization. (eg: might be recall on the first decile for this use-case). Does the chosen mannequin algorithm fulfill the latency requirement?
Lastly, coordinate with engineering to deploy and serve the mannequin. As a result of fraud detection is a really dynamic surroundings, the place fraudsters attempt to remain forward of the system, monitoring may be very essential. Have a monitoring plan for each the info and the mannequin. Measures such because the PSI (inhabitants stability index) are widespread to maintain observe of information drift. How usually will you retrain the mannequin?
Now you can efficiently create enterprise worth by decreasing fraudulent transactions utilizing machine studying (if wanted!).
Hope that after studying this text, you see the advantages of implementing MLOps at your agency. To summarize, MLOps ensures that the info science workforce is:
- fixing the precise enterprise drawback
- utilizing the precise software to unravel the issue
- leveraging the dataset that represents the issue
- constructing the optimum machine studying mannequin
- and at last deploying and monitoring the mannequin to make sure continued success
Nonetheless, be conscious of the widespread pitfalls to make sure that your information science challenge doesn’t change into a tombstone within the information science graveyard! The truth that a knowledge science software is a dwelling and respiratory factor must be remembered. The information and mannequin have to be repeatedly monitored. AI governance must be thought of proper from the start and never as an afterthought.
With these ideas in thoughts, I’m assured you can really create enterprise worth leveraging machine studying (if wanted!).
MLOps References
Natesh Babu Arunachalam is a knowledge science chief at Mastercard, at present targeted on constructing progressive AI purposes utilizing open banking information.